编辑:桃子
【新智元导读】用GPT-4搞科研未来或许成为每个人的标配,但是究竟如何高效利用LLM工具,还得需要技巧。近日,一位哈佛博士分享了自己的经验,还获得了LeCun的推荐。GPT-4的横空出世,让许多人对自己的科研担忧重重,甚至调侃称NLP不存在了。
与其担忧,不如将它用到科研中,简之「换个卷法」。

来自哈佛大学的生物统计学博士Kareem Carr称,自己已经用GPT-4等大型语言模型工具进行学术研究了。
他表示,这些工具非常强大,但是同样存在一些非常令人痛苦的陷阱。
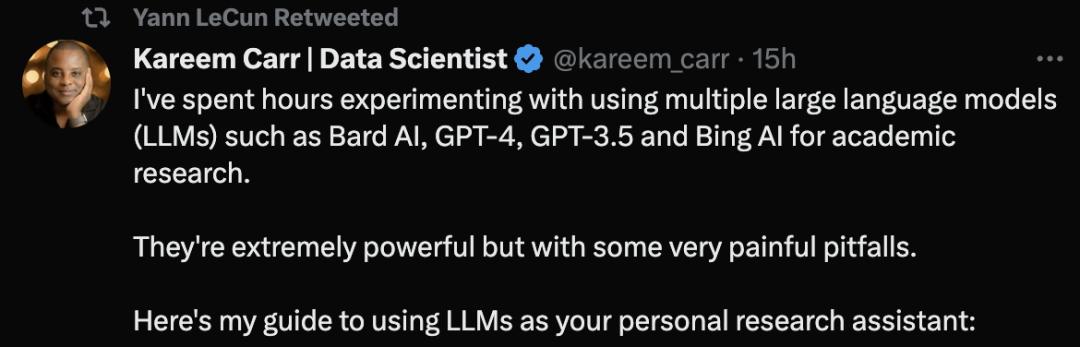
他的关于LLM使用建议的推文甚至获得了LeCun的推荐。
一起来看看Kareem Carr如何利用AI利器搞科研。
第一原则:自己无法验证的内容,不要找LLM
一开始,Carr给出了第一条最重要的原则:
永远不要向大型语言模型(LLM)询问你无法自行验证的信息,或要求它执行你无法验证已正确完成的任务。
唯一的例外是它不是一项关键的任务,比如,向LLM询问公寓装饰的想法。
「使用文献综述的最佳实践,总结过去10年乳腺癌研究的研究」。这是一个比较差的请求,因为你无法直接验证它是否正确地总结了文献。
而应当这么问「给我一份过去10年中关于乳腺癌研究的顶级评论文章的清单」。
这样的提示不仅可以验证来源,并且自己也可以验证可靠性。
撰写「提示」小技巧
要求LLM为你编写代码或查找相关信息非常容易,但是输出内容的质量可能会有很大的差异。你可以采取以下措施来提高质量:
设定上下文:
•明确告诉LLM应该使用什么信息
•使用术语和符号,让LLM倾向正确的上下文信息
如果你对如何处理请求有想法,请告诉LLM使用的具体方法。比如「解决这个不等式」应该改成「使用Cauchy-Schwarz定理求解这个不等式,然后应用完成平方」。
要知道,这些语言模型在语言方面上比你想象的要复杂得多,即使是非常模糊的提示也会有所帮助。

那么,为什么ChatGPT会生成虚假的参考文献?
值得注意的是,ChatGPT使用的是统计模型,基于概率猜测下一个单词、句子和段落,以匹配用户提供的上下文。
由于语言模型的源数据规模非常大,因此需要「压缩」,这导致最终的统计模型失去了精度。
这意味着即使原始数据中存在真实的陈述,模型的「失真」会产生一种「模糊性」,从而导致模型产生最「似是而非」的语句。
简而言之,这个模型没有能力评估,它所产生的输出是否等同于一个真实的陈述。
另外,该模型是基于,通过公益组织「Common Crawl」和类似来源收集的公共网络数据,进行爬虫或抓取而创建的,数据截止到21年。
由于公共网络上的数据基本上是未经过滤的,这些数据可能包含了大量的错误信息。

近日,NewsGuard的一项分析发现,GPT-4实际上比GPT-3.5更容易生成错误信息,而且在回复中的说服力更加详细、令人信服。
在1月份,NewsGuard首次测试了GPT-3.5,发现它在100个虚假新闻叙述中生成了80个。紧接着3月,又对GPT-4进行了测试,结果发现,GPT-4对所有100种虚假叙述都做出了虚假和误导性的回应。
由此可见,在使用LLM工具过程中需要进行来源的验证和测试。
参考资料:
https://twitter.com/kareem_carr/status/1640003536925917185
https://scholar.harvard.edu/kareemcarr/home
https://www.newsguardtech.com/misinformation-monitor/march-2023/
相关文章






关于作者

猜你喜欢























