杨净 箫萧 发自 凹非寺量子位 报道 | 公众号 QbitAI
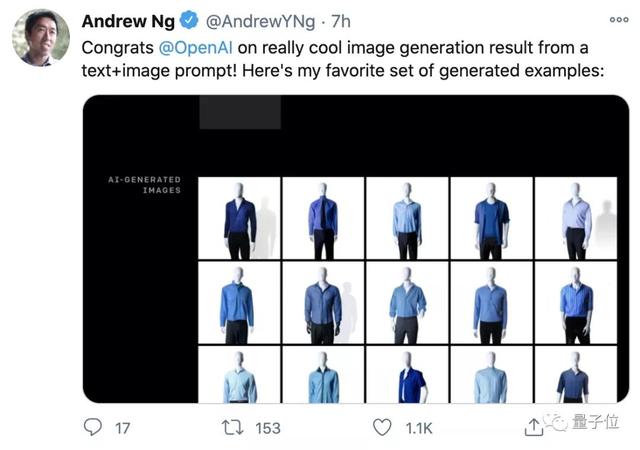
2021年一开始,OpenAI在GPT-3方向上的又一重要突破,让吴恩达等大佬激动了。
之前给GPT-3一段话,就能写出一段小说。
现在它成功跨界——可以按照文字描述、生成对应图片!

从“五边形闹钟”到“牛油果形状的座椅”,只要你的想象力够丰富,DALL·E全都能画出来。

技术上更厉害的是,OpenAI透露这个AI是基于GPT-3而构建,仅使用了120亿个参数样本,相当于GPT-3参数量的十四分之一。
于是效果一出,吴恩达、Keras之父等纷纷转发、点赞。堪称2021年第一个令人兴奋的AI技术突破。
DALL·E将对这些输入信息进行建模,利用自注意力层的注意力遮罩,确保每一个输入的图像字符,都与所有输入的文字字符关联。
然后DALL·E将根据文本,通过最大似然估计,逐个字符生成图像。它不仅能从文字中,生成一整幅草图,还能重新生成图像中的任何一块矩形区域。

此外,CLIP还能“身兼多职”,在各种数据集上的表现都很好(包括没见过的数据集)。但此前的大部分视觉神经网络,只能在训练的数据集上有不错的表现。
例如,CLIP与ResNet101相比,在各项数据集上都有不错的检测精度,然而ResNet101在除了ImageNet以外的检测精度上,表现都不太好。

