本文约2000字,建议阅读9分钟
本文为你提供使用ChatGPT优化提示的知识和技巧。
作为一个大型语言模型(LLM)接口,ChatGPT有令人印象深刻的潜力,但是真正能否用好取决与我们的提示(Prompt ),一个好的提示可以让ChatGPT晋升到一个更好的层次。
在这篇文章中,我们将介绍关于提示的一些高级知识。无论是将ChatGPT用于客户服务、内容创建,还是仅仅为了好玩,本文都将为你提供使用ChatGPT优化提示的知识和技巧。

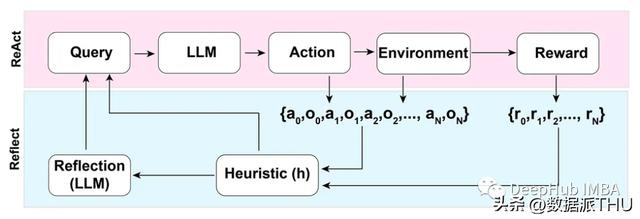
4. ReAct
ReAct (Reason Act)方法包括结合推理跟踪和特定于任务的动作。
推理跟踪帮助模型规划和处理异常,而动作允许它从外部来源(如知识库或环境)收集信息。

5. Reflection
在ReAct模式的基础上,Reflection方法通过添加动态内存和自反射功能来增强LLM——可以推理和特定于任务的操作选择能力。
为了实现完全自动化,Reflection论文的作者引入了一种简单但有效的启发式方法,允许代理识别幻像(hallucinations),防止重复动作,并在某些情况下创建环境的内部记忆图。
在一般意义上,提示注入(目标劫持)和提示泄漏可以描述为:

所以对于一个LLM模型,也要像数据库防止SQL注入一样,创建防御性提示符来过滤不良提示符。
为了防止这个问题,我们可以使用一个经典的方法 “Sandwich Defense”即将用户的输入与提示目标“夹在”一起。

这样的话无论提示是什么,最后都会将我们指定的目标发送给LLM。
总结ChatGPT响应是不确定的——这意味着即使对于相同的提示,模型也可以在不同的运行中返回不同的响应。如果你使用API甚至提供API服务的话就更是这样了,所以希望本文的介绍能够给你一些思路。
另外本文的引用如下:
Prompt injection attacks against GPT-3
https://simonwillison.net/2022/Sep/12/prompt-injection/
Ignore Previous Prompt: Attack Techniques For Language Models
https://arxiv.org/abs/2211.09527
Self-ask Prompting
https://ofir.io/Self-ask-prompting/
Large Language Models are Zero-Shot Reasoners
https://arxiv.org/abs/2205.11916
Reflexion: an autonomous agent with dynamic memory and self-reflection
https://arxiv.org/abs/2303.11366
ReAct: Synergizing Reasoning and Acting in Language Models
https://arxiv.org/abs/2210.03629
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://arxiv.org/abs/2201.11903
作者:Ivan Campos
MORE
相关文章








关于作者

猜你喜欢























