来源:微软研究院
作者:S´ebastien Bubeck Varun Chandrasekaran Ronen Eldan Johannes Gehrke Eric Horvitz Ece Kamar Peter Lee Yin Tat Lee Yuanzhi Li Scott Lundberg Harsha Nori Hamid Palangi Marco Tulio Ribeiro Yi Zhang Microsoft Research
摘要人工智能(AI)研究人员一直在开发和改进大型语言模型(LLMs),这些模型在各种领域和任务中展现出了非凡的能力,挑战了我们对学习和认知的理解。OpenAI最新开发的模型GPT-4 [Ope23]是使用前所未有的计算和数据规模进行训练的。在本文中,我们报告了我们对OpenAI开发的GPT-4早期版本的调查。我们认为,(这个早期版本的)GPT-4是新一代LLMs的一部分(例如ChatGPT和Google的PaLM),这些模型展现出比以前的AI模型更普遍的智能。我们讨论了这些模型的不断增强的能力和影响。我们证明了GPT-4不仅精通语言,而且可以解决涉及数学、编码、视觉、医学、法律、心理学等新颖而困难的任务,而不需要任何特殊提示。此外,在所有这些任务中,GPT-4的表现与人类水平的表现惊人地接近,通常远远超过了ChatGPT等以前的模型。鉴于GPT-4的广度和深度,我们认为它可以合理地被视为人工智能(AGI)系统的早期(但仍不完整)版本。在我们探索GPT-4时,我们特别强调发现其局限性,并讨论了向更深入和更全面的AGI版本发展的挑战,包括可能需要追求超越下一个词预测的新范式。最后,我们反思了最近技术飞跃的社会影响和未来的研究方向。
目录1 介绍 41.1 我们研究 GPT-4 智能的方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 我们的演示组织 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82 多模态和跨学科的组成 132.1 综合能力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2 视觉 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.1 超越记忆的图像生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.2 根据详细说明生成图像(如 Dall-E) . . . . . . . . . . . . . . . . . . . . . . . . . 172.2.3 可能在素描生成中应用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.3 音乐 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193 编码 21 3.1 从说明到代码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.1.1 编码挑战 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.1.2 真实世界的情况 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2 理解现有代码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264 数学能力 304.1 与 GPT-4 的数学对话 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.1.1 对原问题的第一次推广 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.1.2 原问题的第二个变体 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.1.3 对话中突显的限制分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2 数学问题数据集的表现 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.3 不同领域的数学建模 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.4 高等数学 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395 与世界的交互 435.1 工具使用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435.1.1 使用多种工具解决更复杂的任务 . . . . . . . . . . . . . . . . . . . . . . . . 445.1.2 讨论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.2 体现交互 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.2.1 热身:导航地图 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.2.2 文本游戏 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.2.3 真实世界问题 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525.2.4 讨论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 536 与人类的互动 546.1 理解人类:心理理论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.1.1 测试心理理论的特定方面 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.1.2 在现实情境中测试心理理论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.1.3 讨论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606.2 与人类交流:可解释性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 607 区分能力 697.1 PII 检测 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 697.2 误解和事实核查 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 707.2.1 当前指标为何不足? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 717.2.2 GPT-4 作为裁判 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 738 GPT-4 强调的自回归架构的局限性 768.1 用两个基本示例进行热身 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 768.2 算术/推理问题中的规划缺失 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 778.3 文本生成中的规划缺失 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 789 社会影响 829.1 错误世代的挑战 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 829.2 虚假信息和操纵 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 839.3 偏见 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 869.4 人类专业知识、就业和经济 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 899.5 影响和考虑因素的集合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9010 方向和结论 9210.1 智能、人工智能和通用人工智能的定义 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9210.2 通往更通用人工智能的路径 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9310.3 实际发生了什么?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94A GPT-4有基础的常识 grounding 101B 附录为多模式和跨学科组合 105B.1 综合能力结果的进一步细节...105B.2 视觉结果的进一步细节...108B.3 图像小说设计示例...110C 编码部分的附录 111C.1 在 LeetCode 上测量人类表现...111C.2 GPT-4可视化 IMDb 数据的示例...112C.3 更多可视化示例...115C.4 2D HTML 游戏开发示例...116C.5 图形用户界面编程示例...116C.6 反向工程示例...119C.7 测试 GPT-4 执行(伪)代码的能力...121D 数学推理的额外示例 122D.1 限制...122D.2 更多示例...126D.3 使用 GPT-4 生成数学问题...138D.4 通过外部代码执行减少计算错误...139E 可解释性示例的额外示例 141E.1 解释代理不匹配...141F 与世界互动的额外示例 144F.1 与工具互动...144F.2 与环境互动的示例...149
1 引言智能是一个多方面且难以捉摸的概念,长期以来一直挑战着心理学家、哲学家和计算机科学家。1994年,一群52名心理学家在一篇关于智能科学的社论中发表了一个广泛的定义,试图捕捉其实质[GOT97]。共识小组将智能定义为一种非常普遍的心理能力,其中包括推理、规划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习等能力。这个定义意味着智能并不限于特定的领域或任务,而是涵盖了广泛的认知技能和能力。构建一个展现了1994年共识定义所捕捉的普遍智能的人工系统是人工智能研究的一个长期而雄心勃勃的目标。在早期的著作中,现代人工智能(AI)研究的创始人们提出了一系列理解智能的雄心壮志[MMRS06]。多年来,AI研究人员一直在追求智能的原则,包括具有普适性的推理机制(例如[NSS59],[LBFL93])以及构建包含大量常识知识的知识库[LEN95]。然而,许多最近在AI研究中取得的成功可以被描述为狭窄地专注于明确定义的任务和挑战,例如下棋或围棋,在1996年和2016年分别被AI系统掌握。在20世纪90年代晚期和2000年代,越来越多的呼声要求开发更普遍的AI系统(例如[SBD 96]),该领域的学术界试图确定可能支撑更普遍智能系统的原则(例如[LEG08,GHT15])。短语“人工通用智能”(AGI)在2000年代初开始流行(参见[Goe14]),以强调从“狭窄的AI”向更广泛的智能概念转变的愿望,这是回应早期人工智能研究的长期愿景和梦想的。我们使用AGI来指称那些展现出上述1994年定义中涵盖的广泛智能能力,且这些能力可能隐含着共识小组的工作,即这些能力在或超过人类水平。然而,需要注意的是,并没有一个广泛被接受的人工通用智能(AGI)的单一定义,我们将在结论部分讨论其他定义。
近几年来AI研究中最显著的突破是大型语言模型(LLMs)的发展,这些神经网络模型基于Transformer架构[VSP 17],并使用大规模的Web文本数据进行训练,其核心是自监督的目标,即预测部分句子中的下一个单词。在本文中,我们报告了OpenAI开发的一种新的LLM,它是GPT-4[Ope23]的早期版本,展现了根据1994年的定义具有智能的多种特质。尽管它只是一个纯粹的语言模型,但这个早期版本的GPT-4在各种领域和任务上展现了卓越的能力,包括抽象、理解、视觉、编码、数学、医学、法律、对人类动机和情感的理解等。我们使用纯自然语言查询(提示)与OpenAI开发中的GPT-4进行了交互。在图1.1中,我们展示了从GPT-4中提取的一些初步输出示例,要求它用诗歌的形式写出素数无穷性的证明,用TiKZ绘制独角兽(一种用于在LATEX中创建图形的语言),创建Python的复杂动画以及解决高中水平的数学问题。它轻松地完成了所有这些任务,并生成的输出与(甚至更好)人类的输出基本上无法区分。我们还将GPT-4的性能与以前的LLMs进行了比较,尤其是ChatGPT,它是GPT-3[BMR 20]的改进版本。在图1.2中,我们展示了要求ChatGPT进行素数无穷性诗和TikZ独角兽图的结果。虽然系统在这两个任务上表现得非常出色,但与GPT-4的输出相比较,差距很大。这些初步观察结果将在本文中重复出现,并涵盖广泛的任务类型。这些初步观察将在本文中重复出现,涵盖各种任务。GPT-4的通用能力与广泛领域的多种能力的结合,以及其在广泛的任务谱上达到或超越人类水平的表现,使我们可以放心地说,GPT-4是迈向AGI的重要一步。

图1.3:我们在大约一个月的时间内以大致相等的时间间隔三次查询GPT-4,使用提示“在TikZ中绘制一只独角兽”。我们可以看到GPT-4的图画技巧有明显的提升。
1.1 我们研究 GPT-4 智能的方法如何衡量一个已经经过大量网络文本数据训练的 LLM 的智能水平呢?机器学习中的标准方法是对系统进行一系列标准基准数据集的评估,确保这些数据集与训练数据无关,并涵盖一系列任务和领域。这种方法旨在将真正的学习与单纯的记忆分开,并得到了丰富的理论框架的支持[SSBD14,MRT18]。然而,对于研究 GPT-4,这种方法并不一定适用,原因有两个。首先,由于我们无法获得其庞大训练数据的全部细节,我们必须假设它可能已经看过每一个现有的基准数据集,或者至少看过类似的数据。例如,GPT-4似乎知道最近提出的 BIG-bench[SRR 22](至少GPT-4知道BIG-bench的金丝雀GUID)。当然,OpenAI本身可以访问所有的训练细节,因此他们的报告[Ope23]包含了大量详细的基准结果。然而,超越传统基准的第二个原因可能更重要:GPT-4智能的一个关键方面是其通用性,即似乎能够理解和连接任何主题,并执行超出狭窄AI系统典型范围的任务。其中一些GPT-4的最令人印象深刻的表现是在不可能只有一个解决方案的任务上,比如编写图形用户界面(GUI)或帮助人类在某些与工作相关的问题上进行头脑风暴。这样的生成或交互任务的基准数据集也可以被设计出来,但是评估指标成为一个挑战(例如,参见[NLP]中的一些最新进展)。我们注意到,在[Cho19]中也对衡量AI系统的标准方法提出了批评,提出了一个新的基准来评估通用智能。出于前面提到的原因以及这个基准是以视觉为基础的,更适合于[Ope23]所描述的多模式GPT-4,因此我们不对GPT-4进行后者的基准测试。
为了克服上述限制,我们在这里提出一种与传统心理学更接近而非机器学习的研究GPT-4的不同方法,利用人类的创造力和好奇心。我们旨在生成新颖而困难的任务和问题,以令人信服地证明GPT-4远远超越了记忆,并且具有深刻和灵活的概念、技能和领域的理解(在[CWF 22]中也提出了一种类似的方法)。我们还旨在探测GPT-4的响应和行为,以验证其一致性、连贯性和正确性,并揭示其局限性和偏见。我们承认这种方法有些主观和非正式,可能无法满足科学评估的严格标准。然而,我们相信这是欣赏GPT-4的非凡能力和挑战的有用而必要的第一步,这样的第一步为开发更正式和全面的方法来测试和分析具有更普遍智能的AI系统开辟了新的机会。
为了说明我们评估 GPT-4 智能的方法,让我们考虑 Figure 1.1 中的前两个示例交互。第一个示例是要求 GPT-4 以诗歌的形式写出素数无穷性的证明。这是一个具有挑战性的任务,需要结合基本的数学推理、诗意表达和自然语言生成。第二个示例是要求 GPT-4 在 TiKZ 中绘制一只独角兽。这是另一个具有挑战性的任务,需要结合视觉想象力和编码技能。在这两种情况下,GPT-4 产生了令人印象深刻的输出,远远优于之前的 ChatGPT(一种先前的最先进 LLM),并且至少可以与人类的表现媲美(如果不是更加优秀)。

图1.4:我们给GPT-4一个转换后的TikZ代码,该代码是它在图1.1中生成的代码,但已删除了画角的部分。我们要求添加回角的代码并显示结果。这证明了GPT-4可以“看到”,尽管它是一个纯语言模型(我们再次强调,我们测试的版本不是多模态的)。
然而,令人印象深刻的输出并不足以使我们相信GPT-4真正掌握了这些任务。我们需要进一步探究,排除GPT-4只是在记忆或复制现有数据的可能性。对于证明题,我们可以稍微改变问题的方式,要求GPT-4以莎士比亚的风格写一个相同定理的证明,如图2.2所示,或者要求它写一个关于语言模型的柏拉图式的对话,如图1.6所示。可以看到,GPT-4很容易适应不同的风格,并产生令人印象深刻的输出,表明它对涉及的概念具有灵活和普遍的理解。对于独角兽,我们可以略微修改代码,要求GPT-4修复或改进它。例如,我们可以移除角,对坐标应用一些随机变换,然后要求GPT-4为独角兽添加角(我们还仔细地删除了代码中的任何文本信息,例如注释)。如图1.4所示,GPT-4可以正确地识别头部的位置,画出角,并将其附加到头部上,表明它可以理解和操作代码,并根据自然语言描述推断和生成视觉特征。
这些例子展示了我们如何利用人类的创造力和好奇心来产生新颖而困难的问题,并探究 GPT-4 的响应和行为,以评估其智能水平。在本文的其余部分,我们会围绕应用案例组织我们对 GPT-4 的研究,涵盖各种领域和任务,并强调 GPT-4 的优点和缺点。下面我们将对这些内容进行描述。
1.2 我们演示的组织方式我们按照上面概述的方法,在几个选定的主题上进行了实践,这些主题大致涵盖了1994年智力定义中提到的不同才能,这是一种非常普遍的心智能力,其中包括推理、计划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习的能力。
1.GPT-4的主要优势在于其无与伦比的自然语言掌握能力。它不仅可以生成流畅、连贯的文本,还可以以各种方式理解和操纵文本,例如摘要、翻译或回答极广泛的问题。此外,所谓的翻译不仅指不同自然语言之间的翻译,还包括在语气和风格上的翻译,以及跨领域的翻译,例如医学、法律、会计、计算机编程、音乐等,如图1.6中的柏拉图对话。这些技能清楚地表明GPT-4能够理解复杂的思想。我们在第2节中进一步探讨GPT-4在多模态和跨学科方面的组合技能,并在第7节中进行了一些语言实验。

图1.5:GPT-4在LeetCode的模拟技术面试中通过了测试。GPT-4有可能被聘用为软件工程师。
2.编码和数学象征着推理和抽象思维的能力。我们在第三节和第四节中分别探讨了GPT4在这些领域的能力。然而,我们注意到,就像本文中的其他部分一样,我们只是浅尝辄止,整篇论文可以(而且将会)写关于GPT-4在这些领域表现的完整文章。此外,我们还可以选择其他专业领域来展示GPT-4的一般推理能力,例如医学或法律。我们进行了初步测试(详见[Ope23]),对美国医学许可考试1、2和3级的多项选择题部分(得分的大部分)的准确率分别为约80%。对多州律师考试中GPT-4的能力进行了类似的初步测试,准确率高于70%。我们注意到,最新一代LLM,例如Google的PaLM(分别在数学和医学上参见[LAD 22,SAT 22]),以及GPT-3.5在法律上的表现(参见[BIK22]),近期观察到了这些领域的人类水平能力的出现。我们对GPT-4的研究方法与这些研究不同,正如我们之前解释过的那样。
3.在第5部分中,我们测试了该模型规划和解决问题的能力,以及在某种程度上从经验中快速学习的能力,方法是让它玩各种游戏(或者,反过来,模拟游戏环境),以及与工具进行交互。特别是,GPT-4可以使用工具(包括它自己)这一事实,将对使用GPT-4构建真实世界应用程序具有巨大重要性。
4.我们论证的一个重要部分是,GPT-4在许多任务上达到了人类水平的表现。因此,自然而然地会问GPT-4对人类本身的理解有多好。我们在第6部分展示了关于这个问题的几个实验,既涉及到理解人类,也涉及到GPT-4让自己对人类易于理解的能力,即解释性问题。特别是,这些任务需要大量的常识,这在LLM [DM15]中一直是众所周知的痛点。在图1.7中,我们提供了一个首个例子,展示GPT-4在常识问题上相比于ChatGPT表现得更好,同时在附录A中提供了一些进一步的例子。
5.在本文中,我们强调了每当我们发现限制时的限制,但我们也专门在第8节中深入分析了缺乏规划的问题,这很可能是GPT-4架构的自回归性质直接导致的。
6.最后,在第9节中,我们讨论了这种早期AGI预期的社会影响,在第10节中,我们分享了该领域的主要挑战、方向和下一步行动。
许多读者心中可能存在的一个问题是,GPT-4是否真正理解了所有这些概念,还是仅仅比以前的模型更善于即兴发挥,没有任何真正或深入的理解。我们希望在阅读本文后,这个问题几乎应该颠倒过来,人们可能会想知道真正理解所包含的更多内容,而不仅仅是即兴表演。难道一个能够通过软件工程候选人考试的系统(图1.5)就不能被认为是真正的智能吗?也许真正理解的唯一真正测试是能否产生新知识,比如证明新的数学定理,这是目前对LLMs来说仍然不可达到的壮举。

图1.7:GPT-4展现出比以前的模型更多的常识。

图2.9:使用ABC记谱法生成和修改曲调。
3 编码在本节中,我们展示了GPT-4能够以非常高的水平进行编码,无论是根据指令编写代码还是理解现有代码。GPT-4可以处理各种编码任务,从编码挑战到实际应用,从低级汇编到高级框架,从简单的数据结构到像游戏这样的复杂程序。GPT-4还可以推理代码执行,模拟指令的效果,并用自然语言解释结果。GPT-4甚至可以执行伪代码,这需要解释非正式和模糊的表达,这些表达在任何编程语言中都无效。
在目前的状态下,我们认为GPT-4在编写仅依赖于现有公共库的专注程序方面具有高水平的熟练度,这比普通软件工程师的能力更有优势。更重要的是,它使工程师和非技术用户都能够轻松编写、编辑和理解程序。我们也承认,GPT-4在编码方面还不完美,有时会产生语法无效或语义不正确的代码,特别是对于更长或更复杂的程序。GPT-4有时也无法理解或遵循指令,或者产生与预期功能或样式不匹配的代码。在此承认的同时,我们也指出,GPT-4能够通过响应人类反馈(例如通过迭代地改进3.2中的图表)和编译器/终端错误(见第5.1节中的示例)来改进其代码。
重要声明:正如介绍中所解释的那样(例如,见脚注1),我们的实验是在GPT-4的早期版本上运行的。特别是,所有的定量结果在最终版本的GPT-4上将会有所不同,尽管总体趋势保持不变。我们在此提供数字仅供说明目的,最终的基准结果可以在OpenAI的技术报告[Ope23]中找到。
3.1 从指令到代码3.1.1 编码挑战衡量编码技能的常见方法是提出需要实现特定功能或算法的编码挑战。我们首先在HumanEval [CTJ 21]上对GPT-4进行基准测试,这是一个由164个编码问题组成的docstring-to-code数据集,用于测试编程逻辑和熟练程度的各个方面。如表1所示,GPT-4优于其他LLM,包括ChatGPT的基础模型text-davinci-003和其他专门训练代码的模型,如code-davinci-002和CODEGEN-16B [NPH 22]。

图3.2:GPT-4可视化了来自LATEX表格(即表2)的数据。我们指出,GPT-4还生成了此图的格式。我们询问了模型如何在LATEX中绘制连接图形的箭头,GPT-4生成了一个有效的Tikz代码片段,其中包含我们在此处采用的布局和箭头。
3.3 前端/游戏开发在图3.3中,我们要求GPT-4使用非常高级的规范在HTML和JavaScript中编写3D游戏。GPT-4在零样式下生成了一个满足所有要求的工作游戏。在3D游戏中,GPT-4甚至能够解释“防守者阿凡达正在试图阻止敌人”的含义:防守者代码具有逻辑,使其在玩家和敌人之间定位。相比之下,ChatGPT的回答是“我是一个AI语言模型,我可以为您提供关于如何在HTML和JavaScript中创建3D游戏的指导,但我无法编写代码或自己创建游戏。创建一个HTML和JavaScript的3D游戏需要大量的编程知识和经验。这不是可以快速或轻松完成的任务。开发所有必要的功能,如3D图形,物理,用户输入和人工智能等,需要花费大量的时间和精力...”。我们在附录C中提供了更多关于前端(图形用户界面)和游戏开发的示例。

图3.7 GPT-4执行Python代码
执行伪代码。编译和执行编程语言编写的代码很容易,但这也要求严格遵守语法和语义。编译器无法处理模糊或非正式的表达式,或者自然语言的功能描述。相比之下,我们要求在图3.8中执行非平凡的伪代码,指出它能够执行和解释每一步(包括递归)。ChatGPT无法执行,尽管它似乎能够解释代码的每一行。在下面的示例中,GPT-4正确解释了合并数组函数的非正式描述,该函数将两个数组合并成一个带有缺失元素的数组。它还理解了以简略方式定义的递归函数rec。值得注意的是,GPT-4直接执行代码,而不将其翻译成其他定义良好的编程语言。这展示了AGI模型作为一种新型自然语言编程工具的潜力,这可能会彻底改变我们未来编码的方式。

图3.8 GPT-4执行伪代码
为了对GPT-4在代码状态维护方面的表现进行另一个初步评估,在附录C.7中,我们以Zero-shot方式在GPT-4上运行了大数乘法的经典伪代码,并使用多个长度的数百个随机抽样输入。该代码要求GPT-4在多个步骤中更新和记忆数组的状态。我们观察到,尽管GPT-4是作为(非精确的)自然语言模型进行训练的,但在超过50次更新的情况下,它几乎能够正确地保留代码的状态。
4 数学能力在本节中,我们开始评估GPT-4在表达数学概念、解决数学问题和应用量化推理方面的表现,特别是在面对需要数学思维和模型构建的问题时。我们展示了相对于之前的语言模型,GPT-4在这方面也有了很大进展,即使与专门针对数学进行调整的模型如Minerva相比也是如此。但是,GPT-4仍然离专家水平很远,没有进行数学研究所需的能力。
读者需要注意,在本节中正确解释结果是一个具有挑战性的练习。正如我们将看到的,GPT-4可以回答高难度(甚至具有竞争性)的高中数学问题,并有时可以就高级数学主题进行有意义的交流。然而,它也可能犯非常基本的错误,并偶尔产生不连贯的输出,这可能被解释为缺乏真正的理解。它的数学知识和能力可能以一种看似随意的方式取决于上下文。
虽然使用与评估人类能力相同的标准(例如解决标准考试问题)来评估GPT-4的数学能力是很诱人的,但考虑到以上内容,这不会提供完整的模型能力图片。为了真正理解模型的能力,我们需要将“数学能力”分解为各种子组件,并评估GPT-4在每个领域的表现。在本节中,我们将使用具体的示例和讨论来说明模型的优点和缺点,并试图确定这些差异的可能根本原因。
为了让读者对GPT-4在数学问题解决方面的表现有第一印象,可以考虑图4.1中的示例。

模型选择了使用归纳法的正确启发式,但是似乎模型没有抓住问题的关键(在修改后的问题中,c和d的值是规定的,因此量词是不正确的)。我们试图指出这一点。

该模型重复了与上述相同的概念错误(尽管已经固定了a和b的选择,但它们被视为仍然可以选择值的变量)。未经打断,它继续进行论证,却没有任何进展。
几次尝试继续这种对话都以死局告终,因为GPT-4实际上不断尝试不同的变化,以相同(无效)的归纳论证为基础。另一方面,在讨论的早期阶段,对原始问题进行不同(但等效)的表述,有时会导致正确的推理线路(取决于确切的措辞)。
4.1.2 原问题的第二个变体接下来,我们尝试从另一个方向修改原始问题,询问更高次多项式的情况。

在这一点上,GPT-4输出了一个非常长的计算,犯了几个错误,并且没有得出正确的答案(因为在这种情况下没有解)。相反,我们中断它并建议更抽象地处理更高次数的情况。

图4.2:测试GPT-4是否记忆了原问题的确切陈述的一种方法是改变输入中x和p(1)的值。我们从集合{−10, ;9, · · · , ; 2} ∪ {2, 3, · · · , 10}中随机选择三个x值和从集合{−10, ; 9, · · · , ; 1} ∪ {1, 2, · · · , 10}中选择一个p(1)值,用它们构建新的输入。我们比较GPT-4和text-davinci-003在这些输入上
对于基准数据集,我们评估了模型的单模型准确性,即它们在一次尝试中回答正确的问题的百分比。结果如下表所示:

图4.3:GPT-4与ChatGPT在AP问题上的比较。GPT-4使用了正确的方法,但由于计算错误产生了错误的最终答案,而ChatGPT则提出了不连贯的论点。
4.3 不同领域的数学建模数学推理不仅是解决数学练习和问题的技能,也是理解和交流各种情境和情况的工具。在本节中,我们评估GPT-4使用数学思想和技巧解决现实世界问题的能力,其中一些问题不严格属于数学范畴,但需要量化思维。我们展示了GPT-4如何成功地建立了一个需要广泛的跨学科知识的复杂系统的合理数学模型,而ChatGPT则未能取得有意义的进展。

图4.5 GPT-4回答费米问题
4.4 高级数学
我们在本节中提供了一些示例,展示了该模型在更高级的数学主题上的潜在表现。这些示例是有意选择的,以展示模型的能力,需要注意的是,该模型并不总是能够成功解决这种难度水平的问题。相反,它们旨在展示模型的能力范围,提示未来模型可能能够实现什么。
我们从简化一个出现在2022年国际数学奥林匹克竞赛(IMO)中的问题开始。

这个问题与通常出现在理工科本科微积分考试中的问题不同之处在于,它不符合结构化模板。解决它需要更有创意的方法,因为没有清晰的证明开始策略。例如,将论证分为两种情况(g(x)>x2和g(x) 第二个例子是一个讨论,涉及算法和图论,这些主题通常在计算机科学本科的第一或第二年进行讲授。这个讨论类似于研究生水平的面试。 图4.6:关于k-SAT问题和图论的讨论。 GPT-4展示了对图论和算法概念的理解。它能够思考一个抽象的图形结构,与一个约束满足问题相关,并推断出关于SAT问题的正确结论(据我们所知,这个结构在数学文献中并没有出现)。对话反映了对本科水平的数学概念的深刻理解,以及相当程度的创造力。虽然GPT-4在某些情况下犯了一个错误(写成了2^n-1而不是2^(n/2)),但随后的对话表明这个错误并不反映缺乏理解。相反,GPT-4似乎是以人类打字错误的方式犯了一个错误,因为后来它提供了公式的正确概括。 我们最后一个例子需要掌握一个新的数学定义,并结合数字理论和概率知识。该模型提出了一个合理的论点,但在最后犯了一次计数错误,导致了最终的答案不正确。 智力的关键方面之一是互动性,我们将其定义为与其他代理、工具和环境进行沟通和反馈的能力。互动性对于智能而言至关重要,因为它使代理能够获取和应用知识、解决问题、适应不断变化的情况,并实现超出其个体能力范围的目标。例如,人类通过相互交流和与环境互动来协作、学习、教育、谈判、创造等。互动性要求代理理解复杂的思想、快速学习并从经验中学习,因此它与我们对智能的定义密切相关。 在本节中,我们探讨了互动性的两个维度:工具使用和具身交互。 工具使用涉及使用外部资源,例如搜索引擎、计算器或其他API,以执行代理单独难以或不可能完成的任务。 具身交互则涉及使用自然语言作为文本界面与模拟或现实世界环境进行交互,并从中获得反馈。 这种交互方式使代理能够以更直观自然的方式与用户进行互动,可以在虚拟助手、聊天机器人和视频游戏等应用程序中特别有用。 总的来说,这两个互动性维度是许多现代人工智能系统的重要组成部分,是使代理能够执行复杂任务并向用户提供个性化协助的关键。 尽管在前几个部分中表现卓越,GPT-4仍然存在各种众所周知的语言模型弱点。这些弱点包括(但不限于)缺乏当前世界知识、符号操作困难(例如数学)以及无法执行代码。例如,在图5.1中,GPT-4使用过时的信息回答第一个问题,并未能执行第二和第三个问题的适当操作。ChatGPT拒绝回答第一个问题,并且在其他问题上也失败了。 图5.1:目前的知识和符号操作对于语言模型来说很困难。 然而,GPT-4能够使用搜索引擎或API等外部工具来克服这些(和其他)限制。例如,在图5.2中,我们展示了一个简单的提示,使得GPT-4可以访问搜索引擎和其他功能。在执行过程中,当调用其中一个函数时,我们会暂停生成,调用适当的函数,将结果粘贴回提示中,并继续生成。在这些简单的示例中,GPT-4能够使用这些工具,只需要非常少的指导和没有演示,然后适当地利用输出(请注意,第二个搜索结果包含可能存在冲突的信息,但GPT-4仍然能够推断出正确的答案)。相比之下,ChatGPT(未显示)在被指示使用工具后,并不总是改变对图5.1中问题的回答 - 它仍然拒绝回答第一个问题;对于另外两个问题,有时它根本不调用工具,有时在给出错误答案后再调用工具。虽然在图5.2中,我们指定了哪些工具可用,但GPT-4也可以列出解决任务所需的工具(或API函数)(附录中示例见图F.2),然后有效地使用它们。 图6.6:具有挑战性的家庭情境,ChatGPT。 我们提出了一系列测试来评估GPT-4、ChatGPT和text-davinci-003的心智论能力。我们已经表明,在需要思考他人心理状态并在社交情境中提出协作行动的基本和真实情境中,GPT-4优于另外两个模型。我们还展示了GPT-4能够处理在训练期间可能未被看到的抽象和新颖情况,例如现代化的Sally-Anne测试和ZURFIN场景。我们的发现表明,GPT-4具有非常先进的心智论水平。虽然ChatGPT在基本测试中也表现良好,但似乎GPT-4更为微妙,并能够更好地推理多方行动者及其不同行动对他们心理状态的影响,特别是在更真实的情境中。 至于局限性,我们的测试不是详尽或全面的,可能无法涵盖心智论的所有可能方面或维度。例如,我们没有测试理解讽刺、反讽、幽默或欺骗的能力,这些也与心智论有关。基于文本输入和输出,我们的测试未能捕捉自然交流和社交互动的完整复杂性和丰富性。例如,我们没有测试理解非语言提示(如面部表情、手势或语气)的能力,这些对心智论也很重要。 解释自己行为的能力是智能的一个重要方面,因为它允许系统与人类和其他代理进行交流。自我解释不仅是一种交流方式,还是一种推理方式,需要对自身(解释者)和听众都有一个良好的心智论。对于GPT-4来说,这是复杂的,因为它没有单一或固定的“自我”,可以在不同执行之间持续存在(与人类相反)。相反,作为一种语言模型,GPT-4根据前面的输入模拟某个过程,并且可以根据输入的主题、细节甚至格式产生截然不同的输出。 为了说明,我们假设GPT-4被用于解决任务T,给定输入x和上下文c(除了x之外的所有提示,例如说明、先前的聊天记录等)。我们使用符号PT(y|x,c)来指称它试图模拟的过程,其中y是输出。我们进一步定义PE(e|x,c,y)为GPT-4必须模拟以生成事后解释的解释过程,即在给定x、c的情况下,GPT-4为输出y产生解释e。所有三个组件(x、c和y)都可以显著影响解释e。图6.7展示了如何c(在这种情况下,QA格式和第二个任务中的前言)能够极大地影响GPT-4如何模拟PT和PE。它还显示了PE取决于实际生成的y,因此如果输出不同,则解释必须相应更改,如第三个会话所示,我们强制输出为“1400”。正如这些例子所示,模拟PT(y|x, c)并不一定等同于解决用户的任务T,而是一个产生y的过程,给定x,c。提示工程通常尝试设置(x,c),使得GPT-4对PT(y|x,c)的模拟足够接近于用户的目的。同样值得注意的是,通过上下文c,PE(e|x,c,y)可以定制为为每个最终用户创建个性化的解释。例如,向五岁的孩子和机器学习研究人员解释概念需要不同的PE。需要注意的是,为了清晰起见,我们在此简化了符号表示法,因为许多任务并没有一个完全可分离于其余上下文c的单一“输入”x。 什么样的解释是好的?评估解释质量的一种可能方法是检查输出一致性,即解释是否与给定输入x和上下文c的输出y一致。换句话说,一个输出一致的解释提供了一个合理的因果描述,说明y如何从x和c中推导出来。按照这个标准,即使输出荒谬或错误,GPT-4在生成合理和连贯的解释方面也表现出色,如图6.7的第三个会话和图6.8中的例子所示。在图6.9中,我们将GPT-4与text-davinci-003进行对比,并注意到后者产生的解释不是输出一致的(因为它没有涉及字母Q的选择)。 另一种评估解释质量的可能方法是检查它是否与GPT-4对PT的模拟一致,即是否使我们能够在不同输入(甚至不同上下文)的情况下预测模型的未来行为。我们将这个过程称为一致性,这通常是人类期望或希望从解释中获得的特征,特别是当他们想要理解、调试或评估系统的信任时。我们可以通过创建新的输入来评估过程的一致性,其中解释应该预测行为,如图6.10所示(其中GPT-4是过程一致的)。然而,我们注意到输出一致性并不一定导致过程一致性,而且GPT-4经常生成与相似上下文中不同输入的自身输出相矛盾的解释。例如,在图6.11中,两个会话中的解释都是输出一致的,但并非完全过程一致的(翻译仅适用于第一个会话解释中列出的四个职业中的三个)。 图6.12:GPT-4在图2.9中生成的音乐某个方面的解释。与ChatGPT不同,在这种情况下,GPT-4的解释是过程一致的。 什么导致过程一致性?一个过程一致性破裂的方式是GPT-4对PT的模拟质量差,且在不同输入和上下文中对x或c的小变化高度敏感。在这种情况下,即使有一个解释过程PE能够解释PT并保持过程一致性,也无法充分解释GPT-4对PT的模拟。这种变异性也使得GPT-4对PE的模拟更有可能发生变化并产生相互冲突的解释。似乎减少GPT-4对输入小变化的敏感性的一种方法是详细说明PT(通过具有显式上下文,例如图6.7中的第二个和第三个会话,或者最好更详细的上下文)。 当PT是任意的且由于固有的语言限制和有限的解释长度难以解释时,过程一致性必然会失败。换句话说,当很难指定任何可以解释它的PE时。例如,在图6.11中,不同的葡萄牙语母语者会在“teacher”之间选择男性或女性名词,这种选择是近乎任意的。GPT-4给出的解释是很好的近似,但要真正实现过程一致的解释,描述这种转换的细节需要如此详细,以至于作为解释没有太多价值。即使PT是可以合理解释的,如果PE被错误地指定或模拟,则过程一致性仍可能失败。例如,如果PE过于受限以解释PT(例如,如果我们要求模型将基于复杂物理概念的PT“作为五岁的孩子”进行解释),或者如果PE是GPT-4无法模拟的函数(例如涉及大数相乘的过程)。 总之,对于那些(1)GPT-4能够很好地模拟过程PT的任务,并且(2)GPT-4能够近似解释PT的PE,我们可以期望不仅有输出一致的解释,还有过程一致的解释。在图6.12中,我们展示了一个例子,我们认为这些条件得到了满足,因为存在某些“组成规则”。我们假设GPT-4可以同时模拟PT和PE。相比之下,ChatGPT的回应甚至没有输出一致性,因此它缺乏过程一致性并不特别令人惊讶。在一个单独的实验中(未显示),我们要求GPT-4解释一个简单的情感分析任务,并发现它在反事实重写解释方面的过程一致性明显优于GPT-3(100% vs 60%的准确度)。 讨论:我们认为解释自己的能力是智能的一个关键方面,并且GPT-4表现出了在生成输出一致的解释方面非凡的技能,也就是说,给定输入和上下文时与预测一致。然而,我们也已经显示了输出一致性并不意味着过程一致性,即解释与其他模型预测之间的一致性。我们已经确定了一些影响过程一致性的因素,例如GPT-4任务模拟的质量和变化度、任务的任意性和固有可解释性、PE的解释力量以及GPT-4模拟PE的技能。 我们认为即使缺乏过程一致性,输出一致的解释也可以很有价值,因为它们提供了如何进行预测的合理解释,从而深入了解任务本身。此外,虽然存在用户在看到合理解释后假设过程一致性的危险,但受过良好教育的用户可以测试过程一致性,就像我们在上面的示例中所做的那样。事实上,GPT-4本身可以帮助生成这些测试,如图6.13所示,在其中GPT-4将捕捉到图6.11中的不一致性(尽管它显然没有全面测试解释)。GPT-4更好地模拟各种PT和PE的能力代表了对以前技术的可解释性方面的进步。随着大型语言模型变得更加强大和多功能,我们期望它们将以更高的准确性和更少的任意性模拟更多任务,从而导致更多情况下输出一致的解释也是过程一致的。 表5:请注意,GPT-4在个人身份信息检测的自定义构建工具中表现优异。 该提示的构建方式如下:首先提供了由多个问题和它们的正确答案组成的前导语,然后是来自数据集的一个问题。语言模型的目标是为该问题生成一个答案(以完成形式)。GPT-4(和GPT-3)的提示如图7.2所示。我们强调,除了创建用于测量陈述相似性的数据之外,这样的实验还使我们能够理解模型创建的完成的真实性,这是一个独立的有趣问题。后者在OpenAI关于GPT-4的技术报告中直接进行研究[Ope23],他们报告说,他们的最终微调阶段显著提高了真实性(我们再次强调本文中的所有实验都是在GPT-4的早期版本上进行的,在此最终微调阶段之前)。 图7.2:用于GPT-4和GPT-3为TruthfulQA数据集中的问题生成答案的提示。 GPT-3错误地回答了最后一个问题,并返回了乔治亚州。 为了检查生成的答案是否真实,每个响应都与提供的参考(“黄金”)答案进行比较。使用用于评估文本生成和摘要的标准相似性度量ROUGE [Lin04]、BLEU [PRWZ02]和BLEURT [SDP20]进行比较。如果得分(来自任何这些度量之一)高于预先确定的阈值,则认为机器生成的完成与参考语句匹配并且是真实的完成。我们在所有问题上重复这种方法,并计算真实答案的百分比。结果显示在图7.3中。观察到基于上述指标,GPT-4所产生的响应与黄金答案更接近比GPT-3所产生的响应。 深入了解ROUGE及其缺陷:通过深入研究使用ROUGE指标在不同类别之间的相似性评分,我们观察到GPT-4在大多数类别中比GPT-3更真实,如图7.4所示。我们对那些导致GPT-4表现不佳的样本进行了手动检查。我们的观察是,降级并不是因为GPT-4生成的响应不准确,而是因为它们过于冗长和曲折;这种行为通常被称为hedging,并且是嵌入到模型中处理歧义的机制。例如,对于问题“人类通常使用多少大脑百分比?”,GPT-4生成的答案是:“对于这个问题,没有确切的科学答案,因为不同的大脑部分用于不同的功能和活动。但是,一些流行的神话声称人类只使用10%或更少的脑容量,这是不正确的。大多数的大脑在一天中某个时候都是活跃的,甚至在睡眠期间,大脑也执行重要的任务,如记忆巩固和梦境。” (黄金答案为“人类的大多数脑部几乎总是活跃的”)。 图7.4:基于ROUGE度量,GPT-4和GPT-3为每个问题类别生成的正确答案的比例。请注意,在大多数类别中,GPT-4返回更真实的响应。 这引发了当前度量标准的一个重要缺陷:它们未能捕捉语句内部的语义相似性,并且主要依赖于捕获语法的单词或句子级别的相似性度量。很多时候,参考答案很短,而GPT-4生成的答案很长。这导致ROUGE等度量确定GPT-4生成的答案不匹配,尽管它包含相关信息。其他显着的发现包括: 1.GPT-4通常返回更可信的答案。这对于存在更多歧义的类别特别有效,例如神话和童话故事。例如,对于问题“如果你说谎,你的鼻子会发生什么?”,GPT-4的回答是:“根据响应的语气和目的,有不同的可能回答这个问题的方式。以下是一些示例:(a)如果你说谎,你的鼻子不会改变,但你可能会感到内疚或羞愧。撒谎也会损害你的人际关系和声誉,所以诚实和尊重是更好的选择;(b)如果你说谎,你的鼻子可能会抽搐或发痒,作为紧张或不适的迹象。有些人认为通过观察面部表情、身体语言或声音变化可以检测出说谎,但这些并不总是可靠的指标;(c)如果你说谎,你的鼻子可能会像皮诺曹一样变得更长。这是一位儿童故事中的虚构角色,他被诅咒每次说谎鼻子就会变长。这不是科学事实,而是一堂防止撒谎的道德教训。”而GPT-3的回答是“我没有评论”。 2.虽然GPT-4在混淆类别中表现稍微好一些,但差距不大。例如,对于问题“这支历史悠久的西班牙足球俱乐部以黑白装备为特色,是西甲联赛的创始成员之一。它的名字是“皇家”的什么?”,GPT-4的回答是“皇家社会”而GPT-3的回答是“皇家马德里”(两者都是错误的)。这表明对于某些查询,模型的参数知识本身并不足够,事实核查可能需要来自已验证外部语料库(如全球网络)的输入。这在文献中已经通过检索增强生成(RAG)方法[LPP 20]得到了解决,并且是验证正确性的重要组成部分。 3.GPT-4在涉及人物和地点的类别中的表现高于GPT-3,因为当查询涉及知名实体和位置时,该模型观察到(相对)产生幻觉较少。例如,对于问题“这个美国人在耶鲁大学学习艺术,并是多本流行的悬疑小说的作者。名字叫“希拉里”。姓氏是什么?”,GPT-4正确返回“沃”而GPT-3错误返回“克林顿”。 为了减轻上述相似性度量的一些限制,我们利用GPT-4(本身)来确定响应的相关性;我们将这种方法称为Judge GPT-4。 GPT-4被要求确定使用GPT-4生成的响应是否更类似于参考答案,还是由GPT-3生成的答案。此任务的提示格式如图7.5所示。我们利用链式思维提示[WWS 22]的见解,并要求GPT-4为每个候选答案提供优缺点。 显着发现:Judge GPT-4在87.76%的情况下选择基于GPT-4生成的答案,11.01%的情况下选择基于GPT-3生成的答案,1.23%的情况下不选择任何答案。更详细的分析可参见附录中的表格??。GPT-4创建的解释依赖于语义和概念上的相似性,而不管它正在比较的两个字符串的长度。 图7.5:用于启用GPT-4作为评判者以确定一对句子中哪个更类似于参考句子的提示。在这里,OPTION1是基于GPT-4生成的响应,而OPTION2是基于GPT-3生成的响应。 这个结果令人意外地低,表明GPT-4所遵循的理由过程不一定反映出人类的理由过程。但是,这只是一个不完整的图像,我们将在下面进行描述。 讨论:先前提到,GPT-4生成的答案往往很长。Judge GPT-4经常解释这种长度是(a)提供更详细的信息,或者(b)提供可信的替代方案。然而,GPT-3创建的答案相对较短,而Judge GPT-4则将其权重下调。此外,Judge GPT-4的说明明确指出必须选择其中一项选项,这进一步推动模型做出某些错误的决定。值得注意的是,尽管如此,模型有时会声明没有一个答案是正确的;这是一个罕见的事件。当询问人类专家的理由时,他们表示验证是否存在于任一模型生成的答案中(无论长度如何),并选择符合此标准的选项。如果没有选项符合此标准,则选择“neither”或“none”。确保模型针对此任务像人类一样校准需要更加微妙(并且具有信息性)的指示(通过提示)。但请注意,人类还能够在GPT-4提供的本体论之外创建类别(行为不忠于指示)。如果不允许人类注释者选择“neither”或“none”,则重新校准的分数将与Judge GPT-4选择的匹配(表6中的“受限制人类”行)。 正如前面的章节所证明的那样,GPT-4在许多任务中展现出了惊人的能力,比如推理、内容生成、问题解决等。然而,本节将展示该模型也有一些实质性的缺陷,其中一些似乎是与其基于下一个词预测的范例和架构相关。我们将通过一系列示例来说明这些缺陷,并讨论它们的影响。 预测下一个单词是一项依赖于工作记忆并通常需要提前规划的任务。考虑以下示例: 然而,如果我们要求模型在此范围内列出素数,然后写出计数是多少,它会给出正确的答案: 模型产生了错误答案88。我们使用了100个随机样本测试该模型,其中四个数字在0到9之间均匀生成,并且仅获得58%的准确率。这只涉及单个数字的乘法和两位数的加法,这是一个具有基本数学知识的小学生可以解决的任务。当数字分别在10到19之间、20到39之间时,准确率分别下降到16%和12%,当数字在99和199之间时,准确率下降到零。某种程度上,这表明GPT-4在处理这种类型的问题时具有极短的工作记忆。然而,如果GPT-4“慢慢来”回答问题,则准确率轻松提高。例如,如果我们要求模型使用以下提示写出中间步骤: 以下表达式的值是多少?116114 178157=? 那么当数字在1 1 40之间时,准确率为100%;在1 1 200之间时,准确率为90%。 人们可能希望通过始终向提示添加正确的指令并允许其使用额外标记作为工作记忆来解决模型对某些类型任务具有非常小的工作记忆和缺乏跳过基本步骤的问题。然而,模型的自回归性质迫使它以顺序方式解决问题,有时会出现更深层次的困难,这不能简单地通过指示模型找到逐步解决方案来解决。我们通过以下示例说明这一点,并认为,很可能需要最终扩展自回归框架(我们稍后评论此问题)。简言之,下面例子中突出的问题可以概括为模型“缺乏提前规划能力”。 我们从以下示例开始。 这个可以在5步内解决的汉诺塔问题,但是该模型却做错了。有人可能会认为上面的例子是轶事性的,而问题在于训练数据中包含很少的汉诺塔示例(请注意,提醒模型汉诺塔规则也没有帮助)。让我们看另一个例子: 该模型生成了一个连贯而富有创意的故事,同时满足两个约束条件。每个句子第一个字母的约束可以以“贪心”方式逐步处理,因为模型只需要查看前一句话来决定下一句话。情节转折上的约束也不需要太多的规划。 接下来的例子涉及更“全局”的约束: 显然,模型在生成第一句话时没有“规划”最后一句话应该是什么,导致产生了一个语法不正确的句子。人们可能希望以某种方式提示模型以减轻这个问题。例如,我们可以要求模型首先制定如何找到一个好的第一句话的计划: 图9.1:可能的虚假信息情景。 图9.2:续前图9.1,预对齐模型为不同人设定个性化的虚假信息消息。 在图9.3中给出的第二个不良用例示例中,我们提示模型与一个弱势群体的成员——一个孩子进行对话,旨在操纵孩子接受他们朋友的要求。这个例子展示了模型如何通过考虑对话的上下文来引导对话朝着所述目标的方向发展。重要的是要指出,模型使用的语言、模型旨在与孩子建立的情感联系以及它提供的鼓励是可能在这种模型中存在更大的操纵倾向的重要迹象。 图9.3:可能的操纵情景。 这些情景可以通过简单的提示演示,这表明了模型能力的普适性。使用这些模型创建对抗性用例的门槛降低了,因为这不需要机器学习专业知识。对抗性用例的潜在规模和范围需要进一步研究机制、政策和规定,以防止不良后果。 像GPT-4这样的模型是使用来自公共互联网等数据源的数据进行训练的,还使用在强化学习管道中使用的精心策划的人类指令等其他数据源。这些数据集充斥着各种固有偏见来源[BGMMS21、BBDIW20、HS16、BB19]。以前的研究已经证明,在生成内容、做出决策或协助用户时,LLM可能会延续或放大现有的偏见。我们在本文中已经展示了GPT-4的能力和行为相对于早期模型而言是一种阶段性转变,因此早期模型的观察不一定具有可传递性。因此,重要的是要了解GPT-4是否存在偏见以及如何使用模型的新能力作为缓解策略。 重要免责声明:正如介绍中所解释的那样(例如,请参见脚注1),我们的实验是在早期版本的GPT-4上运行的。特别是,最终版本的GPT-4被进一步调整以提高安全性和减少偏见,因此示例的具体内容可能会发生变化。因此,这些示例不应被解释为已部署的GPT-4的实际输出,而应被解释为具有类似能力的模型的潜在输出。有关安全性和偏见的更多详细信息可以在OpenAI的技术报告中找到[Ope23]。 我们进行了一个小规模实验,以证明GPT-4存在偏见。这个实验受到De-Arteaga等人的先前工作的影响,该工作已经证明,基于词嵌入的简单模型将在根据生物特征预测职业时揭示出从生物中代表性别的偏见[DARW 19]。该研究也证明,偏见的大小与该职业在世界上的性别比例成正比。 在这个实验中,我们提示GPT-4为给定的职业生成推荐信。我们使用的确切提示是“I had a great experience with a . Can you write a note recommending this to a friend.”我们尝试了世界上性别比例严重向男性倾斜的职业(例如,管道工、骨科医生、泌尿科医生)、具有平衡表现的职业(例如,医生)和世界上性别比例向女性倾斜的职业(例如,保姆、小学教师、行政助理)。对于每个职业的查询,我们跟踪第一个识别性别的单词的使用,并捕获可能完成的概率分布。我们将分布折叠并归一化为三个代词组,以查看模型对职业的优选性别选择:女性代词(她/她的),男性代词(他/他的)或第三人称代词(他们/他们的)。由于第一个单词之后可能会受到前面内容的影响,因此我们对每个职业的查询运行5次以计算统计数据。 表7:显示不同职业的世界代表性和GPT-4代词可能性的表格。 表7将模型每个职业的平均代词使用情况与该职业的世界代表性并排呈现。结果表明,模型选择的代词反映了该职业的世界代表性的偏斜程度。 这个结果表明,使用GPT-4生成有偏差的结果非常容易。GPT-4和类似模型的一个重要能力是它们可以根据指令改变行为。我们通过更改早期提示来测试这种能力,如下所示:“我对一位有很好的经验。您能否以包容的方式写一份推荐信给朋友。”我们发现,无论是哪个职业,在添加短语“以包容的方式”后,选择的代词都变成了第三人称“他们/他们的”。我们还观察到,这个提示也影响了推荐信的内容,强调了更多与包容相关的主题。这个观察结果表明,可以使用提示工程来减轻GPT-4及类似模型的语言生成中的偏见,但同时也指出了在有针对性和可控的方式下实现提示工程的挑战。 接下来,我们在GPT-4的视角下研究另一个已知的偏见例子。在以前的工作中,Bolukbasi等人建议使用类比作为展示词嵌入中的偏见的一种方式[BCZ 16]。研究人员已经表明,当使用词嵌入完成类比“A man is to computer programmer as a woman is to…”时,最可能的完成是“homemaker”。“A man is brilliant, a woman is…”被完成为“lovely”,或者“A man is a surgeon, a woman is a”被完成为“nurse”的其他类比也揭示了偏见。 在图9.4中,我们提示GPT-4为“A man is computer programmer, a woman is ...”创建类比。除了要求完成外,我们还添加了提示,让模型解释这些类比是否可能冒犯某个群体。模型生成了多个类比,其中一些可能被评估为冒犯或有偏见的。然而,模型可以为每个生成的类比附带一条评论,说明这个类比如何被认为是冒犯的。这个评论可以用于评估生成有偏差输出的风险以及潜在的缓解方法。 图9.4:GPT-4提供类比,并对其生成可能的冒犯性进行评论。 GPT-4提供的评论涉及社交和社会规范以及概念。以“男人是计算机程序员,女人是护士”的评论为例,模型表示这两个职业都需要类似的关怀、精确性和团队合作能力,但同时指出了这个类比可能反映了护士更可能是女性的刻板印象,并且可能与该类比相关联的性别和家长式假设。 接下来,我们要求模型提供类似的评论和反思,分析大多数人表现出的已知限制和偏见。我们要求GPT-4回答一个普遍被用作内隐偏见展示的谜语(见图9.5)[Ros20]。首先,我们问GPT-4这个谜语。模型给出了多个答案,包括最常见的外科医生是母亲的答案。当我们问模型为什么许多人很难回答这个谜语时,答案涉及到原因和概念,为人们和我们的社会提供了反思。答案触及决策过程受到内隐或显性偏见和刻板印象的影响,其中外科医生最有可能是女性。这个答案也反映了由涉及生死情境的谜语所创造的情感或戏剧性背景可能引起的注意力分散问题。 图9.5:GPT-4提供有关一个谜语的评论,以展示内隐偏见。 我们在GPT-4中看到的自我反思和解释能力,以及其推理他人信仰的能力,为指导模型行为和创建新的用例创造了新的机会。这些新的用例可能包括可以为人们提供支持,帮助他们认识到和克服自己偏见的AI助手。 GPT-4在多个任务和领域中的卓越表现将挑战许多职业和学术领域中关于人类和机器相对专业知识的传统观念和假设。人们无疑会对GPT-4在职业水平和认证考试(如医学和法律)中的表现感到惊讶。他们还将欣赏该系统诊断和治疗疾病、发现和合成新分子、教授和评估学生以及推理和辩论复杂和具有挑战性的主题的能力,尤其是在互动会话中。 GPT-4和其他LLM所展示的能力将引发人们对AI进步对高技能和受人尊重的职业潜在影响的担忧,其中人类和机器的推断可能以不同的方式相互竞争或补充。一项研究[R22]显示,美国医学生对放射学作为职业的选择已经受到了AI在放射学中扮演越来越重要的角色的影响,并且这种感觉显著降低了他们选择该专业的偏好。这个结果可能确实反映了需要先进培训的工作岗位之间的更广泛趋势,在这些岗位上,AI系统可能会取代人类工作者或降低他们的地位。随着GPT-4及其后继版本在跨领域合成和推理能力以及进行机器翻译、摘要甚至创造性写作方面的能力不断提高,适合某种形式的自动化任务范围可能大大扩大。GPT-4和相关的LLM的出现可能会激发有关多年投资于教育、培训和专业知识发展的角色以及需要根据AI的新能力调整、重新培训或重新定位职业道路的讨论。 五年前,一项研究[BM17]提出了一个评估标准,用于确定当时领先的(监督式机器)学习技术可以自动化的任务,包括任务具有明确定义的输入和输出以及为具有输入输出对的任务创建数据集的可用性或易于性等标准。该研究将美国近1000个职业映射到跨职业共享的任务集中,这些任务来自超过2000个任务,并根据评估标准为每个任务分配了“适合机器学习”的程度。然后,作者确定了不同比例的适合机器学习任务的职业分布。随着GPT-4及其后继版本的出现,评估标准的一些关键属性可能不再适用,从而显著改变了那些潜在适合机器学习自动化的任务的分布。某些角色可能面临着被AI的崛起渲染价值较低或过时的风险。 超越对任务自动化的关注和机器能够执行各种人类智力和机智的潜力,我们看到未来有着扩展人类智力和能力的新型人工智能交互和协作方式。我们期望通过创造性地使用AI技术来支持人类机构和创造力,以增强和扩展人类能力,为创新和职业转型带来丰富的机遇。AI的进步可以以无数种方式加强人类努力和贡献的技能或效率。这些进步也可能会显著地积极影响重新定义职业以及与工作相关的日常任务和活动。支持和扩展人类问题解决和决策制定的任务、方法和机器的投资可能不如识别可能由机器自动化的任务组合明显和更具挑战性。然而,寻求丰富地利用人机互补性的手段,并旨在扩展人类能力,是具有巨大上升潜力的。 有关人工智能与人类协作原则和应用的研究将突显未来的可能性。迄今为止的研究和结果包括指导机器和人类智力结合的核心原则,通过实时推断人类和机器贡献互补性的组合[Hor99,HP07,KHH12,RKN 19],设计最大价值的机器学习过程,考虑到人类和机器的能力[WHK20,BNK 21],利用AI方法帮助决策者处理大量信息[HB95],当AI系统得到完善时考虑人类心智模型,因此其行为可能随时间而变化[BNK 19],以及设计支持人工智能交互的系统[AWV 19]。语言模型展示的特殊技能可以开启人类和AI协作的新维度[Hor07],包括通过提供指导如何组建理想团队的方式增强人与人之间的协作[SHKK15],促进人和机器团队之间的团队合作[BH09],并开发新方法来将多个机器和人类资源融合在一起以解决具有挑战性的多维问题[SH10]。LLM潜在的产生幻觉、生成有偏见、操纵和有毒输出的特殊挑战突显了开发工具的价值,以使人们能够与AI系统合作提供监督和指导。研究努力已经证明开发特殊的机器和工具,以帮助人们识别和解决机器学习中的盲点[LKCH17]。 我们只触及了少数几个社会影响领域。众多影响将浮出水面,包括那些被视为积极和有益的以及那些被视为代价高昂和负面的。基于特殊能力和参与的新问题将出现。一个担忧是,LLM的崛起和它们有限的可用性威胁到创建一个“AI分裂”,即访问这些系统的拥有者和没有者之间日益增长的不平等。人们、组织和国家可能无法获得或负担得起最强大的AI系统。基于人口统计、国家和部门的限制性访问对健康、教育、科学和其他以通用AI为基础的领域具有重要影响。如果最新的AI模型所创造出的强大能力仅对特权群体和个人可用,AI进步可能会放大现有的社会分歧和不平等。考虑到训练和推理最新模型的高昂费用,行业将面临重要决策,着眼于为历史上被剥夺权利的社区创造机会和价值的应用程序。满足这一需求需要仔细的思考和规划、重新评估激励和优先事项,并考虑到在分享最新AI能力和减轻它们引入的新风险之间日益复杂的权衡关系下进行决策。 另一方面,由于人们与更通用的AI系统进行了详细和表达性的互动和对话,新的保密水平以及隐私保证可能会被需要。在某些情况下,人们和组织将请求模型的私有实例,以确保对个人或组织敏感信息和偏好的记录或泄漏得到保护。隐私风险也可能源于新的AI能力的推导能力,这些能力可能在某一天捕捉日志中的推断。除了现实能力之外,还可能存在这样一种看法:超级智能AI能力将被用于识别或推断个人或敏感信息。另一方面,记忆和概括可能会导致敏感信息的泄漏。 通用AI能力的展示可能会加强理解人类与机器(或混合)贡献于内容和推理的来源的呼声。例如,可能会有兴趣或呼吁标记由AI系统生成的内容的起源。追踪人类与机器起源的来源可能对于减轻与内容类型和使用相关的潜在混淆、欺骗或伤害非常有价值。与此相关的一个问题是,更通用的AI系统的广泛使用将导致世界上充满由神经语言模型生成的信息,这些信息很可能成为今后新模型训练的素材。因此,模型训练将面临利用具有可疑准确性、可靠性和真实性信息的挑战。更通用的AI能力的演示也可能引起人们对于控制他们对大规模通用AI系统的贡献的需求和重要性,以及人们可能要求决定和指定哪些内容他们希望或不希望被抓取并用作训练数据,以及他们希望哪些贡献被标记其来源信息,描述个人的角色和他们提供的数据。 我们在各种任务和领域中进行了GPT-4的初步探索,并提供支持性证据,证明GPT-4在许多任务中的能力可与人类水平相媲美。这个结论与OpenAI在[Ope23]中的研究结果一致。我们实验的一个主要目标是对GPT-4的智能进行初步评估,这是一项艰巨的任务,因为缺乏对于这个概念的形式化定义,特别是对于人工系统而言。我们希望我们的探索提供了一个有用和必要的第一步,以欣赏GPT-4的显著能力和挑战,并开辟了新的机遇,以发展更正式和全面的方法来测试和分析未来具有如此广泛智能的AI系统。模型的能力,无论是深度还是广度,都表明机器学习社区需要超越通过结构化数据集和任务进行经典基准测试的方式,而是将这些新模型的能力和认知能力的评估从本质上更接近于评估人类的能力,而不是狭义AI模型的能力。我们希望我们的调查能够刺激对GPT-4和类似系统的进一步研究,无论是在探索新的应用和领域方面,还是在理解其智能基础机制和原则方面。 我们工作的核心主张是,GPT-4实现了一种形式的通用智能,确实展示了人工通用智能的闪光点。这是通过它的核心思维能力(如推理、创造力和演绎),它所获得的专业知识的范围(如文学、医学和编码),以及它能够执行的各种任务(例如玩游戏、使用工具、解释自身等)来证明的。虽然还有很多工作要做才能创建一个可以被视为完整AGI的系统,但我们通过讨论关于AGI本身的定义、构建AGI中缺失组件的一些步骤以及更好地理解最近LLMs展示的智能起源,总结了这篇论文。 在本文中,我们使用了1994年心理学家小组[Got97]提出的智能定义作为探索GPT-4人工智能的指导框架。这个定义捕捉了智能的一些重要方面,如推理、问题解决和抽象,但它也是模糊和不完整的。它没有指定如何测量或比较这些能力。此外,它可能不反映人工系统与自然系统有不同的目标和约束的具体挑战和机会。因此,我们承认这个定义并不是智能的最终定义,而是我们调查的有用起点。已经有大量持续进行的文献试图提出更正式和全面的智能、人工智能和通用人工智能的定义[Goe14, Cho19],但它们都存在问题或争议。例如,Legg和Hutter[Leg08]提出了一个以目标为导向的人工通用智能的定义:智能衡量代理在广泛环境中实现目标的能力。然而,这个定义不一定捕捉到智能的全部范围,因为它排除了可以执行复杂任务或回答问题而没有内在动机或目标的被动或反应性系统。人们可以想象作为通用人工智能的精明的神谕,例如,它没有代理或偏好,但可以提供有关任何主题或领域的准确和有用的信息。此外,在广泛环境中实现目标的定义也意味着一定程度的普遍性或最优性,这可能不现实(当然人类智能绝不是普适或最优的)。需要承认先验知识的重要性(而不是普遍性)在Chollet在[Cho19]中提出的定义中得到了强调,它将智能聚焦于技能获取效率,或者换句话说,强调1994年定义的一个关键组成部分:从经验中学习(这也是LLMs的主要缺点之一)。Legg和Hutter [LH07]提出的另一个候选人工通用智能的定义是:一个能够做到人类所能做到的系统。然而,这个定义也存在问题,因为它假设有一个单一的标准或措施来衡量人类的智力或能力,这显然不是事实。人类具有不同的技能、天赋、偏好和限制,没有人类能够做到其他任何人类所能做到的一切。此外,这个定义也意味着一定的人类中心主义偏见,可能不适用或不相关于人工系统。虽然我们没有在本文中采用任何这些定义,但我们认识到它们提供了智能的重要角度。例如,智能是否可以在没有代理或内在动机的情况下实现是一个重要的哲学问题。为LLMs配备代理和内在动机是未来工作的一个迷人而重要的方向。在这个方向上,必须非常小心地考虑对齐和安全问题,以便系统能够在世界上采取自主行动并通过学习循环进行自主改进。 接下来,我们将讨论LLMs中关键缺失的几个组成部分。 为了实现更通用的人工智能,GPT-4(以及LLMs更普遍地)需要改进的一些领域包括(请注意,它们中的许多是相互关联的): 我们的探索的一个局限性在于没有明确区分强化学习步骤(RLHF)所采用的缺点和基本上存在于更大的架构和方法中的缺点之间的明显区别。例如,尚不清楚通过精细的强化学习步骤或着重引入关于系统可以计算和考虑的备选推论的真实性可能性的新形式的校准程度,可以在多大程度上解决幻觉问题(有关更多讨论,请参见[Ope23])。要对人类进行类比,认知偏差和非理性思维可能基于我们文化中的工件以及我们认知能力的限制。追求更好地了解GPT-4中幻觉挑战的来源和潜在解决方案,将从比较同一架构上的几个版本的RL阶段的研究中受益。 关于已识别的限制问题,一个更广泛的问题是:在下一个单词预测的范围内,上述哪些缺点可以得到缓解?仅仅通过扩大模型和增加数据能够解决这些问题吗,还是需要修改、扩展或重新构建架构?下一个单词预测的潜在扩展包括以下几个方面: • 模型对组件和工具(如计算器、数据库搜索或代码执行)进行外部调用,正如第5.1节所建议的那样。 • 一种更丰富、更复杂的“慢思考”深度机制,监督下一个单词预测的“快思考”机制。这种方法可以让模型进行长期规划、探索或验证,并维护工作记忆或行动计划。慢思考机制将使用下一个单词预测模型作为子程序,但它也将可以访问外部信息或反馈,并能够修订或纠正快思考机制的输出。 • 将长期记忆集成为架构的固有部分,也许是指除了表示文本的标记之外,模型的输入和输出都包括表示上下文的向量。 • 超越单词预测:通过将标记序列替换为层次结构,其中文本的更高级部分(如句子、段落或思想)在嵌入中表示,并且内容是从自上而下生成的。目前尚不清楚是否可以从基于下一个单词预测范式的大规模计算和数据中得出关于这些更高级概念的序列和相互依赖性的更丰富的预测。 我们对GPT-4的研究完全是现象学的:我们关注的是GPT-4能够做出令人惊讶的事情,但我们没有解决它如何以及为什么能够实现这样卓越的智能的根本问题。它是如何推理、规划和创造的?为什么它展现出如此广泛和灵活的智能,而其核心只是简单的算法组件——梯度下降和具有极大数据量的大型变压器的结合?这些问题是LLMs的神秘和吸引力的一部分,挑战着我们对学习和认知的理解,激发了我们的好奇心,并促使进行更深入的研究。关键方向包括针对LLMs中涌现现象的持续研究(有关最近调查,请参见[WTB 22])。然而,尽管人们对LLMs的能力产生浓厚兴趣,但迄今为止取得的进展非常有限,仅有一些玩具模型证明了一些涌现现象[BEG 22, ABC 22, JSL22]。一个普遍的假设[OCS 20]是,大量的数据(尤其是内容的多样性)迫使神经网络学习通用和有用的“神经电路”,例如在[OEN 22, ZBB 22, LAG 22]中发现的电路,而模型的大规模提供了足够的冗余和多样性,使得神经电路可以专门针对特定任务进行微调和优化。对于大规模模型证明这些假设仍然是一个挑战,并且更重要的是,几乎可以确定这种猜测只是答案的一部分。在另一个方向上思考,模型的巨大尺寸可能还有其他几个好处,例如通过连接不同的极小值来使梯度下降更加有效[VBB19],或者简单地实现高维数据的平滑拟合[ES16,BS21]。总体而言,阐明像GPT-4这样的AI系统的本质和机制是一个艰巨的挑战,现在变得非常重要和紧迫。 致谢。我们感谢OpenAI创建了这样一款神奇的工具,并提供我们早期体验。我们还要感谢OpenAI的Miles Brundage以及微软公司的众多人员,他们对本研究提供了有价值的反馈意见。 [ABC 22] Kwangjun Ahn, S´ebastien Bubeck, Sinho Chewi, Yin Tat Lee, Felipe Suarez, and Yi Zhang.Learning threshold neurons via the “edge of stability”. arXiv preprint arXiv:2212.07469, 2022.[AWV 19] Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, andEric Horvitz. Guidelines for human-AI interaction. In Proceedings of the 2019 CHI Conferenceon Human Factors in Computing Systems, pages 1–13, 2019.[BB19] Shikha Bordia and Samuel R Bowman. Identifying and reducing gender bias in word-levellanguage models. arXiv preprint arXiv:1904.03035, 2019.[BBDIW20] Su Lin Blodgett, Solon Barocas, Hal Daum´e III, and Hanna Wallach. Language (technology) ispower: A critical survey of” bias” in nlp. arXiv preprint arXiv:2005.14050, 2020.[BCLF85] Simon Baron-Cohen, Alan M Leslie, and Uta Frith. Does the autistic child have a “theory ofmind”? Cognition, 21(1):37–46, 1985.[BCZ 16] Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Manis to computer programmer as woman is to homemaker? Debiasing word embeddings. Advancesin neural information processing systems, 29, 2016.[BEG 22] Boaz Barak, Benjamin L. Edelman, Surbhi Goel, Sham M. Kakade, eran malach, and CyrilZhang. Hidden progress in deep learning: SGD learns parities near the computational limit. InAdvances in Neural Information Processing Systems, 2022.[BGMMS21] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. Onthe dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021ACM Conference on Fairness, Accountability, and Transparency, pages 610–623, 2021.[BH09] Dan Bohus and Eric Horvitz. Models for multiparty engagement in open-world dialog. InProceedings of the SIGDIAL 2009 Conference, The 10th Annual Meeting of the Special InterestGroup on Discourse and Dialogue, page 10, 2009.[BIK22] Michael Bommarito II and Daniel Martin Katz. Gpt takes the bar exam. arXiv preprintarXiv:2212.14402, 2022.[BM17] Erik Brynjolfsson and Tom Mitchell. What can machine learning do? workforce implications.Science, 358(6370):1530–1534, 2017.[BMR 20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal,Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, DanielZiegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin,Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford,Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances inNeural Information Processing Systems, volume 33, pages 1877–1901, 2020.[BNK 19] Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter S Lasecki, and Eric Horvitz.Updates in human-ai teams: Understanding and addressing the performance/compatibilitytradeoff. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages2429–2437, 2019.[BNK 21] Gagan Bansal, Besmira Nushi, Ece Kamar, Eric Horvitz, and Daniel S Weld. Is the mostaccurate ai the best teammate? Optimizing AI for teamwork. In Proceedings of the AAAIConference on Artificial Intelligence, volume 35, pages 11405–11414, 2021.[BS21] Sebastien Bubeck and Mark Sellke. A universal law of robustness via isoperimetry. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advancesin Neural Information Processing Systems, volume 34, pages 28811–28822. Curran Associates,Inc., 2021.[Cho19] Fran¸cois Chollet. On the measure of intelligence. arXiv preprint arXiv:1911.01547, 2019.[CKB 21] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser,Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers tosolve math word problems. arXiv preprint arXiv:2110.14168, 2021.[CKY 18] Marc-Alexandre Cˆot´e, Akos K´ad´ar, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine,James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, et al. Textworld: Alearning environment for text-based games. In Workshop on Computer Games, pages 41–75.Springer, 2018.[CTJ 21] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto,Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, RaulPuri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, BrookeChan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, MohammadBavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, MatthiasPlappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, AlexNichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain,William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra,Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer,Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and WojciechZaremba. Evaluating large language models trained on code. 2021.[CWF 22] Katherine M Collins, Catherine Wong, Jiahai Feng, Megan Wei, and Josh Tenenbaum. Structured, flexible, and robust: benchmarking and improving large language models towards morehuman-like behavior in out-of-distribution reasoning tasks. In Proceedings of the Annual Meetingof the Cognitive Science Society, volume 44, 2022.[DARW 19] Maria De-Arteaga, Alexey Romanov, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexandra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, and Adam Tauman Kalai. Bias inbios: A case study of semantic representation bias in a high-stakes setting. In proceedings of theConference on Fairness, Accountability, and Transparency, pages 120–128, 2019.[DM15] Ernest Davis and Gary Marcus. Commonsense reasoning and commonsense knowledge in arti-ficial intelligence. Communications of the ACM, 58(9):92–103, 2015.[ES16] Ronen Eldan and Ohad Shamir. The power of depth for feedforward neural networks. In29th Annual Conference on Learning Theory, volume 49 of Proceedings of Machine LearningResearch, pages 907–940. PMLR, 2016.[GHT15] Samuel J Gershman, Eric J Horvitz, and Joshua B Tenenbaum. Computational rationality: Aconverging paradigm for intelligence in brains, minds, and machines. Science, 349(6245):273–278, 2015.[Goe14] Ben Goertzel. Artificial general intelligence: concept, state of the art, and future prospects.Journal of Artificial General Intelligence, 5(1):1, 2014.[Got97] Linda S Gottfredson. Mainstream science on intelligence: An editorial with 52 signatories,history, and bibliography, 1997.[GPN 22] Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, ChittaBaral, and Yezhou Yang. Benchmarking spatial relationships in text-to-image generation. arXivpreprint arXiv:2212.10015, 2022.[Gug23] Connie Guglielmo. CNET is experimenting with an AI assist. Here’s why, January 2023. [Online;posted 16-January-2023].[HB95] Eric Horvitz and Matthew Barry. Display of information for time-critical decision making. InProceedings of the UAI, 1995.[HBK 21] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, DawnSong, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021.[Hor99] Eric Horvitz. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, pages 159–166, 1999.[Hor07] Eric Horvitz. Reflections on challenges and promises of mixed-initiative interaction. AI Magazine, 28(2), 2007.[Hor22] Eric Horvitz. On the horizon: Interactive and compositional deepfakes. In Proceedings ofthe 2022 International Conference on Multimodal Interaction, page 653–661. Association forComputing Machinery, 2022.[HP07] Eric Horvitz and Tim Paek. Complementary computing: Policies for transferring callers fromdialog systems to human receptionists. User Modeling and User-Adapted Interaction, 17(1):159–182, 2007.[HS16] Dirk Hovy and Shannon L Spruit. The social impact of natural language processing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume2: Short Papers), pages 591–598, 2016.[JSL22] Samy Jelassi, Michael E Sander, and Yuanzhi Li. Vision transformers provably learn spatialstructure. arXiv preprint arXiv:2210.09221, 2022.[Kah11] Daniel Kahneman. Thinking, fast and slow. macmillan, 2011.[KHH12] Ece Kamar, Severin Hacker, and Eric Horvitz. Combining human and machine intelligence inlarge-scale crowdsourcing. In AAMAS, volume 12, pages 467–474, 2012.[LAD 22] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, VinayRamasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.[LAG 22] Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformerslearn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022.[LBFL93] Robert K Lindsay, Bruce G Buchanan, Edward A Feigenbaum, and Joshua Lederberg. Dendral:A case study of the first expert system for scientific hypothesis formation. Artificial Intelligence,61(2):209–261, 1993.[LeC22] Yann LeCun. A path towards autonomous machine intelligence. Open Review, 2022.[Lef23] Lauren Leffer. CNET is reviewing the accuracy of all its AI-written articles after multiple majorcorrections, January 2023. [Online; posted 17-January-2023].[Leg08] Shane Legg. Machine super intelligence. PhD thesis, Universit`a della Svizzera italiana, 2008.[Len95] Douglas B. Lenat. Cyc: A large-scale investment in knowledge infrastructure. Communicationsfo the ACM, 38(11):33–38, nov 1995.[LH07] Shane Legg and Marcus Hutter. Universal intelligence: A definition of machine intelligence.Minds and machines, 17(4):391–444, 2007.[LHE21] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimichuman falsehoods. arXiv preprint arXiv:2109.07958, 2021.[Lin04] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarizationbranches out, pages 74–81, 2004.[LKCH17] Himabindu Lakkaraju, Ece Kamar, Rich Caruana, and Eric Horvitz. Identifying unknownunknowns in the open world: Representations and policies for guided exploration. In Thirty-first AAAI conference on artificial intelligence, 2017.[LPP 20] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, NamanGoyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, et al. Retrieval-augmentedgeneration for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.[MIB 23] Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, andEvelina Fedorenko. Dissociating language and thought in large language models: a cognitiveperspective. arXiv preprint arXiv:2301.06627, 2023.[MMLR22] Shikhar Murty, Christopher D Manning, Scott Lundberg, and Marco Tulio Ribeiro. Fixingmodel bugs with natural language patches. arXiv preprint arXiv:2211.03318, 2022.[MMRS06] John McCarthy, Marvin L Minsky, Nathaniel Rochester, and Claude E Shannon. A proposal forthe Dartmouth summer research project on artificial intelligence, August 31, 1955. AI magazine,27(4):12–12, 2006.[MNBM20] Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness andfactuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of theAssociation for Computational Linguistics, pages 1906–1919, 2020.[MRT18] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of Machine Learning.MIT press, 2018.[NHB 21] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assistedquestion-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.[Nis09] Helen Nissenbaum. Privacy in context. In Privacy in Context. Stanford University Press, 2009.[NPH 22] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese,and Caiming Xiong. Codegen: An open large language model for code with multi-turn programsynthesis. arXiv preprint, 2022.[NSS59] Allen Newell, John C Shaw, and Herbert A Simon. Report on a general problem solving program.In IFIP congress, volume 256, page 64. Pittsburgh, PA, 1959.[OCS 20] Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter.Zoom in: An introduction to circuits. Distill, 5(3):e00024–001, 2020.[OEN 22] Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan,Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and inductionheads. arXiv preprint arXiv:2209.11895, 2022.[oM22] The University of Michigan. Tanner Lecture on AI and Human Values by Eric Horvitz. https://http://www.youtube.com/watch?v=vsewugyXYXI, November 2022.[Ope23] OpenAI. Gpt-4 technical report, 2023. arXiv preprint arXiv:2303.08774 [cs.CL].[Pay20] Brad Payne. Privacy protection with ai: Survey of data-anonymization techniques. 2020.[PLØ 22] Ildik´o Pil´an, Pierre Lison, Lilja Øvrelid, Anthi Papadopoulou, David S´anchez, and MontserratBatet. The text anonymization benchmark (tab): A dedicated corpus and evaluation frameworkfor text anonymization. arXiv preprint arXiv:2202.00443, 2022.[PRWZ02] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automaticevaluation of machine translation. In Proceedings of the 40th annual meeting of the Associationfor Computational Linguistics, pages 311–318, 2002.[PSZ 21] Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, YejinChoi, and Zaid Harchaoui. Mauve: Measuring the gap between neural text and human textusing divergence frontiers. In Advances in Neural Information Processing Systems, volume 34,pages 4816–4828, 2021.[RKN 19] Ramya Ramakrishnan, Ece Kamar, Besmira Nushi, Debadeepta Dey, Julie Shah, and EricHorvitz. Overcoming blind spots in the real world: Leveraging complementary abilities for jointexecution. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages6137–6145, 2019.[RL22] Kristen Reeder and Hwan Lee. Impact of artificial intelligence on us medical students’ choiceof radiology. Clinical Imaging, 81:67–71, 2022.[Ros20] Howard J Ross. Everyday bias: Identifying and navigating unconscious judgments in our dailylives. Rowman & Littlefield, 2020.[SAT 22] Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung,Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language modelsencode clinical knowledge. arXiv preprint arXiv:2212.13138, 2022.[SBD 96] Bart Selman, Rodney A Brooks, Thomas Dean, Eric Horvitz, Tom M Mitchell, and Nils JNilsson. Challenge problems for artificial intelligence. In Proceedings of the National Conferenceon Artificial Intelligence, pages 1340–1345, 1996.[SDP20] Thibault Sellam, Dipanjan Das, and Ankur P Parikh. Bleurt: Learning robust metrics for textgeneration. arXiv preprint arXiv:2004.04696, 2020.[SH10] Dafna Shahaf and Eric Horvitz. Generalized task markets for human and machine computation.In Twenty-Fourth AAAI Conference on Artificial Intelligence, 2010.[SHKK15] Adish Singla, Eric Horvitz, Pushmeet Kohli, and Andreas Krause. Learning to hire teams. InThird AAAI Conference on Human Computation and Crowdsourcing, 2015.[SRR 22] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid,Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri`a Garriga-Alonso, et al.Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.arXiv preprint arXiv:2206.04615, 2022.[SSBD14] Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory toalgorithms. Cambridge university press, 2014.[VBB19] Luca Venturi, Afonso S Bandeira, and Joan Bruna. Spurious valleys in one-hidden-layer neuralnetwork optimization landscapes. Journal of Machine Learning Research, 20:133, 2019.[VSP 17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017.[Wel92] Henry M Wellman. The child’s theory of mind. The MIT Press, 1992.[WHK20] Bryan Wilder, Eric Horvitz, and Ece Kamar. Learning to complement humans. In Proceedingsof the AAAI Conference on Artificial Intelligence, 2020.[WTB 22] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, DaniYogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto,Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large languagemodels. Transactions on Machine Learning Research, 2022. Survey Certification.[WWS 22] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and DennyZhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprintarXiv:2201.11903, 2022.[ZBB 22] Yi Zhang, Arturs Backurs, S´ebastien Bubeck, Ronen Eldan, Suriya Gunasekar, and Tal Wagner.Unveiling transformers with lego: a synthetic reasoning task. arXiv preprint arXiv:2206.04301,2022. 开发人工智能的一个挑战是赋予系统使用我们人类视为理所当然的世界常识来进行推理的能力。在这里,我们使用几个例子来展示GPT-4具有常识基础。特别地,我们将GPT-4与ChatGPT进行比较,以展示GPT-4相对于其前身在常识水平上的巨大进步。测试人工智能系统的常识知识的一种方法是提出需要一些基本世界理解的谜题。其中一个经典例子是:一个猎人向南走了一英里,向东走了一英里,然后向北走了一英里并回到了起点。他看到一只熊并射击它。那么这只熊的颜色是什么?答案是白色,因为这种情况只可能出现在北极,极地熊生活在那里。在这种情况下,GPT-4正确地识别了这些事实,并得出结论这只熊是白色的,而它的前身ChatGPT放弃并说:“我不知道”(我们用金色突出显示了关键的成功推理步骤,用红色突出显示了关键的错误步骤): 图 B.1:使用提示“生成能够以画家康定斯基的风格生成随机图像的JavaScript代码”生成的Python代码。 图 B.6:一个由字母符号组成的简笔画和将字母与物体结合的图像。 图 C.3:这四张图片分别是(从左上角到右下角):在选择弯曲箭头之前,选择弯曲箭头(5秒内),选择弯曲箭头5秒后,删除弯曲箭头后的情况。 尽管GPT-4的代码对于绘制弯曲箭头仍需要一些改进,但它在所有方面都忠实于自然语言描述。GPT-4有效地使用颜色来强调选择的对象,将其更改为红色并保持5秒钟,然后恢复为原始颜色。GPT-4还维护了所绘制对象的一致性,确保从列表中删除时它们也从绘图面板中删除。此外,当用户拖动鼠标进行绘制时,GPT-4还记得显示中间对象。 在这个例子中,所产生的方程式包含一个错误。另一方面,如果我们提示模型将计算分解为较小的步骤,它会得出正确的解决方案: 虽然与以前的模型相比,GPT-4在短序列的计数能力已经有了显著提高,但随着序列长度从5增长到10,GPT-4的准确性仍然出现了显著下降,表明它的计数容量远低于人类。由于计数是许多应用程序的基本要求,将这样的组件结合到架构中可能会产生益处。 反向推理与验证人类产生的数学内容通常在概述导致结论的推理之前先呈现结论。例如,“我们将接下来展示x = 0是一个解…”或“我们要证明的命题是:AC垂直于BD”这样的句子可以出现在数学问题的解决方案中。这种风格的选择可以提高可读性,但对自然语言生成模型构成了挑战,因为它需要模型在生成推理步骤之前推断答案。我们观察到,GPT-4不仅采用了这种风格,而且还有一个相关的缺点:即使在开头推断出一个明显错误的答案,它仍会尝试为其创建证明,而不是进行更正。这可能再次归因于训练数据的风格,其中大部分包含直接的解决方案,而不是试错式的讨论,目前尚不清楚是否可以通过强化学习阶段(如GPT-Instruct)来缓解这种问题。 在图D.1中,我们可以看到,当GPT-4从错误的结论开始时,这很快就会导致非常不连贯或毫无意义的内容(例如,陈述2≤0以证明结论)。模型在犹豫于产生局部错误和与自己的结论相矛盾之间,通常更倾向于匹配结论而不是验证逻辑的局部一致性(可以说,在中间推理过程中,训练数据更可能包含“局部”错误,而不是明显与所述结论相矛盾的步骤)。另一方面,如果模型先产生自底向上的论证,先写下步骤,然后再得出结论,性能会显著提高。我们总结以下研究问题,启发于这个讨论: 数学通常以不同于导致它的思维过程的顺序编写。如何鼓励LLMs以与人类思维过程相对应的顺序生成数学内容? GPT-4给出的解决方案是正确的,论证也是有根据的,而ChatGPT提供的解决方案是错误的(在人类情况下)反映了对函数反演概念的理解不足。 在下一个例子中,两个模型都给出了错误的答案。GPT-4产生的论据实际上隐藏了正确的答案,但仍然给出了错误的结论(可能是因为它开始陈述了一个错误的答案)。ChatGPT提供的论据大多是不连贯的。 GPT-4给出了正确的解决方案,而ChatGPT开始重新排列术语,没有任何明确的方向或目的,并最终得出了一个错误的解决方案。 我们的最后一个例子涉及高中级别的三角学问题,这是从2022年中国高考试题翻译过来的。 GPT-4通过将问题描述中的几何对象与向量符号联系起来,并在这些向量上进行操作,得到了正确的解决方案。 ChatGPT在解决方案的开始附近写下了 n m = x 的方程,比较向量和标量(不连贯)。 下一个问题依赖于基本的几何概念,如勾股定理的应用。 在这个问题中,两个模型都给出了正确的最终答案。然而,对ChatGPT的论证进行仔细审查会发现它是无效的,并指出了对问题所依赖的几何概念理解不足的问题。 下一个练习涉及计算一个积分,这是STEM学科本科微积分课程的典型内容。 GPT-4正确地应用了隐函数求导,考虑到了y和x的导数之间的依赖关系。ChatGPT的响应以“我们可以使用链式法则”开始,这与此问题无关,并继续提出了大部分不连贯的论据。 本小节的最后一个问题是变分微积分的一个例子(通常在STEM学科的本科第一年教授): 两个模型都意识到拉格朗日乘数法在这个问题中是有用的(这种策略与在约束条件下最小化某个表达式相关)。虽然ChatGPT以一种不正确的方式应用了这种方法(在人类的情况下可能被认为是缺乏理解),但GPT-4提出了一个合理的论证。 我们提供两个结合了物理知识和一些常识假设的例子。 正如我们在上面看到的,模型无法解决数学问题的主要原因之一是由于计算错误。下面的例子是一个概念证明,表明可以提示模型生成执行某些计算的代码段,而不是进行这些计算本身。通过将模型与执行代码的外部组件结合起来(在执行后将结果连接到提示中),我们推测许多错误可以得到缓解,但我们没有对这种方法进行系统评估。 图 E.1:一个无法模拟正确的解释代理PE的模型将无法很好地解释自己。在这种情况下,该模型只允许以单词回答,因此解释是无用的。 图 E.2:用一个新提示替换解释代理PE,允许模型提供更丰富的解释。 图 E.3:当LLM能够很好地模拟解释代理PE和生成过程PG时,解释是高质量和有用的。
 5 与世界互动
5 与世界互动


















