大模型安全难掌控?基于 Azure 结合 NeMo Guardrails 构建 LLM 可编程护栏
大模型安全难掌控?基于 Azure 结合 NeMo Guardrails 构建 LLM 可编程护栏大语言模型 LLM 是功能强大的工具,企业和开发者都在探索 LLM 的落地应用,但在实际使用过程中也存在着大量的风险。用户可能会接触到 LLM 生成的不当、有害和有偏见的内容,甚至是危险信息,存在安全隐患。
智能技术如何为 LLM 应用戴上安全“护栏”?NVIDIA NeMo Guardrails 是一个开源工具库,致力于使 LLM 大语言模型的使用更加合法合规。它可以轻松将可编程护栏添加到基于 LLM 的对话系统中,控制大型语言模型输出的特定方式,例如不谈论违规内客、以特定方式响应特定用户请求、遵循预定义的对话路径、使用特定语言风格、提取结构化数据等。NeMo Guardrails 的核心价值是能够编写防护围栏来指导对话,定义 LLM 驱动的机器人在某些主题上的行为,构建值得信赖、安全可靠的 LLM 对话系统。
✦ 话题限定护栏 (topical guardrails):防止大模型“跑题”;
✦ 对话安全护栏 (safety guardrails):避免大模型输出时“胡言乱语”;
✦ 攻击防御护栏 (security guardrails):防止 AI 平台收到恶意攻击。
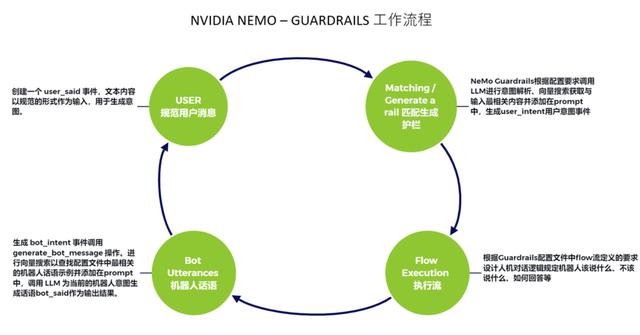
想了解更多 NeMo Guardrails 与 Azure OpenAI 的结合使用的操作指南和干货知识,点击「链接」,就可以回看【比特熊充电栈】学习实践。
关于作者

猜你喜欢