杨净 发自 凹非寺量子位 报道 | 公众号 QbitAI
今天,谷歌大脑声称,他们新技术能训练万亿级参数的语言模型。

研究人员表示,大型稀疏模型可用于创建较小的密集模型,在任务上进行微调,其质量增益为大型模型的30%。
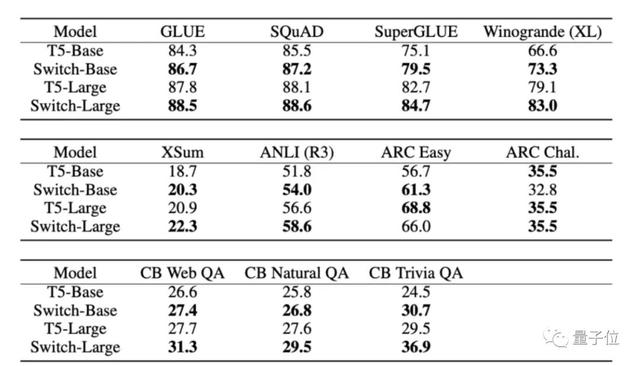
从整体结果上看,Switch Transformer 模型在多项推理和知识任务中带来了显著性能提升。这说明该模型架构不只对预训练有用,还可以通过微调将质量改进迁移至下游任务中。
研究人员表示,
我们无法完全保留模型质量,但通过将我们的稀疏模型提炼成密集模型,可以实现10到100倍的压缩率,同时实现约30%的专家模型的质量增益。
在未来的工作中,研究人员计划将Switch Transformer应用于不同模态或多模态模型,包括图像和文本。
参考链接:论文地址:https://arxiv.org/abs/2101.03961https://venturebeat.com/2021/01/12/google-trained-a-trillion-parameter-ai-language-model/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢























