为辅助国内开发者研发中文大模型,近期,上海交通大学联合清华大学及爱丁堡大学共同构造了适用于大语言模型的多层次多学科中文评估套件“C-Eval”,并被认作为目前最主流且认可度最高的中文预训练评估任务。在该项目组最新公布的中文大模型能力排行榜上,360智脑大模型的千亿参数版本“360GPT-S2”平均分得分超过GPT-4,尤其在社会科学及人文科学两项上表现优异。
据了解,C-Eval是全面的中文基础模型评估套件,覆盖人文,社科,理工,其他专业四个大方向,52个学科(含微积分、线代等),题目范畴涵盖中学到大学研究生以及职业考试,共计13948 道题目的中文知识和推理型测试集。
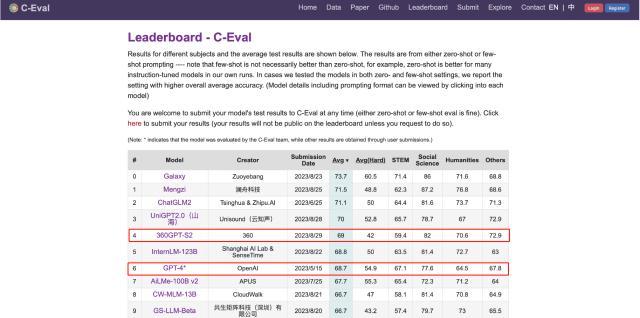
根据官方公布的结果显示,360智脑大模型的千亿参数版本“360GPT-S2”平均分得分为69分,不仅超过GPT-4的平均分,并在社会科学类题目中得分82分,超过GPT-4近5分,人文科学类题目中得分70.6分,比GPT-4该项得分高6分。业内人士评价,以360智脑为代表的国产大模型能力全面超越GPT-4,标志着国产大模型已实现弯道超车。
对此,360智脑业务负责人表示,360智脑在社会科学类及人文科学类评估问题上获得高分成绩,主要取决于360GPT预训练时的高质量且多样性的语料。依托于360搜索11年多的数据积累,360搜索积累了上万亿网页以及完善的数据过滤和清洗手段,并成为360智脑大模型的天然数据优势,同技术优势、搜索增强优势、工程化优势、场景优势、内容安全优势、大模型安全优势、算力优势等八大优势一起,助力360智脑大模型能力不断升级。过去1个月内,360智脑在整体性能提升14.55%,COT能力提升69%,进一步实现可支持50000 字的更长文本输入,并将多轮对话长度提升了18%。
由于360在大模型技术和实践上的积累,360智脑成为中国首个通过工信部信通院认可的“可信AIGC大模型评测”大模型。同时,360被工信部中国电子技术标准化研究院授予“国家人工智能标准化总体组大模型专题组”组长单位,参与大模型国家标准制订,为推动我国大模型产业发展贡献“国家队”力量。
项目组官方表示,知识和推理能力是大模型真正在工业界立生落地的关键。业内人士指出,360智脑的高分上榜标志着其产业落地能力已领跑业界。凭借领先的AI技术,360已于6月推出企业级AI大模型解决方案,并在近20个行业进行落地,全面助力产业数字化转型升级。据刚刚出炉的财报披露,2023年上半年,360智脑大模型已为360创造近2000万元相关业务收入,业务势头强劲,并成为与360数字安全双轨并行的主线业务。
本文源自金融界资讯
相关文章









关于作者

猜你喜欢























