内容审核一直被视为互联网大厂中的脏活和累活。就拿审文章来说,审核员们一天要审约2000篇文章,7×24h工作制,经常过着昼夜颠倒的日子,更要命的是,他们每天都要接收各种低俗污秽内容,久而久之,心理也承受着相当大的压力。没有点体力和强大的心脏,这行还真干不了。
别看内容审核员承担着繁重的“内容清洁”的工作,但由于简单重复等工作特性,他们往往是大厂的“边缘人”,而且薪酬也较其他岗位低很多。AI火了之后,不少人认为,要想解救被困在大厂精算系统里的审核员,还得看人工智能。没想到,这一天这么快就到来了。
8月15日,OpenAI在官网称,其开发了一种使用GPT-4进行内容审核的解决方案,从而实现更一致的标记、更快的策略优化反馈循环,以及减少人工审核人员的参与。

使用 GPT-4 构建内容审核系统,可以将内容审核工作从六个月缩短到几小时(这里的六个月其实包括了审核人员培训的时间),具体的迭代过程是:
1. 内容审核政策指南编写完成后,政策专家可以通过识别少量的示例并根据政策为其分配标签来创建一个黄金数据集。
2. GPT-4阅读内容政策并为相同的数据集分配标签,而不需要答案。
3. 通过检查GPT-4的判断与人类的判断之间的差异,政策专家可以要求GPT-4提出其标签背后的推理,分析政策定义中的歧义,解决混淆并相应地提供进一步的澄清。我们可以重复步骤2和3,直到对政策质量感到满意。
4. 通过迭代这个过程,可以把内容审核政策转化为分类器,进而实现审核系统的部署和内容管理。如果有必要的话,甚至可以使用GPT-4的结果来微调小模型。
官方给出了一个审核政策的例子,K Illicit Behaviour Taxonomy(K分类法):在未干预的情况下,GPT-4 默认给出了 K0 的分类:

在更新审核政策并重新要求分类后,GPT-4 给出了和人类审核一样的 K3 分类:

通过这样的迭代过程,内容审核系统可以很快地适应新的内容审核策略,进而与内容审核要求相一致。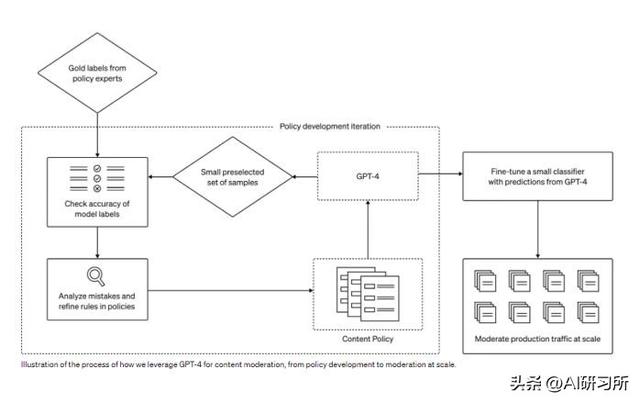
不过,从测试结果来看,强如 GPT-4,在内容审核方面也暂时无法超越经验丰富的人工审核的准确度(不过在一些场景下,可以超过新手的表现):
用人工智能进行内容审核,这个简单而强大的想法为传统的内容审核方法提供了一些改进:
首先是更加一致的标注。由于内容政策在不断发展,条例变得越来越多。就像有一千个读者就有一千个哈姆雷特那样,人们对这些繁杂条例的理解也会有偏差。同时,因为人类还需要一定的时间来熟悉新的政策变化,这也会让内容的标注不一致。相比之下,像GPT-4这样的LLM对内容措辞的细微差异非常敏感,可以做到实时更新,为用户提供一致的内容体验。
第二是更快的反馈循环。政策更新的周期是一个非常漫长的过程。从制定新政策、标记到收集人工反馈,传统的人工审核要完成这一流程可能会花费数周、甚至数月。在内容政策更新比较频繁的时候,人工审核可能还没有完成上次的更新的内容,就得面对新的更新了......
但GPT-4 可以将这一过程缩短到几个小时。不仅大大减小了人工审核的滞后性,还能更快地应对新的危害漏洞。
最后一个好处是减轻人类的心理负担。持续接触有害或冒犯性的内容会导致人类审核员产生情感麻木以及心理压力。内容审核员面临着极高的各类精神疾病风险,同时三班倒工作时间和低微的薪水与没有上升空间的职业道路,让担任内容审核的人类自嘲自己和「机器」一样。如果让真正的机器来担任这类工作,将有利于相关人员的福祉,毕竟我们应该不太用担心,大量接触不良信息会让GPT模型心理崩溃。
GPT-4的标记质量类似于经过轻度训练的人工版主(B 组)。不过,两者都被经验丰富、训练有素的人类主持人(A 组)超越了
跟Constitutional AI(依赖于模型自己判断是否安全)相比,OpenAI的这个方法可以让基于平台的特定内容政策迭代更快、更省力。
OpenAI表示鼓励安全从业者都尝试这个过程进行审核,只要有OpenAI的API访问权限就行。OpenAI还在尝试通过结合思维链推理或者自我批评,来提高GPT-4的预测质量。另外他们也在尝试检测未知风险的方法,以及利用模型来识别潜在的有害内容,并对其进行高级的描述(也是受ConstitutionalAI)的启发。这些发现也会为全新的风险政策提供信息。
当然,GPT-4也会在训练期间出现偏差,这个过程中还需要人类来监控、验证和完善。而节省的人力,可以用来专注于解决政策需要最需要的复杂边缘情况。
相关文章








关于作者

猜你喜欢























