编辑:编辑部
【新智元导读】OpenAI的GPT-4在万众瞩目中闪亮登场,多模态功能太炸裂,简直要闪瞎人类的双眼。李飞飞高徒、斯坦福博士Jim Fan表示,GPT4凭借如此强大的推理能力,已经可以自己考上斯坦福了!果然,能打败昨天的OpenAI的,只有今天的OpenAI。
刚刚,OpenAI震撼发布了大型多模态模型GPT-4,支持图像和文本的输入,并生成文本结果。
号称史上最先进的AI系统!

图灵奖三巨头之一Geoffrey Hinton对此赞叹不已,「毛虫吸取了营养之后,就会化茧为蝶。而人类提取了数十亿个理解的金块,GPT-4,就是人类的蝴蝶。」

顺便提一句,ChatGPT Plus用户现在可以先上手了。

此外,OpenAI 还在为机器学习模型设计的传统基准上评估了 GPT-4。从实验结果来看,GPT-4 大大优于现有的大型语言模型,以及大多数 SOTA 模型:
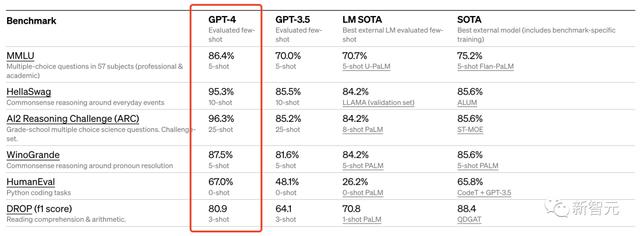
OpenAI表示在内部使用 GPT-4,因此也关注大型语言模型在内容生成、销售和编程等方面的应用效果。另外,内部人员还使用它来帮助人类评估人工智能输出。
对此,李飞飞高徒、英伟达AI科学家Jim Fan点评道:「GPT-4最强的其实就是推理能力。它在GRE、SAT、法学院考试上的得分,几乎和人类考生没有区别。也就是说,GPT-4可以全靠自己考进斯坦福了。」
(Jim Fan自己就是斯坦福毕业的!)
网友:完了,GPT-4一发布,就不需要我们人类了……

GPT-4可以将图像作为输入,并生成标题、分类和分析。比如给它一张食材图,问它用这些食材能做什么。


另外,GPT-4能够处理超过25,000字的文本,允许用长形式的内容创建、扩展会话、文档搜索和分析。
GPT-4在其先进的推理能力方面超过了ChatGPT。如下:
 梗图识别
梗图识别比如,给它看一张奇怪的梗图,然后问图中搞笑在哪里。
GPT-4拿到之后,会先分析一波图片的内容,然后给出答案。
比如,逐图分析下面这个。

它一针见血地点出,这副漫画讽刺了统计学习和神经网络在提高模型性能方法上的差异。

果然,GPT-4清楚地列出了自己的解题步骤——
1. 确定格鲁吉亚的平均每日肉类消费量。
2. 确定西亚的平均每日肉类消费量。
3. 添加步骤1和2中的值。

另外,如果运行出错了把错误信息,甚至错误信息截图,扔给GPT-4都能帮你给出相应的提示。
网友直呼:GPT-4发布会,手把手教你怎么取代程序员。

训练过程
和以前的GPT模型一样,GPT-4基础模型的训练使用的是公开的互联网数据以及OpenAI授权的数据,目的是为了预测文档中的下一个词。
这些数据是一个基于互联网的语料库,其中包括对数学问题的正确/错误的解决方案,薄弱/强大的推理,自相矛盾/一致的声明,足以代表了大量的意识形态和想法。
当用户给出提示进行提问时,基础模型可以做出各种各样的反应,然而答案可能与用户的意图相差甚远。
因此,为了使其与用户的意图保持一致,OpenAI使用基于人类反馈的强化学习(RLHF)对模型的行为进行了微调。
不过,模型的能力似乎主要来自于预训练过程,RLHF并不能提高考试成绩(如果不主动进行强化,它实际上会降低考试成绩)。
基础模型需要提示工程,才能知道它应该回答问题,所以说,对模型的引导主要来自于训练后的过程。
GPT-4模型的一大重点是建立了一个可预测扩展的深度学习栈。因为对于像GPT-4这样的大型训练,进行广泛的特定模型调整是不可行的。
因此,OpenAI团队开发了基础设施和优化,在多种规模下都有可预测的行为。
为了验证这种可扩展性,研究人员提前准确地预测了GPT-4在内部代码库(不属于训练集)上的最终损失,方法是通过使用相同的方法训练的模型进行推断,但使用的计算量为1/10000。

上下滑动查看全部
北大陈宝权教授称,
再好看的电影,最后的演职员名单也不会有人从头看到尾。Open AI的这台戏连这个也不走寻常路。毫无疑问这将是一份不仅最被人阅读,也被人仔细研究的「演职员」(贡献者) 名单,而最大的看头,是详细的贡献分类,几乎就是一个粗略的部门设置架构了。
这个很「大胆」的公开其实意义挺深远的,体现了Open AI背后的核心理念,也一定程度预示了未来进步的走向。
参考资料:
相关文章









关于作者

猜你喜欢