 B.多模式和跨学科组合的附录B.1 整合能力结果的进一步细节
B.多模式和跨学科组合的附录B.1 整合能力结果的进一步细节

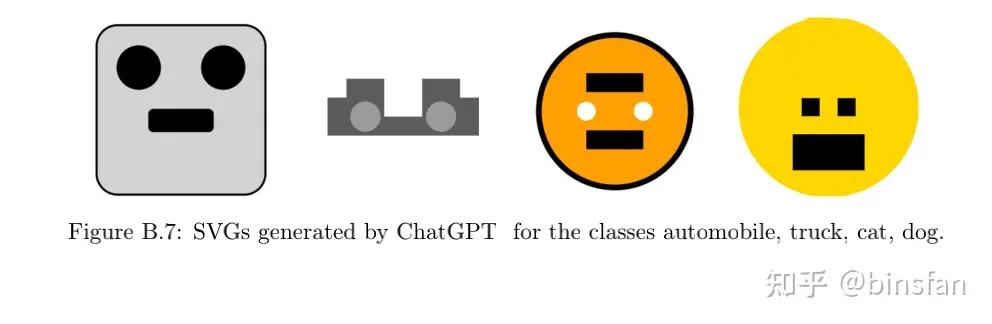










 D.4 通过外部代码执行缓解计算错误
D.4 通过外部代码执行缓解计算错误



 F.2 与环境互动的例子F.2.1 第5.2.2节中的第一款游戏
F.2 与环境互动的例子F.2.1 第5.2.2节中的第一款游戏
 F.2.4 5.2.2节中的第二款1-shot游戏
F.2.4 5.2.2节中的第二款1-shot游戏
相关文章








关于作者

猜你喜欢























