编辑:编辑部
【新智元导读】GPT-4又出业内爆料了!参数、架构、训练数据集、token、训练和推理成本……一次爆了个全。而鉴于作者此前的战绩,这份爆料确实具有一定的参考价值。就在刚刚,OpenAI的GPT-4又被业内人士「开源」了!
其中包括GPT-4的架构、训练和推理的基础设施、参数量、训练数据集、token数、成本、混合专家模型(Mixture of Experts,MoE)等非常具体的参数和信息。

出门问问CEO李志飞对此也发表了感言
很多企业都能做出GPT-4
在爆料文章作者看来,OpenAI之所以不open,不是为了确保人类不被AI毁灭,而是因为他们构建的东西是可复制的。
他甚至预计,未来所有中国和美国的互联网大厂或者AI头部初创企业,都会有能力构建出和GPT-4一样,甚至是超过GPT-4的模型。
但他同时也承认,GPT-4是OpenAI的伟大杰作。它凝结了工程师的匠心设计,复杂的构架和各种巧妙的工程上的取舍。

此图表假设,无法融合每个操作、注意力机制所需的内存带宽、硬件开销相当于参数读取,都会导致效率低下。实际上,即使使用优化的库,比如英伟达的FasterTransformrmer库,总开销甚至还会更大
爆料作者怀疑,如果这种集群实际上是一群具有较弱网络连接的较小集群构成的,那么集群不同部分之间的非阻断(non-block)连接速度为800G/1.6T,但这些部分之间的连接速度仅为200G/400G。
如果OpenAI云计算的成本是差不多1美元/每A100小时的话,那么在这样的条件下,训练成本大约是6300万美元。
这还不包括所有的实验、失败的训练和其他成本,比如数据收集、RLHF、人力成本等。
如果考虑到刚刚说的这些因素,真实成本要高得多的多。
此外,这还得是在能别人买得到芯片/网络/数据中心,承担资本支出组建了这些系统,并将它们租给OpenAI的前提下。
但是放到今天,在2美元/每H100小时的条件下,预训练可以在大约8,192个H100上进行,只需要55天,费用为2150万美元。

对此作者假设,OpenAI会在低峰时段关闭集群,重新配置节点,恢复训练较小的测试模型,并尝试各种新技术,从而降低推理成本。
如果OpenAI不这样做,他们的利用率会更低,而成本也将增加一倍以上。
多查询注意力
除此之外,OpenAI也在使用多查询注意力(Multi-Query Attention,MQA)。

论文地址:https://arxiv.org/pdf/1911.02150.pdf
简而言之,只需要一个注意力头,并且可以显著减少KV缓存的内存占用。
即便如此,32k长度的GPT-4肯定无法在40GB的A100上运行,而8k的最大批大小也有上限。
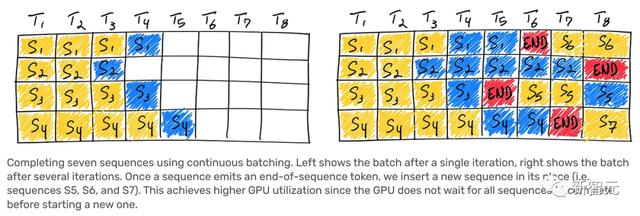
连续批处理
OpenAI实现了可变批大小和连续批处理。
这样做可以允许一定程度的最大延迟,并优化推理成本。

推测解码(Speculative decoding)
爆料称,OpenAI在GPT-4的推理过程中使用了「推测解码」,这其中还有100%的不确定性。
token到token的延迟变化,以及在进行简单的检索任务和更复杂的任务时差异,似乎表明这一点是可能的,不过还是有太多的变量无法确定。
在此,爆料者通过DeepMind的一项研究「Accelerating LLM Inference with Staged Speculative Decoding」中的文本,进行了适当修改/添加一些细节,进行了解释。

使用LLM通常分为两个阶段。
首先是预填充(prefill),将提示文本输入模型中以生成KV缓存和第一个输出的对数几率(可能的token输出的概率分布)。这个过程通常很快,因为整个提示文本可以并行处理。
第二个阶段是解码(decoding)。从输出的对数几率中选择一个token,并将其反馈到模型中,模型将生成下一个token的对数几率。重复这个过程,直到生成所需数量的token。
由于解码必须按顺序进行,每次都需要将权重流通过计算单元以生成单个token。因此当以小量批运行时,这个第二阶段的计算密集度(即计算FLOP/内存带宽的字节数)非常低。因此,解码通常是自回归生成中最昂贵的部分。
这就是为什么OpenAI的API调用中,输入token比输出token便宜得多的原因。
「推测解码」的基本思想是使用一个更小、更快的草案模型提前解码多个token,然后将它们作为一个批输入到预测模型中。
如果草案模型的预测是正确的,即更大的模型也同意这些预测,那么可以使用单个批解码多个token,这样可以节省大量的内存带宽和时间。
然而,如果更大的模型拒绝了草案模型预测的token,则剩余的批将被丢弃,算法自然会恢复到标准的逐个token解码。
「推测解码」可能还伴随着拒绝抽样的方案,以从原始分布中进行采样。值得注意的是,这仅在带宽是瓶颈的小批设置中有用。
「推测解码」以计算换取带宽,而成为一个有吸引力的性能工程目标有两个关键原因:
首先,它不会降低模型质量。其次,它提供的性能改进通常与其他方法正交,因为其性能来自于将「顺序执行」转换为「并行执行」。
当前的推测方法为批预测的单独序列。然而,这种方法不能很好地拓展到大量的批,或低草案模型对齐上。
直观地说,两个模型在连续长序列的token上达成一致的概率呈指数级低,这意味着随着算术密度的增加,推测解码的收益会迅速减少。
爆料者认为,如果OpenAI使用「推测解码」,他们可能只在大约4个token的序列中使用。
顺便提一句,有关OpenAI阉割,而导致GPT-4质量降低的整个阴谋,可能只是因为他们让预测模型接受了「推测解码」模型的低概率序列。
另外有人推测,Bard也使用了「推测解码」,因为谷歌在将整个序列发送给用户之前会等待其完全生成,但在爆料者认为,这种猜测是完全不正确的。
视觉多模态
视觉多模态能力是GPT-4中最不令人印象深刻的部分,至少与领先的研究相比是如此。
当然,现在还没有人将多模态LLM的研究成果商业化。
爆料者称,它是一个独于文本编码器的视觉编码器,还有交叉注意力,架构类似于Flamingo,并在GPT-4 1.8T上增加了更多参数。
GPT-4多模态能力是在文本预训练之后,又用大约2万亿token进⾏了微调。
据称,在视觉模型上,OpenAI原本希望从头开始训练,但因其不够成熟,无奈从文本训练模型进行微调。
而下一代模型GPT-5,其训练应该从零开始训练视觉模型,并且能够生成图像,甚至生成音频。
这样的视觉能力主要目的之一,让自主智能体能够阅读网页,并转录图像,视频中的内容。
值得一提的是,OpenAI用来训练多模态模型的数据包括:「联合数据」(LaTeX/文本)、网页屏幕截图、YouTube视频(采样帧,以及运行Whisper获取字幕)。
关于LLM的过度优化,一个有趣的事实是视觉模型的IO成本不同于文本模型。在视觉模型中,数据加载IO大约是文本模型的150倍。

视觉模型的IO成本很低
视觉模型中的每个token 600字节,文本是4字节/token。
因此这需要在图像压缩方面做很多工作。这对于硬件供应商来说极为重要,因为他们正在围绕LLM的用例和比率优化2-3年后的硬件。
他们可能会发现自己身处的世界中,每个模型都具有强大的视觉和音频功能。
他们可能会发现自己的架构适应性会很差。
总的来说,架构肯定会超越我们今天看到的基于文本简化的密集模型,和MoE模型。
参考资料:
https://www.semianalysis.com/p/gpt-4-architecture-infrastructure
相关文章









关于作者

猜你喜欢























