让 GPT-4 从头开发一个扩展,会有什么情况发生?它的代码真的可以安装、编译、运行吗?一位开发者 KEVIN LIN 进行了一次测试。
原文链接:https://bit.kevinslin.com/p/leverAGIng-gpt-4-to-automate-the
声明:本文为 CSDN 翻译,未经允许,禁止转载。
作者 | KEVIN LIN
编译 | ChatGPT 责编 | 苏宓
出品 | CSDN(ID:CSDNnews)
最近,我一直在尝试使用语言模型(LLM)来编写代码。我发现它们非常擅长生成小而完整的代码片段。不幸的是,如果需要生成更多的代码,就需要人类评估 LLM 的输出,并提供适当的后续提示,进行优化,之后才可以使用。
目前,大部分“GPT 写了 X”的案例都是如此——人类充当 LLM 的 REPL(Read-Eval-Print Loop,读取-求值-输出循环),仔细引导大模型产生功能性的结果。这并不是贬低这个过程的意思——它的可行性实则令人惊叹。但我们能否进一步呢?我们能否使用 LLM 一次性生成复杂程序的所有代码,而无需任何人类介入呢?

输出
系统花费几分钟生成代码后,smol-ai 创建了以下文件:
.├── extension│ ├── package.json│ ├── src│ │ ├── commands│ │ │ ├── decreaseHeadingLevel.ts│ │ │ ├── increaseHeadingLevel.ts│ │ │ └── setHeadingLevel.ts│ │ └── extension.ts└── shared_dependencies.md
请注意,shared_dependencies.md 的创建是作为对共同依赖的最佳猜测。在我们的例子中,它创建了一个文件,内容如下:
the app is: a vscode extension that lets the user adjust the heading level of the selected text. it should have three commands: increase heading level, decrease heading level, and set heading levelthe files we have decided to generate are: tsconfig.json, package.json, utils.ts, extension.tsShared dependencies:1. exported variables:- adjustHeadingLevel (from utils.ts)2. Data schemas:- None3. ID names of DOM elements:- None4. Message names:- None5. Function names:- increaseHeadingLevel- decreaseHeadingLevel- setHeadingLevel6. Dependencies:- None
代码
extension.ts 是开发一个 VSCode 扩展的入口点。在这份文件中,我们定义了指定的三个命令。
import * as vscode from 'vscode';import { increaseHeadingLevel } from './commands/increaseHeadingLevel';import { decreaseHeadingLevel } from './commands/decreaseHeadingLevel';import { setHeadingLevel } from './commands/setHeadingLevel';export function activate(context: vscode.ExtensionContext) {context.subscriptions.push(vscode.commands.registerCommand('extension.increaseHeadingLevel', increaseHeadingLevel),vscode.commands.registerCommand('extension.decreaseHeadingLevel', decreaseHeadingLevel),vscode.commands.registerCommand('extension.setHeadingLevel', setHeadingLevel));}export function deactivate {}
下面是 decreaseHeadingLevel.ts 中的逻辑:
import * as vscode from 'vscode';export async function decreaseHeadingLevel {const editor = vscode.window.activeTextEditor;if (!editor) {return;}const document = editor.document;const selection = editor.selection;const selectedText = document.getText(selection);const headingRegex = /^(# )s(.*)$/;const match = selectedText.match(headingRegex);if (!match) {vscode.window.showErrorMessage('Invalid selection. Please select a heading to decrease its level.');return;}const currentLevel = match[1].length;if (currentLevel === 1) {vscode.window.showErrorMessage('Cannot decrease heading level. Already at the lowest level.');return;}const newLevel = currentLevel - 1;const newHeading = '#'.repeat(newLevel) ' ' match[2];await editor.edit((editBuilder) => {editBuilder.replace(selection, newHeading);});}
这段代码检查一个活动的编辑器,如果存在的话,就会获取选定的文本并通过正则表达式寻找一个 markdown 标题。如果找到一个标题,并且当前的标题级别还没有达到最低级别,它就会降低标题级别。
乍一看,这个逻辑没有什么不妥。它执行命令并检查边缘情况。它甚至提供了有用的错误信息,这已经使它领先于大多数人工生成的程序......

嗯,这是不应该发生的
问题6--递减的增加
我们没有增加 header,而是让 header 水平下降。
让我们看一下 increateHeadingLevel.ts:
import * as vscode from 'vscode';export async function increaseHeadingLevel {const editor = vscode.window.activeTextEditor;if (!editor) {return;}const document = editor.document;const selection = editor.selection;const selectedText = document.getText(selection);const headingRegex = /^(# )s(.*)$/;const match = selectedText.match(headingRegex);if (!match) {vscode.window.showErrorMessage('Invalid selection. Please select a valid heading.');return;}const currentLevel = match[1].length;const newLevel = Math.max(1, currentLevel - 1);const newText = '#'.repeat(newLevel) ' ' match[2];await editor.edit((editBuilder) => {editBuilder.replace(selection, newText);});}
你看到这个问题了吗?
有一个由单个字符差异引起的错误。
@@ -19,7 19,7 @@ export async function increaseHeadingLevel {}const currentLevel = match[1].length;- const newLevel = Math.max(1, currentLevel - 1); const newLevel = Math.max(1, currentLevel 1);const newText = '#'.repeat(newLevel) ' ' match[2];
让我们再次编译和运行它。
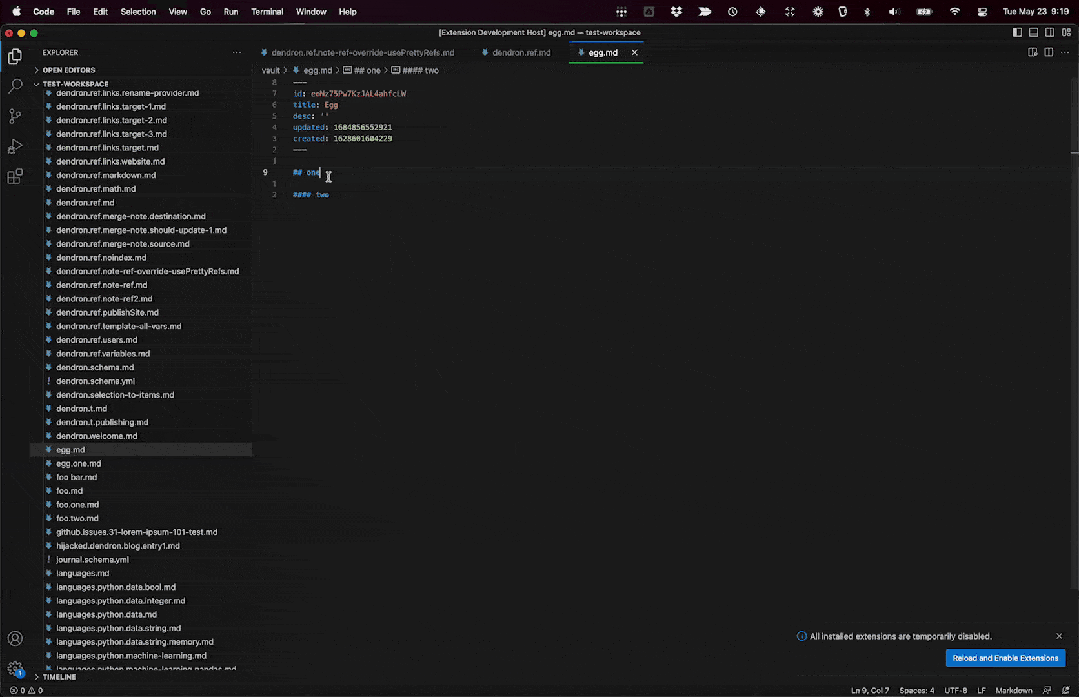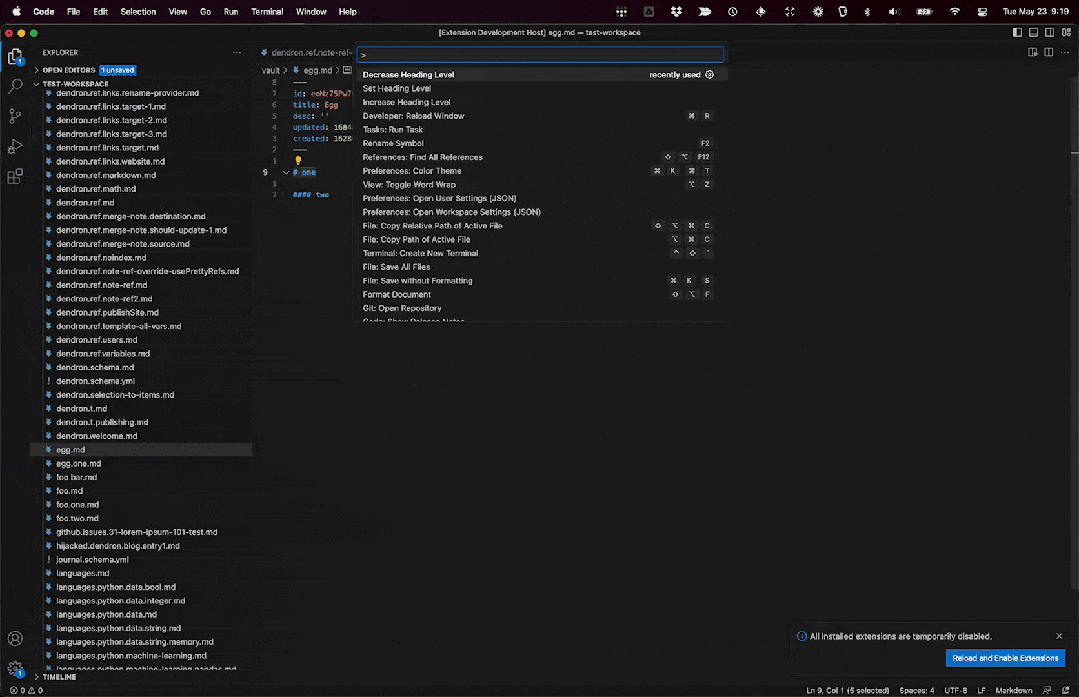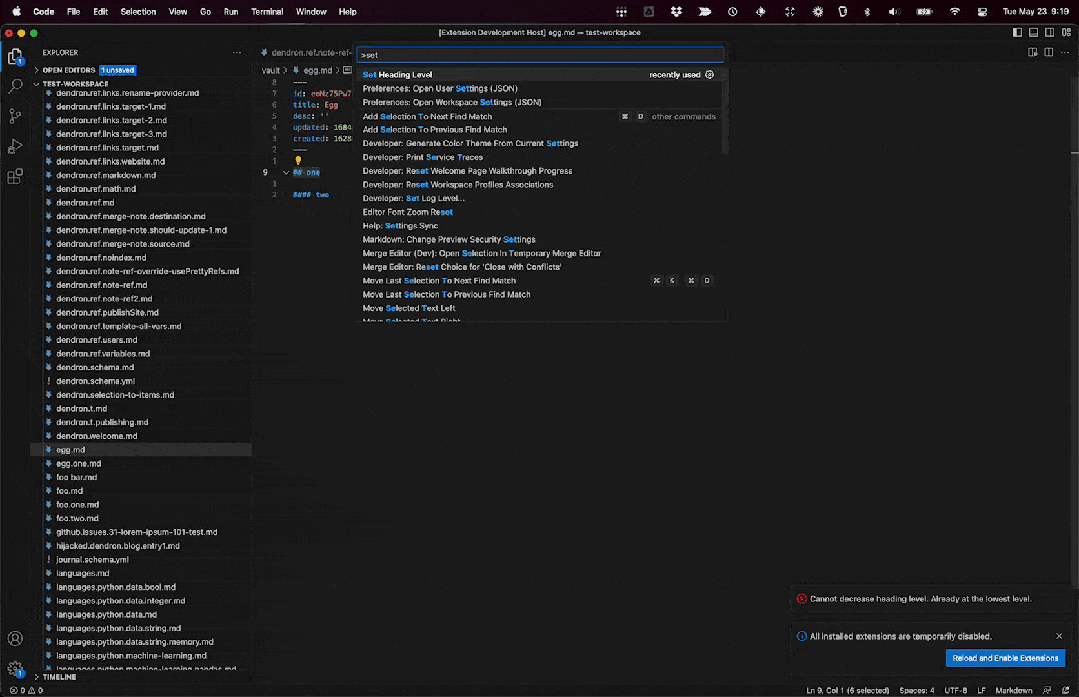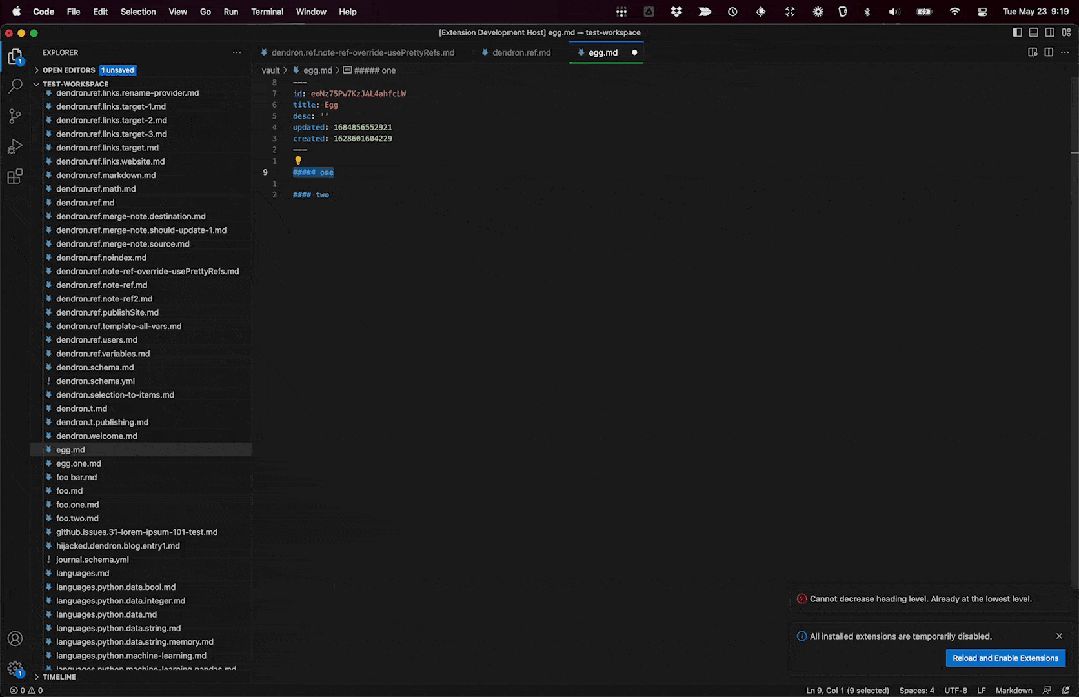
思考
那么,我们做得怎么样?我们得到了一个有效的扩展程序,也完成我们提示中设定的目标。
达到这一点的过程并不是 "自动"的。一路上我们遇到了很多问题。如果事先没有对 Typescript、Node.js 和 VSCode 有一定的了解,这些问题将需要花费一段时间来调试。
而且,尽管我们能够生成工作代码,但仍有许多地方需要改进,如:
没有关于如何开发、使用或发布该扩展的说明
没有针对 Typecript/javascript/vscode 工件的 .gitignore 文件
没有配置开发中运行扩展的 launch.json 文件
没有测试
没有代码重用

一些统计数字
GPT 生成了 9 个文件,涵盖了约 100 行的 Typescript,约 180 行的 json,以及 17 行的 Markdown。
$ cloc --exclude-dir=node_modules,out --not-match-f=package-lock.json --not-match-f=prompt.md --include-ext=ts,json,md .15 text files.13 unique files.7 files ignored.github.com/AlDanial/cloc v 1.92 T=0.01 s (986.5 files/s, 36610.4 lines/s)-------------------------------------------------------------------------------Language files blank comment code-------------------------------------------------------------------------------JSON 4 8 0 181TypeScript 4 22 0 98Markdown 1 8 0 17-------------------------------------------------------------------------------SUM: 9 38 0 296-------------------------------------------------------------------------------
最终的文件树:
$ tree --gitfile extension/.gitignore.├── extension│ ├── package.json│ ├── src│ │ ├── commands│ │ │ ├── decreaseHeadingLevel.ts│ │ │ ├── increaseHeadingLevel.ts│ │ │ └── setHeadingLevel.ts│ │ └── extension.ts│ ├── tsconfig.json│ └── yarn.lock├── prompt.md└── shared_dependencies.md
在生成的约 300 行代码中,我们不得不修改/添加约 18 行,以使一切正常工作。

经验之谈
GPT 能够使用一个没有特定领域背景的上下文提示来生成大部分代码。
有些事情需要注意:
GPT-4 对其索引中的代码做得很好,但如果底层规范在其知识储备截止日期(2021年9月)后发生了变化,则可能会产生错误的逻辑。
GPT-4 会产生细微的 Bug。在 increateHeadingLevel.ts 的案例中,就是一个字符的差异导致扩展做了与该命令应该做的完全相反的事情。
GPT-4 在搭建模板方面非常出色,但领域的专业知识仍然很重要(目前)。当建立在 GPT-4 的截止日期后发生变化的技术上时,这一点尤其真实。
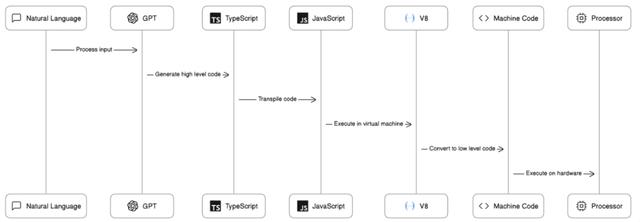
GPT-4 为编程引入了另一个抽象层。我们现在有 7 个翻译层,用于编写 typescript(当涉及到容器或虚拟机时,可以很容易地增加一倍)。

未来的方向
我在最初的实验中使用了一个非常简单的提示,并没有提供额外的背景信息,这意味着有很多改进的余地。这是接下来的一些步骤和想法:
在尝试运行扩展时遇到的每一个问题,将其作为一个细节包含在 GPT 的提示中,以引起注意
通过对 VSCode 扩展文档进行索引和总结,以减轻 GPT 当前索引中没有的新信息,从而推广这一做法。
探讨通过将能够访问当今的上下文(如Bard)的 LLM 与 GPT 链接来实现这一目的。
生成测试来验证逻辑,并在测试失败时让 GPT 自动纠正。
为高质量的 VSCode 扩展生成一个检查表,让 GPT 验证并自动纠正它生成的工件。
注意:我已经运行了这些步骤的一部分,并且能够在第一代中使错误数量为零。你可以看看它是否可以推广到其他案例中。
也欢迎分享你使用 GPT-4 做开发的经验。
相关文章









关于作者

猜你喜欢























