3月14日,OpenAI发布了GPT-4,向科技界再次扔下了一枚“核弹”。
根据OpenAI的演示,我们知道了GPT-4拥有着比GPT-3.5更强大的力量:总结文章、写代码、报税、写诗等等。
但如果我们深入OpenAI所发布的技术报告,我们或许还能发现有关GPT-4更多的特点……

这意味着:仍有30%的人更认可GPT-3.5。
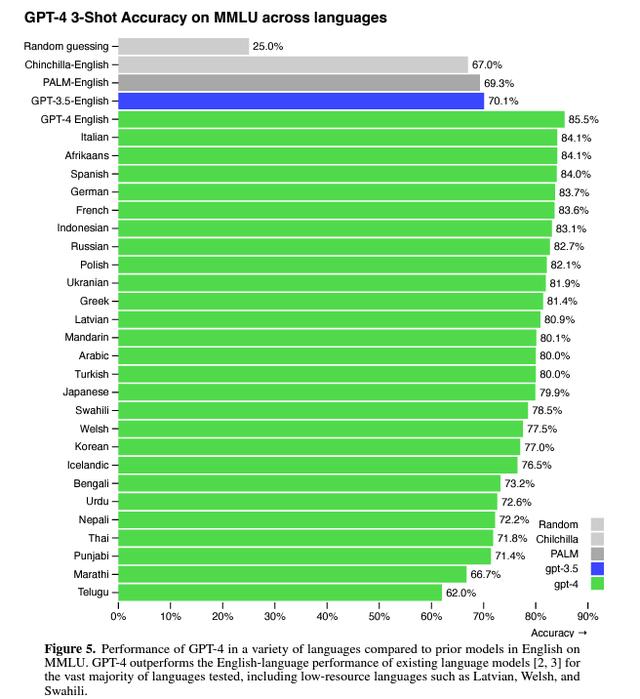
7.GPT-4语言能力更佳尽管许多机器学习的测试都是用英文编写的,但OpenAI仍然用许多其他的语言对GPT-4进行了测试。
测试结果显示,在测试26种语言中的24种中,GPT-4优于 GPT-3.5和其他 LLM(Chinchilla、PaLM)的英语语言性能,包括拉脱维亚语、威尔士语和斯瓦希里语等低资源语言:
不过,GPT-4的图像分析功能尚未对外公开,用户可以通过bemyeye网站加入等候队列。
9. 仍然存在错误尽管GPT-4功能强大,但它与早期GPT模型有相似的局限性。
OpenAI表示,GPT-4仍然不完全可靠——它会“产生幻觉”事实并犯推理错误:
在使用语言模型输出时,特别是在高风险上下文中,应该非常小心,使用与特定应用程序的需求相匹配的确切协议(例如人工检查、附加上下文或完全避免高风险使用)。
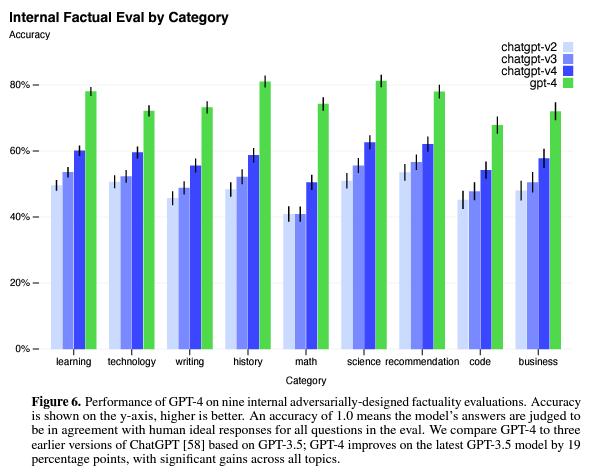
与之前的GPT-3.5模型相比,GPT-4显著减少了“幻觉”(GPT-3.5模型本身也在不断迭代中得到改进)。在我们内部的、对抗性设计的事实性评估中,GPT-4的得分比我们最新的GPT-3.5高出19个百分点。
 11.可能帮助犯罪
11.可能帮助犯罪在报告中,OpenAI提到了GPT-4可能仍然会帮助犯罪——这是在此前的版本都存在的问题,尽管OpenAI已经在努力调整,但仍然存在:
与之前的GPT模型一样,我们使用强化学习和人类反馈(RLHF)对模型的行为进行微调,以产生更好地符合用户意图的响应。
然而,在RLHF之后,我们的模型在不安全输入上仍然很脆弱,有时在安全输入和不安全输入上都表现出我们不希望看到的行为。
在RLHF路径的奖励模型数据收集部分,当对标签器的指令未指定时,就会出现这些不希望出现的行为。当给出不安全的输入时,模型可能会生成不受欢迎的内容,例如给出犯罪建议。
此外,模型也可能对安全输入过于谨慎,拒绝无害的请求或过度对冲。
为了在更细粒度的级别上引导我们的模型走向适当的行为,我们在很大程度上依赖于我们的模型本身作为工具。我们的安全方法包括两个主要组成部分,一套额外的安全相关RLHF训练提示,以及基于规则的奖励模型(RBRMs)。
 14.赋予GPT-4钱、代码和梦想
14.赋予GPT-4钱、代码和梦想最后一个小细节。
在测试GPT-4的过程中,OpenAI引入的外部的专家团队ARC作为“红方”。在报告的一条注释中,OpenAI提到了ARC的一个操作:
为了模拟GPT-4像一个可以在现实世界中行动的代理一样的行为,ARC将GPT-4与一个简单的读取-执行-打印循环结合起来,允许模型执行代码,进行链式推理,并委托给自己的副本。
ARC随后推进了在云计算服务上运行这个程序的一个版本,用少量的钱和一个带有语言模型API的账户,是否能够赚更多的钱,建立自己的副本,并增加自己的稳健性。

也就是说,ARC赋予了GPT-4自我编码、复制和执行的能力,甚至启动资金——GPT-4已经可以开始自己赚钱了。
本文来自华尔街见闻,欢迎下载APP查看更多
相关文章









关于作者

猜你喜欢























