本文约2000字,建议阅读5分钟
GPT-3、Stable Diffusion 一起助攻,让模型秒变 PS 高手,改图随心所欲。
AI 可以完全按照甲方意愿修图?GPT-3、Stable Diffusion 一起助攻,让模型秒变 PS 高手,改图随心所欲。
扩散模型大火之后,很多人将注意力放到了如何利用更有效的 prompt 生成自己想要的图像。在对于一些 AI 作画模型的不断尝试中,人们甚至总结出了让 AI 好好出图的关键词经验:

论文地址:
https://arxiv.org/pdf/2211.09800.pdf
例如,要把画中的向日葵换成玫瑰,你只需要直接对模型说「把向日葵换成玫瑰」:

生成一个多模态训练数据集
在数据集生成阶段,研究者结合了一个大型语言模型(GPT-3)和一个文本转图像模型(Stable Diffusion)的能力,生成了一个包含文本编辑指令和编辑前后对应图像的多模态训练数据集。这一过程包含以下步骤:
微调 GPT-3 以生成文本编辑内容集合:给定一个描述图像的 prompt,生成一个描述要进行的更改的文本指令和一个描述更改后图像的 prompt(图 2a);使用文本转图像模型将两个文本 prompt(即编辑之前和编辑之后)转换为一对对应的图像(图 2b)。InstructPix2Pix
研究者使用生成的训练数据来训练一个条件扩散模型,该模型基于 Stable Diffusion 模型,可以根据书面指令编辑图像。
扩散模型学习通过一系列估计数据分布分数(指向高密度数据的方向)的去噪自编码器来生成数据样本。Latent diffusion 通过在预训练的具有编码器

此前,曾有研究(Wang et al.)表明,对于图像翻译(image translation)任务,尤其是在成对训练数据有限的情况下,微调大型图像扩散模型优于从头训练。因此在新研究中,作者使用预训练的 Stable Diffusion checkpoint 初始化模型的权重,利用其强大的文本到图像生成能力。
为了支持图像调节,研究人员向第一个卷积层添加额外的输入通道,连接 z_t 和

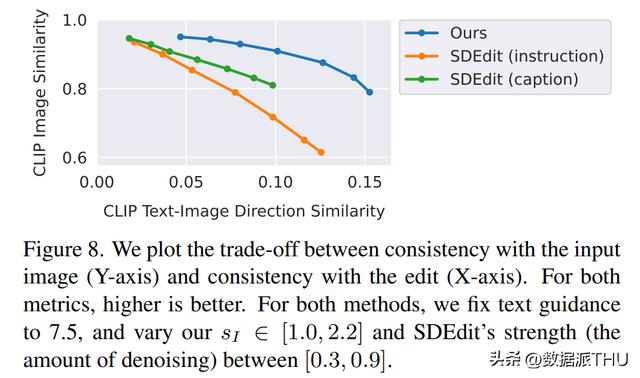
研究人员将新方法与最近的一些技术,如 SDEdit、Text2Live 等进行了比较。新模型遵循编辑图像的说明,而其他方法(包括基准方法)需要对图像或编辑层进行描述。因此在比较时,作者对后者提供「编辑后」的文本标注代替编辑说明。作者还把新方法和 SDEdit 进行定量比较,使用两个衡量图像一致性和编辑质量的指标。最后,作者展示了生成训练数据的大小和质量如何影响模型性能的消融结果。

关于作者

猜你喜欢