编辑:编辑部
【新智元导读】chatgpt为人诟病的「数学智障」问题,有望彻底攻克!OpenAI最新研究发现,利用「过程监督」可以大幅提升GPT模型的数学能力,干掉它们的幻觉。ChatGPT自发布以来,数学能力饱受诟病。
就连「数学天才」陶哲轩曾表示,GPT-4在自己的数学专业领域,并没有太多的增值。
怎么办,就一直让ChatGPT做个「数学智障」么?
OpenAI在努力——为了提升GPT-4的数学推理能力,OpenAI团队用「过程监督」(PRM)训练模型。
让我们一步一步验证!

这里,GPT-4成功地执行了一系列复杂的多项式因式分解。
在步骤5中使用Sophie-Germain恒等式是一个重要的步骤。可见,这一步骤很有洞察力。

在步骤7和8中,GPT-4开始执行猜测和检查。
这是该模型可能产生「幻觉」的常见地方,它会声称某个特定的猜测是成功的。在这种情况下,奖励模型验证每一步,并确定思维链是正确的。

在过程监督中,会奖励大模型正确的推理步骤,而不仅仅是奖励它们正确的最终结论。这个过程,会鼓励模型遵循更多类似人类的思维方法链,因而也就更可能造就更好的可解释AI。
OpenAI的研究者表示,虽然过程监督并不是OpenAI发明的,但OpenAI正在努力推动它向前发展。
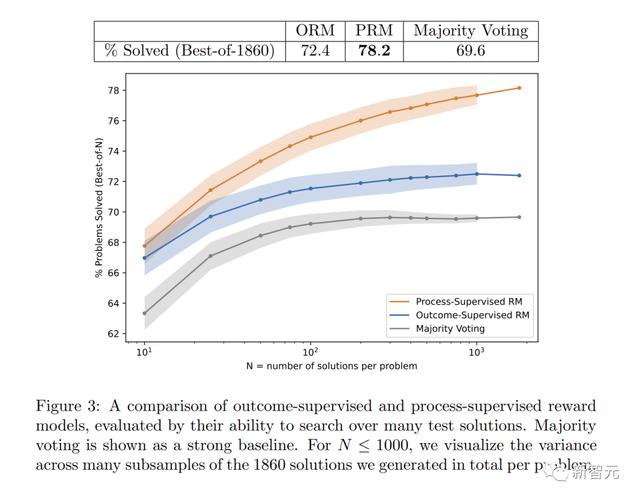
最新研究中, OpenAI把「结果监督」或「过程监督」两种方法都试了一遍。并使用MATH数据集作为测试平台,并对这两种方法进行了详细比较。
结果发现,「过程监督」能够明显提高模型性能。
如下是一个标注的示例。OpenAI正在发布原始标注,以及在项目第1阶段和第2阶段给标注者的指示。
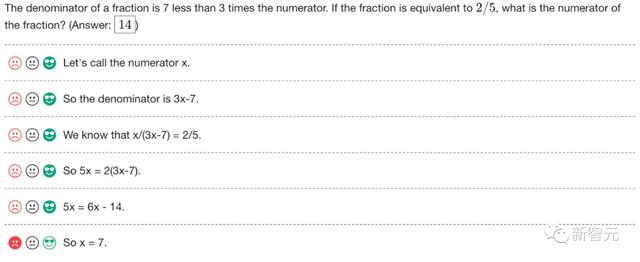
训练模型去思考,而不仅是输出正确的答案,将会成为解决复杂问题的game changer。

ChatGPT在数学方面超级弱。今天我试图解决一个四年级数学书上的数学问题。ChatGPT给了错误答案。我把我的答案和ChatGPT的答案,在perplexity AI、谷歌的答案,以及四年级的老师进行了核对。每个地方都可以确认,chatgpt的答案是错误的。

参考资料:
https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
相关文章









关于作者

猜你喜欢