具体来说,CLIP用到了零样本学习(zero-shot learning)、自然语言理解和多模态学习等技术,来完成图像的理解。

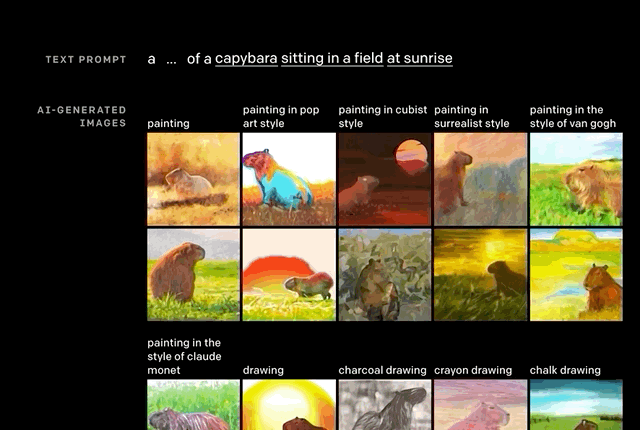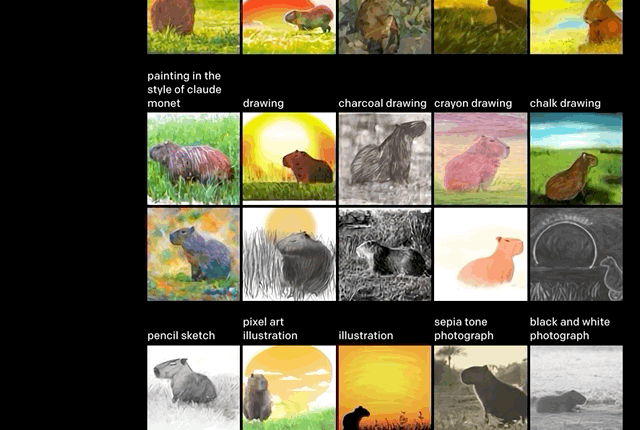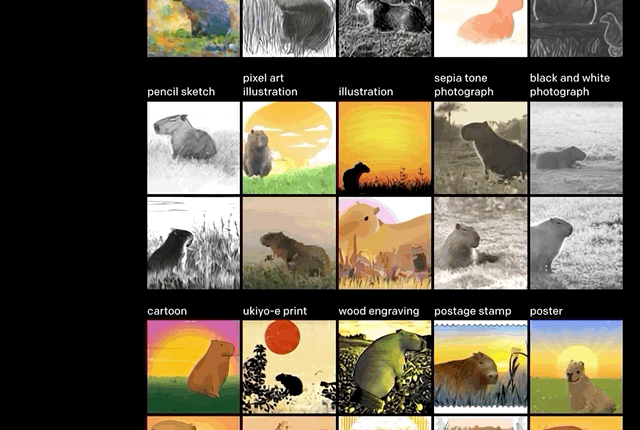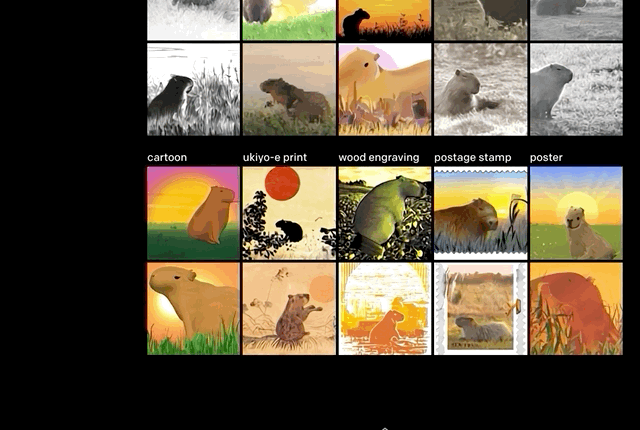
推断细节。正如上文举的例子,“沐浴在朝阳中的田间水豚”。
单从文字上看,还有很多细节需要考究:水豚位置,阴影有无,绘画风格。但这些,似乎都没有难到DALL·E。
英伟达的机器学习专家Ming-Yu Liu,也送上了自己的祝福。
他表示,这样的模型在文本转图像的能力上,简直超乎想象。

当然,也有对这种方法的限制感到困惑的学者。
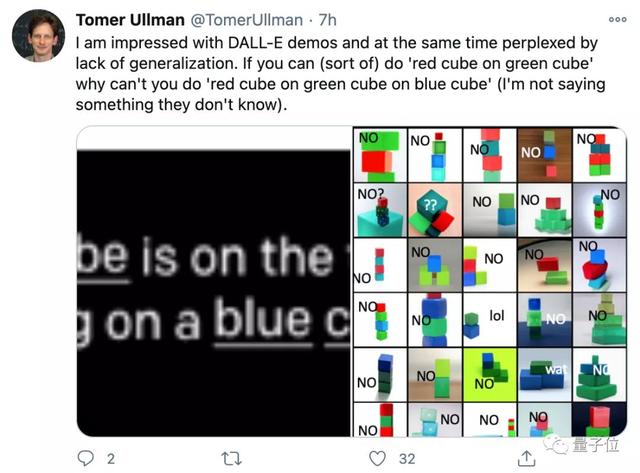
来自哈佛的助理教授Tomer Ullman,在对DALL·E的能力表示惊叹时,也提出了对于模型泛化能力限制的疑惑。
他认为,如果能生成“绿方块上的红方块”,模型理应也能生成“蓝方块上的绿方块上的红方块”?
希望这样的模型,能在提升泛化等能力后,真正被用来减轻设计师们的负担。
当然,如果再开一开脑洞的话,应用前景可能不止于减轻负担。
如果效果足够好,还要什么乙方设计师?
以及像动画、影视等领域,是不是未来剧本一放,AI就能给你出成果了?
参考链接:https://openai.com/blog/dall-e/https://openai.com/blog/clip/https://twitter.com/fchollet/status/1346558591835070464https://twitter.com/gdb/status/1346554999241809920https://twitter.com/liu_mingyu/status/1346573218270724097https://twitter.com/TomerUllman/status/1346556192907255808
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢























