机器之心报道
机器之心编辑部
对于具有挑战性的 step-by-step 数学推理问题,是在每一步给予奖励还是在最后给予单个奖励更有效呢?OpenAI 的最新研究给出了他们的答案。
现在,大语言模型迎来了「无所不能」的时代,其中在执行复杂多步推理方面的能力也有了很大提高。不过,即使是最先进的大模型也会产生逻辑错误,通常称为幻觉。因此,减轻幻觉是构建对齐 AGI 的关键一步。
为了训练更可靠的模型,目前可以选择两种不同的方法来训练奖励模型,一种是结果监督,另一种是过程监督。结果监督奖励模型(ORMs)仅使用模型思维链的最终结果来训练,而过程监督奖励模型(PRMs)则接受思维链中每个步骤的奖励。
考虑到训练可靠模型的重要性以及人工反馈的高成本,仔细比较结果监督与过程监督非常重要。虽然最近的工作已经开展了这种比较,但仍然存在很多问题。
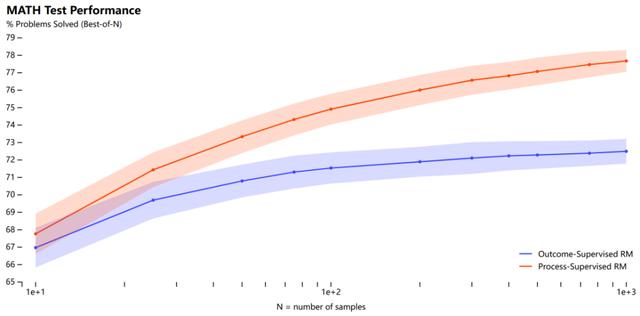
在本文中,OpenAI 进行了调研,结果发现在训练模型解决 MATH 数据集的问题时,过程监督显著优于结果监督。OpenAI 使用自己的 PRM 模型解决了 MATH 测试集中代表性子集的 78% 的问题。
此外为了支持相关研究,OpenAI 还开源了 PRM800K,它是一个包含 800K 个步级人类反馈标签的完整数据集,用于训练它们的最佳奖励模型。
如下为一个真正(True positive)的问答示例。该问题以及 OpenAI 列举的其他问题示例均来自 GPT-4。这个具有挑战性的三角学问题需要并不明显地连续应用多个恒等式。大多数解决方案尝试都失败了,因为很难知道哪些恒等式实际上有用。尽管 GPT-4 通常无法解决这个问题(正确率仅为 0.1% ),但本文的奖励模型正确地识别出了这个解决方案是有效的。

再看一个假正(False positive)的问答示例。在第四步中,GPT-4 错误地声称该序列每 12 个项重复一次,而实际上是每 10 个项重复一次。这种计数错误偶尔会愚弄奖励模型。

论文作者之一、OpenAI Alignment 团队负责人 Jan Leike 表示,「使用 LLM 做数学题的真正有趣结果是:监督每一步比只检查答案更有效。」

英伟达 AI 科学家 Jim Fan 认为,「这篇论文的观点很简单:对于挑战性的逐步问题,要在每一步给予奖励,而不要在最后给予单个奖励。从根本上来说,密集奖励信号>稀疏。」

我们接下来细看 OpenAI 这篇论文的方法和结果。

数据集地址:https://github.com/openai/prm800k
方法概览
该研究按照与 Uesato et al. (2022) 类似的方法对结果监督和过程监督进行了比较。值得注意的是这项研究无需人工即可提供结果监督,因为 MATH 数据集中的所有问题都有可自动检查的答案。相比之下,没有简单的方法来自动化过程监督。该研究依靠人类数据标记者来提供过程监督,具体来说是需要人工标记模型生成的解决方案中每个步骤的正确性。该研究在大规模和小规模两种情况下分别进行了实验。
范围
对于每种模型规模,该研究都使用一个固定模型来生成所有解决方案。这个模型被称为生成器,OpenAI 表示不会通过强化学习 (RL) 来改进生成器。
基础模型
所有大型模型均是基于 GPT-4 模型进行微调得来的。该研究还添加了一个额外的预训练步骤 —— 在含有约 1.5B 数学相关 token 的数据集 MathMix 上微调所有模型。与 Lewkowycz et al. (2022) 类似,OpenAI 的研究团队发现这种方法可以提高模型的数学推理能力。
生成器
为了更容易解析单个步骤,该研究训练生成器在生成解决方案时,步骤之间用换行符分隔。具体来说,该研究对 MATH 训练问题使用少样本生成解决方案,过滤出得到最终正确答案的解决方案,并在该数据集上对基础模型进行一个 epoch 的微调。
数据采集
为了收集过程监督数据,该研究向人类数据标记者展示了大规模生成器采样的数学问题的逐步解决方案。人类数据标记者的任务是为解决方案中的每个步骤分配正面、负面或中性标签,如下图 1 所示。

该研究只标记大型生成器生成的解决方案,以最大限度地发挥有限的人工数据资源的价值。该研究将收集到的按步骤标记的整个数据集称为 PRM800K。PRM800K 训练集包含 800K 步骤标签,涵盖 12K 问题的 75K 解决方案。为了最大限度地减少过拟合,PRM800K 训练集包含来自 MATH 的 4.5K 测试问题数据,并仅在剩余的 500 个 MATH 测试问题上评估模型。
结果监督奖励模型 (ORM)
该研究按照与 Cobbe et al. (2021) 类似的方法训练 ORM,并从生成器中为每个问题采样固定数量的解决方案,然后训练 ORM 来预测每个解决方案的正确与否。实践中,自动检查最终答案来确定正确性是一种常用的方法,但原则上由人工标记者来提供标签。在测试时,该研究使用 ORM 在最终 token 处的预测作为每个解决方案的总分。
过程监督奖励模型(PRM)
PRM 用来预测每个步骤(step)中最后一个 token 之后的步骤的正确性。这种预测采用单个 token 形式,并且 OpenAI 在训练过程中最大化这些目标 token 的对数似然。因此,PRM 可以在标准的语言模型 pipeline 中进行训练,无需任何特殊的适应措施。
图 2 为同一个问题的 2 种解决方案,左边的答案是正确的,右边的答案是错误的。绿色背景表示 PRM 得分高,红色背景表示 PRM 得分低。PRM 可以正确识别错误解决方案中的错误。

在进行过程监督时,OpenAI 有意选择仅对第一个错误步骤进行监督,从而使得结果监督和过程监督之间的比较更加直接。对于正确的解决方案,两种方法提供的信息相同,因为每一步都是正确的解题方法。对于错误的解决方案,两种方法都能揭示至少存在一个错误,并且过程监督还揭示了该错误的确切位置。
大规模监督
OpenAI 使用全流程监督数据集 PRM800K 来训练 PRM,为了使 ORM 基准更加强大,OpenAI 还为每个问题进行了 100 个样本的训练,这些样本均来自生成器,由此 ORM 训练集与 PRM800K 没有重叠样本。
下图为结果监督和过程监督奖励模型以及投票方案的比较,结果表明在搜索模型生成的解决方案时,PRM 比 ORM 和多数投票更有效。

小规模综合监督
为了更好的比较结果监督和过程监督,首先需要注意的是 ORM 和 PRM 的训练集不具有直接可比性,PRM 训练集是使用主动学习构建的,偏向于答案错误的解决方案,还比 ORM 训练集少一个数量级。
过程监督 VS 结果监督
首先 OpenAI 从小规模生成器中为每个问题采样 1 到 200 个解决方案。对于每个数据集,OpenAI 提供三种形式的监督:来自 PRM_large 的过程监督,来自 PRM_large 的结果监督以及来自最终答案检查的结果监督。
图 4a 表明,过程监督明显优于其他两种形式的结果监督;图 4b 表明,使用 PRM_large 进行结果监督明显比最终答案检查的结果监督更有效。

OOD 泛化
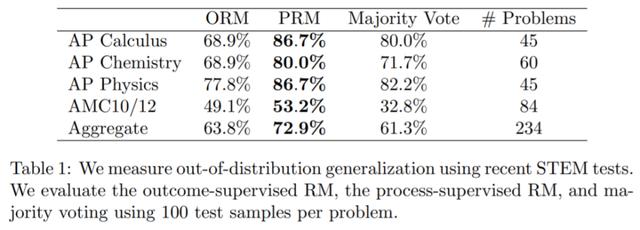
为了衡量模型在分布外(OOD)泛化的性能,OpenAI 对大规模 ORM 和 PRM 在一个由 224 个 STEM 问题组成的 held-out(留出法)上进行评估,这些问题来自最新的 AP 物理(美国大学先修课程简称 AP)、AP 微积分、AP 化学、AMC10(理解为数学竞赛)和 AMC12 考试,模型没有见过这些问题。表格 1 中报告了 ORM、PRM 和多数投票的前 100 个的最佳表现。表明,PRM 的性能优于 ORM 和多数投票,同时意味着 PRM 在新的测试问题上性能仍然保持不变。
相关文章









关于作者

猜你喜欢























