萧箫 发自 凹非寺量子位 报道 | 公众号 QbitAI
虽然GPT-3没有开源,却已经有人在复刻GPT系列的模型了。
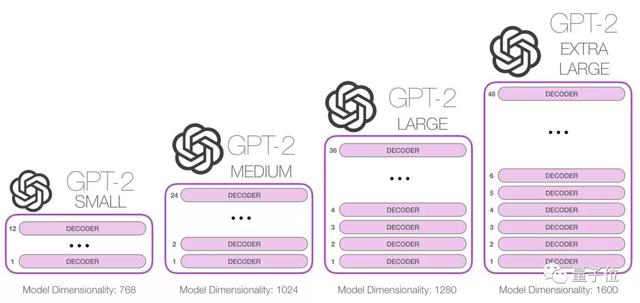
例如,慕尼黑工业大学的Connor Leahy,此前用200个小时、6000RMB,复现了GPT-2。

作者们打算尝试各种结构和注意力类型,最终扩展出GPT-3大小的大语言模型。
为了实现这一目标,他们从复现GPT系列的模型开始,不断尝试各种模型架构、和各种注意力机制的实现方式。
……
这个项目还在施工中,不过,连模型的训练方式都准备好了。
项目计划通过TPU或GPU,对大语言模型进行训练。
为此,作者们已经基于Tensorflow-mesh(用于在GPU上训练模型)、Deepspeed(用于在TPU上训练模型)两个项目,编写了GPT-Neo的训练代码。
这两个项目都可以扩展到大于GPT-3的大小,甚至还能更大。
 如何训练GPT-Neo
如何训练GPT-Neo当然,在TPU和GPU上训练的方式有所不同。
如果使用TPU训练的话,需要注册一个谷歌云平台,创建存储空间,然后再搞个虚拟机,将模型放到TPU上训练。

训练过程也不复杂,主要包括创建分词器、数据集预处理、指定训练数据集、选择训练配置、训练模型几个步骤。
在创建分词器上,GPT-Neo目前提供一个Huggingface的预训练GPT-2分词器。不过,也可以训练自己专属的分词器。
然后,对数据进行预处理,可以直接下载项目提供的数据,也可以使用自己的数据集。
在那之后,指定模型训练所用的数据集,然后对训练方式进行设置,例如优化算法、训练步数等。

目前,GPT-Neo的所有项目和代码已开源。
想要上手一试、或是对项目感兴趣的小伙伴,可以行动起来了~
项目地址:https://github.com/EleutherAI/gpt-neo
参考链接:https://www.eleuther.ai/gpt-neohttps://news.ycombinator.com/item?id=25819803
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢























