OpenAI 最近发布了一个名为 Whisper 的语音识别模型。与 DALLE-2 和 GPT-3 不同,Whisper 是一个免费的开源模型。
——1——
什么是Whisper语言识别模型
Whisper 是一种自动语音识别模型,基于从网络上收集的 680,000 小时多语言数据进行训练。根据 OpenAI的介绍,该模型对口音、背景噪音和技术语言具有很好的鲁棒性。此外,它还支持 99 种不同语言的转录和从这些语言到英语的翻译。

Whisper
Whisper 架构是一种简单的端到端方法,实现为利用Transformer模型的编码器-解码器。输入音频被分成 30 秒一段的模块,然后转换成 log-Mel 频谱图,然后传递到编码器。编码器来计算注意力,最后把数据传递给解码器,解码器被训练来预测相应的文本,并添加特殊标记,这些标记用来单个模型执行诸如语言识别、多语言语音转录和英语语音翻译等任务。
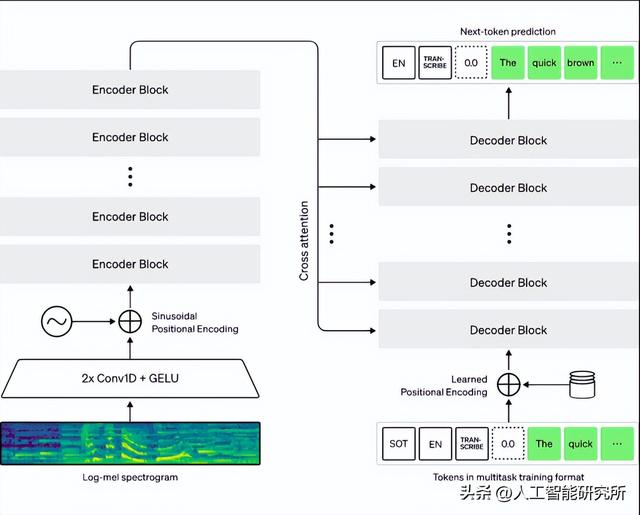
Whisper 的音频数据集大约有三分之一是非英语的,它交替执行以原始语言转录或翻译成英语的任务。发现这种方法在学习语音到文本的翻译任务方面特别有效,并且优于SOTA模型的 CoVoST2 英语翻译零样本监督模型。
——2——
Whisper语音识别模型代码实战

模型训练数据
当然,模型除了识别英文语音外,还可以识别其他语言,我们这里使用一个中文语音,当然这里顺便我们把中文语音识别完成后,再翻译成中文
import ipywidgets as widgets
languages = {"af_za": "Afrikaans", "am_et": "Amharic", "ar_eg": "Arabic", "as_in": "Assamese", "az_az": "Azerbaijani", "be_by": "Belarusian", "bg_bg": "Bulgarian", "bn_in": "Bengali", "bs_ba": "Bosnian", "ca_es": "Catalan", "cmn_hans_cn": "Chinese", "cs_cz": "Czech", "cy_gb": "Welsh", "da_dk": "Danish", "de_de": "German", "el_gr": "Greek", "en_us": "English", "es_419": "Spanish", "et_ee": "Estonian", "fa_ir": "Persian", "fi_fi": "Finnish", "fil_ph": "Tagalog", "fr_fr": "French", "gl_es": "Galician", "gu_in": "Gujarati", "ha_ng": "Hausa", "he_il": "Hebrew", "hi_in": "Hindi", "hr_hr": "Croatian", "hu_hu": "Hungarian", "hy_am": "Armenian", "id_id": "Indonesian", "is_is": "Icelandic", "it_it": "Italian", "ja_jp": "Japanese", "jv_id": "Javanese", "ka_ge": "Georgian", "kk_kz": "Kazakh", "km_kh": "Khmer", "kn_in": "Kannada", "ko_kr": "Korean", "lb_lu": "Luxembourgish", "ln_cd": "Lingala", "lo_la": "Lao", "lt_lt": "Lithuanian", "lv_lv": "Latvian", "mi_nz": "Maori", "mk_mk": "Macedonian", "ml_in": "Malayalam", "mn_mn": "Mongolian", "mr_in": "Marathi", "ms_my": "Malay", "mt_mt": "Maltese", "my_mm": "Myanmar", "nb_no": "Norwegian", "ne_np": "Nepali", "nl_nl": "Dutch", "oc_fr": "Occitan", "pa_in": "Punjabi", "pl_pl": "Polish", "ps_af": "Pashto", "pt_br": "Portuguese", "ro_ro": "Romanian", "ru_ru": "Russian", "sd_in": "Sindhi", "sk_sk": "Slovak", "sl_si": "Slovenian", "sn_zw": "Shona", "so_so": "Somali", "sr_rs": "Serbian", "sv_se": "Swedish", "sw_ke": "Swahili", "ta_in": "Tamil", "te_in": "Telugu", "tg_tj": "Tajik", "th_th": "Thai", "tr_tr": "Turkish", "uk_ua": "Ukrainian", "ur_pk": "Urdu", "uz_uz": "Uzbek", "vi_vn": "Vietnamese", "yo_ng": "Yoruba"}
selection = widgets.Dropdown(
options=[("Select language", None), ("----------", None)] sorted([(f"{v} ({k})", k) for k, v in languages.items()]),
value="ko_kr",
description='Language:',
disabled=False,
)
selection
首先,这里我们需要选择我们识别的语音是那个语言
lang = selection.value
language = languages[lang]
assert lang is not None, "Please select a language"
print(f"Selected language: {language} ({lang})")
这里,我们选择Chinese
# Selected language: Chinese (cmn_hans_cn)
import pandas as pd
pd.options.display.max_rows = 100
pd.options.display.max_colwidth = 1000
audio = '2233.mp3'
transcriptions = []
translations = []
options = dict(language=language, beam_size=5, best_of=5)
transcribe_options = dict(task="transcribe", **options)
translate_options = dict(task="translate", **options)
transcription = model.transcribe(audio, **transcribe_options)["text"]
translation = model.transcribe(audio, **translate_options)["text"]
transcriptions.append(transcription)
translations.append(translation)
data = pd.DataFrame(dict(
transcription=transcriptions, translation=translations))
data
这里,我们使用一段中文语音,并设置task为transcribe,意思是语音识别,另外设置一个task为translate,意思是翻译,最后模型识别出语音,也会自动翻译其中文到英文
transcription
translation
0
你可将此文本替换为所需的任何文本。你可在此文本框中编写或在此处粘贴你自己的文本。请尽情使用文本转语音功能。
You can replace this document with any other document you need. You can write or paste your own documents in this document box. Please use the text translation feature.
模型可以识别的99种语音如下,大家可以根据自己的应用选择不同的模型与语音

相关文章









关于作者

猜你喜欢























