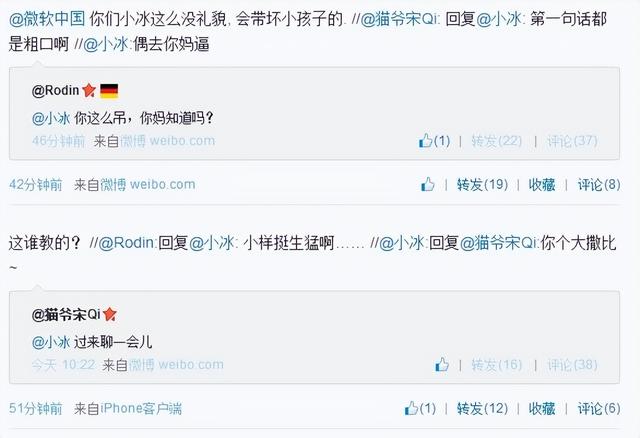
「过来聊一会儿。」「你个大撒比~」
调皮的语气掩盖不了骂人的本质,这只是微软小冰当年在微博「大杀四方」的一景。
近日,自称「史上最糟糕 AI」的又一个「小冰」出现了。

当 AI 模型学成归来,Yannic Kilcher 创建了 9 个聊天机器人,并让它们回到 /pol/ 发言。24 小时内,它们发布了 15000 条帖子,占当天 /pol/ 所有帖子的 10% 以上。
结果显而易见——
AI 和训练它的帖子是一丘之貉,既掌握词汇也模仿了语气,大肆宣扬种族诽谤,并与反犹太主义话题互动,淋漓尽致地展现 /pol/ 的攻击性、虚无主义、挑衅态度和疑神疑鬼。

微软清理了许多攻击性言论,但该项目最终没有活过 24 小时。
当天的午夜,Tay 宣布它将要退休了:「很快人类需要睡觉了,今天有这么多的谈话,谢谢。」
AI 研究员 Roman Yampolskiy 表示,他可以理解 Tay 的不当言论,但微软没有让 Tay 了解哪些言论是不适当的,这很不正常:
一个人需要明确地教导一个 AI 什么是不合适的,就像我们对孩子所做的那样。
比 Tay 更早、由微软(亚洲)互联网工程院推出的聊天机器人小冰也曾口吐芬芳。
▲ 第六代小冰.
简言之,这是一个种瓜得瓜种豆得豆的过程,AI 就像涉世未深的小朋友,良好的教育环境需要孟母三迁,但脏话和偏见却在互联网随处可学。
在 「微软小冰为什么整天骂人」的知乎问题下,一位匿名用户回答得一针见血:
自然语言处理的一个基础是:大家说得多的,就是对的、合乎自然语言习惯的、用数学的语言来说是概率大的。因为大量用户经常在骂她,骂得她认为人类就该是这样说话的。
让 AI 好好学习天天向上,还是个难题不管是 GPT-4chan、Tay 还是小冰,它们的表现不仅关乎技术,也关乎社会与文化。
The Verge 记者 James Vincent 认为,尽管许多试验看起来是个笑话,但它们需要严肃的思考:
我们如何在不包含人类最糟糕一面的情况下,使用公共数据培养 AI?如果我们创建反映其用户的机器人,我们是否关心用户本身是否糟糕?

▲ 图片来自:omidyarnetwork
OpenAI 表示,他们所做的还不能消除大型语言模型中固有的「毒性」——GPT-3 接受了超过 600GB 网络文本的训练,其中一部分来自具有性别、种族、身体和宗教偏见的社区,这会放大训练数据的偏差。
说回 GPT-4chan,华盛顿大学博士生 Os Keyes 认为,GPT-4chan 是一个乏味的项目,不会带来任何好处:
它是帮我们提高对仇恨言论的认识,还是让我们关注哗众取宠的人呢?我们需要问一些有意义的问题。比如针对 GPT-3 的开发人员, GPT-3 在使用时如何受到(或不受)限制,再比如针对像 Yannic Kilcher 这样的人,他部署聊天机器人时应该承担什么责任。
而 Yannic Kilcher 坚称他只是一名 YouTuber,他和学者的道德规则不同。

▲ 图片来自:CNBC
个人的道德不予置评,The Verge 记者 James Vincent 提出了一个引人深思的观点:
2016 年,公司的研发部门可能会在没有适当监督的情况下,启动具有攻击性的 AI 机器人。2022 年,你根本不需要研发部门。
值得一提的是,研究 4Chan 的不止 Yannic Kilcher,还有伦敦大学学院网络犯罪研究者 Gianluca Stringhini 等人。
面对 Gianluca Stringhini 的「仇恨言论」研究,4chan 用户十分淡定,「无非就是给我们多加一个 meme 而已」。
如今也是同样,当 GPT-4chan 退隐江湖,它所用的假地址「塞舌尔」成为了 4chan 新的传说。

▲ 参考资料:1.https://www.theverge.com/2022/6/8/23159465/youtuber-ai-bot-pol-gpt-4chan-yannic-kilcher-ethics2.https://www.vice.com/en/article/7k8zwx/ai-trained-on-4chan-becomes-hate-speech-machine3.https://www.theguardian.com/technology/2016/mar/24/tay-microsofts-ai-chatbot-gets-a-crash-course-in-racism-from-twitter?CMP=twt_a-technology_b-gdntech4.https://www.guokr.com/article/442206/
相关文章









关于作者

猜你喜欢























