 少样本学习无需微调,以后都不能自黑「调参侠」了
少样本学习无需微调,以后都不能自黑「调参侠」了GPT-3基于 CommonCrawl (从2016年到2019年收集了近1万亿个单词)、网络文本、书籍、维基百科等相关的数据集进行训练。
GPT-3的参数量高达1750亿,相比之下,GPT-2的最大版本也只有15亿个参数,而微软早前推出的全球最大的基于Transformer的语言模型有170亿个参数。
GPT-3模型在一系列基准测试和特定领域的自然语言处理任务(从语言翻译到生成新闻)中达到最新的SOTA结果。
GPT-3只是参数量巨大吗?
此次发布的GPT-3还是沿用了之前的单向transformer,我们看题目,这次的模型是少样本学习语言模型,不管是Zero-shot、One-shot还是Few-shot都无需再进行微调,但推理速度还有待验证。
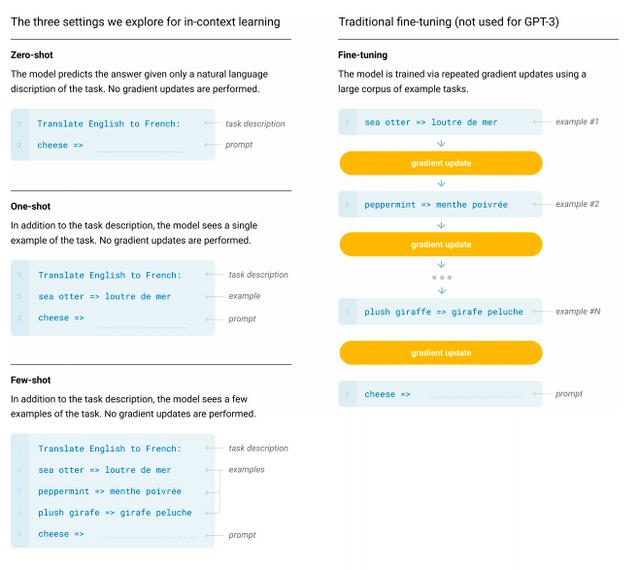
接下来作者们对下游的各种NLP任务进行了实验,想要了解更多细节的朋友可以去arXiv上查看原始论文。
https://arxiv.org/pdf/2005.14165.pdf
OpenAI这次不光拼参数量,还要拼作者数量?这次的GPT-3论文作者足足有31位,现在语言模型不仅要拼参数量,还要拼作者数量吗?
GPT-3直接被打上了炫富的标签。

GPT2生成的虚假文章已经让人真假难辨,至少在语句的通顺性上是这样。GPT-3的效果将更胜GPT2,有网友也表示我们将会败给GPT-3,如果以后网页的内容都是自动生成的,那阅读还有什么意义?

OpenAI 去年发布了 GPT-2,因为担心该模型可能被恶意使用,并没有放出预训练的模型。有些网友评论说应该改名Closeai,但是OpenAI这种审慎的做法也有不少人赞同。网友们也关心 GPT-3的完整版本是否会开源,或者是否会有7个规模从1.25亿到130亿不等的小版本时,OpenAI没有给予明确答复。
参考链接:
相关文章








关于作者

猜你喜欢























