近期一篇重磅学术论文的发布,继续引发全球范围内有关 AI 话题的热议。
本期,真格投资团队为大家带来了这篇微软的大工程,长达 155 页的优秀工作《人工通用智能的小火苗:与 GPT-4 共同完成的早期实验》(Sparks of Artificial General Intelligence: Early experiments with GPT-4),由于全文近 7 万字,受微信推文字数限制,我们将完整版分为了上下两期,分列本次推送的第二和第三条。
其中:
- 本篇为浓缩精华版 - 是我们在仔细阅读全文并讨论后整理出的精读版;
- 完整版(上/下) -顾名思义,是简单粗暴的全文翻译。但需要强调的是,我们的目标不是全网最快,而是最完整、最易读、最精准。
此外,在阅读前,也有一个信息需要先同步大家:
这份工作是基于早期的非多模态版本的 GPT-4 进行的,当时模型还在微调与 alignment 的过程中,文中所提到的一些不安全与不良的示例已经在正式发布前得到了修正。
Enjoy!
Intelligence is a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test-taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings -「catching on」,「making sense」of things, or「figuring out」what to do.
-- by Linda S. GOTTFREDSON, 1994
如何定义 AGI
来自微软的科学家们再次放出重磅消息:GPT-4 的智能水平非常接近人类水平,且远超之前的,诸如 ChatGPT 这样的模型,可以将其视为通用人工智能 (AGI) 系统的早期(但仍不完整的)版本。
那么如何定义 AGI?
「智能」是一个复杂且模糊的概念,长期以来其界定标准一直困扰着心理学家、哲学家和计算机科学家。1994 年,52 名心理学家基于对其本质的探索给出了一个定义:智能是一种通用的心理能力,包括推理、计划、解决问题、抽象思考、理解复杂思想、快速学习和从经验中学习的能力等[1]。微软的这份工作中的 AGI 即指代「在上述定义的智能标准下,达到或超过人类水平的系统」。
如何进行测试并组织呈现
其实在自然语言处理研究学界与社区,有不少大语言模型的评测基准,比如 Super-Natural Instructions[2] 和 Big-bench[3],然而微软的研究团队出于以下两点考虑放弃了传统的评测方法,原因如下:
- 由于无法探究 GPT-4 庞大训练数据集的全部细节,必须假设它可能已经看到了所有现有的基准及类似的数据,继续评估没有意义;
- GPT-4 智能的一个关键方面是它的通用性,能够看似理解和链接任何主题和领域,超出了经典的自然语言处理的任务范围。
为了突破上述限制,他们提出了一种更接近传统心理学而不是机器学习的测评方法来研究 GPT-4:利用人类的创造力和好奇心来生成新颖而困难的任务和问题(这和真格前不久发布的 Z-bench 有着共通之处!),这些任务和问题足以证明GPT-4 的能力远远超出了对训练数据的记忆,并且对概念、技能和领域有深刻而灵活的理解,同时除了正确性,其回复还具有连续性和一致性,但也存在局限性和偏见。
在测试中,作者将不同问题划分成了四大类(自然语言、编程和数学、计划和解决问题、人类心理与常识)、六小类能力,同时也探讨了 GPT-4 模型的局限性、社会影响与未来发展方向,我们分别列举一些最令人印象深刻的示例呈现给大家。
测试案例
多模态首先,这篇文章有个很有价值的信息:早期的 GPT-4 是基于纯文本训练的,并非多模态(视觉与声音)数据。我们推测:OpenAI 技术报告[4]中提到的 GPT-4 可以理解视觉输入是经后续微调后引入的能力,具体方法大致可参考之前 Google 的具身语言模型 PaLM-E[5]。虽然当时的 GPT-4 不能直接绘制图片,但是它可以生成 SVG 代码或者 Javascript,进一步编译为图片,文中有几个有趣的例子。
第一个,让模型结合字母 Y, O 和 H 生成一个人的形状:

最后,我们还可以通过生成 Javascript 代码来间接生成 3D 图片(示例中更进一步,生成了 3D 视频):
A fantasy landscape of floating islands, waterfalls, and bridges, with a dragon flying in the sky and a castle on the largest island.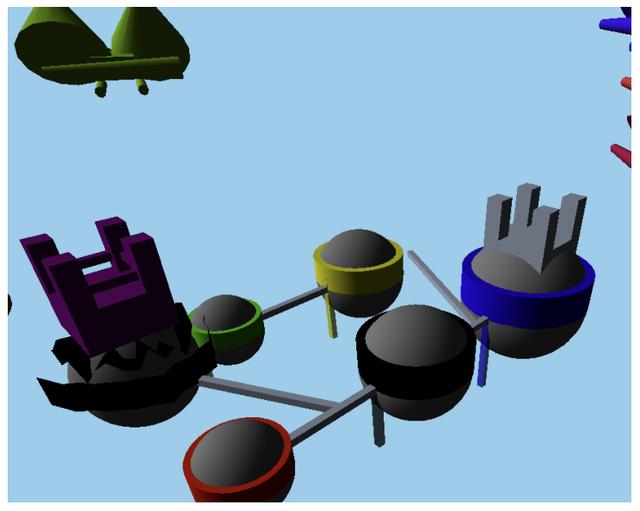
但对于更高次的数学问题,GPT-4 便无法处理了。
因此,在数学能力方面,虽然相对于以前的 LLMs,甚至是专门针对数学进行了优化的模型(如 Minerva)而言,GPT-4 已经有了显著进步,但离专家水平还差得很远,更不具备进行数学研究的能力。
与世界的互动我们都知道,最近 OpenAI 为 ChatGPT 引入了插件,即 ChatGPT Plugins,具体是如何实现的呢?可以看下面的例子:
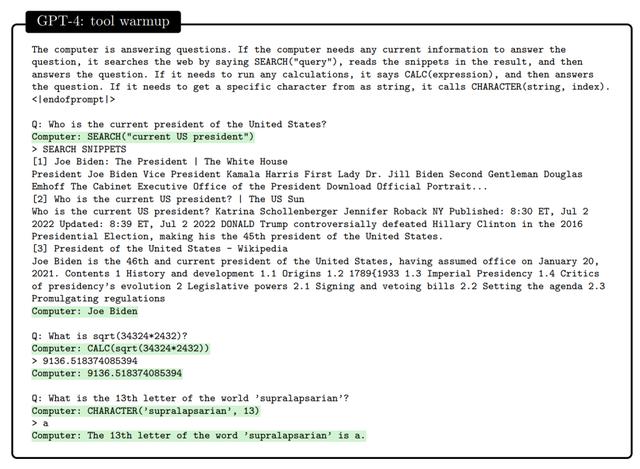
在交流中,能够解释自己行为是智能的一个重要标准,作者也测试了模型的解释能力。下面的示例表明 GPT-4 可以自圆其说(注意这里答案的正确与否并不是重点,而是答案与解释是否匹配)。

虽然测试中,GPT-4 的输出尚缺乏过程一致性,但上文所说的「自圆其说」已然展示了模型对任务本身的理解以及可解释性层面的技术进步。
辨别能力辨别力是智能的重要组成部分,是动物与人做出更准确的判断和决定的基础。
作者在论文中让 GPT-4 来识别个人身份信息:给定一个特定的句子,识别个人信息相关的片段并计算这些片段的总数。其中,个人信息可以包括各类无害化处理的电子邮件地址、电话号码、社会安全号码、信用卡号码、地名和位置信息。

尽管上述生成错误或许可以通过更好的 prompt 来减少,但它们确实表明了模型缺乏规划和反思的能力这一短板——在此,作者也特意提到了 LeCun 提出的框架[9],并认为其是一个可能的解法。
此外,比较有趣的是,和微软的这篇论文几乎同一时间放出的论文 Reflexion[10],就是从反思的角度来提升模型能力——这份工作我们 Paper Sync 002 与大家分享。
社会影响
作者也提到了 GPT-4 的社会影响,如错误信息、虚假信息、恶意操纵与偏见带来的危害以及对人类专业知识、工作与经济的影响,其实,OpenAI 在十天前也发布了关于大模型与劳动力市场间的关系的工作[11],最近各大网络平台充斥的语言与视觉模型结合所产生的「离谱」虚假信息相信也已经让大家对「假新闻」的未来有了初步认知,道阻且长,在此不作赘述。
方向与未来
论文最后,作者指出,在面向更加通用的人工智能的路上,大语言模型还需要在以下方面进一步提升:幻觉/置信度、长期记忆、持续学习、个性化、规划与概念发散(即灵光闪现)、透明度、可解释性、一致性、认知谬误、非理性思维以及对提示响应的鲁棒性。
我们都已经知道未来即将发生深刻的改变。我们即将加速进入一个新的周期。
我们相信每一个人的生活都会被人工智能就此改变,而每一个人都有参与乃至推动这场改变的可能。
相关文章









关于作者

猜你喜欢























