
图:使用ZeRO-100B的600亿参数模型的超线性可扩展性和训练吞吐量。
ZeRO消除了数据和模型并行训练中的内存冗余,同时保持了低通信量和高计算粒度,从而能够按设备数量成比例地缩放模型参数。
研究人员通过分析内存需求和通讯量,表明ZeRO可以使用现有的硬件扩展到超过1万亿个参数。
1 内存优化
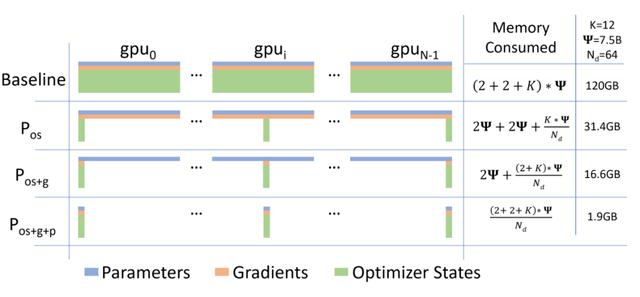
基本的数据并行化不会减少每个设备的内存,如果要训练超过14亿参数的模型,32GB内存(GPU)是不足的。
论文还讨论了如何对优化器状态、梯度进行巧妙分区,来减少GPU节点之间通信的需求,从而实现内存优化。但是即便不使用模型并行,也要在1个GPU上运行1个模型副本。
ZeRO-100B可以在128个GPU上训练多达130亿参数的模型,而无需模型并行,平均每个GPU的吞吐量超过40 TFlops。
相比之下,如果没有ZeRO,则最大的仅数据并行的可训练模型就只有14亿参数,每个GPU的吞吐量小于20 TFlops。
在英伟达 V100和128个节点的DGX-2集群中添加16路模型并行处理,可以训练大约2,000亿个参数。
从16路模型并行开始,可以运行15.4倍的大型模型,而不会真正造成性能损失,而在运行16路模型并行和64路数据并行(1024个GPU)时,性能仅比峰值性能低30%。
将模型参数转换为吞吐量(C,单位petaFLOP/s-days),我们得到:
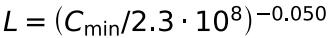
GPT-3能很好地拟合这个等式:

C和N之间的关系如下:

如果我们把GPT-2至GPT-3的参数扩大规模同等应用到GPT-3至GPT-4上面,那么可以计算得到:C≈3.43×10^7,则N≈20万亿。
也就是说GPT-4将有20万亿个参数,因为GPT-3已经有1,750亿个参数(C≈18,300)。
GPT-3训练了3000亿token,但是GPT-4的训练需要大约16万亿token。据统计,英语维基百科有30亿token,网络抓取570 GB的数据有4000亿token,因此要得到16万亿token,大概需要23 TB的数据,相当于Facebook每天要处理的数据量,也就是说,GPT-4的训练将需要巨头科技企业倾尽全力。
由于GPT-3的计算成本约为460万美元,则同等硬件环境下训练GPT-4的计算成本估计为86亿美元。
如果从内存的角度来看,使用参数分区训练更大的模型是如此容易,但是需要解决内存问题才能真正使它完全加载。
与V100相比,A100的计算量可增加3-6倍,但即便如此,成本也要高达14亿美元。
英伟达在2020年第一季度报告的“数据中心”收入是11.5亿美元,所以仅仅为了训练“GPT-4”,几乎需要全球1个季度(3个月)的显卡供应,或者说至少得这个数量级。
3 GPT-4不值得?
这篇文章在reddit引起了热烈讨论。
网友tornado28认为,用如此巨额资金用于训练一个语言模型是不值得的:“如果我们有86亿美元用于建立一个语言模型,我建议投入50亿美元作为研究经费,并可以用剩下的36亿美元和3万篇关于语言建模的新研究论文来训练一个相当好的模型。”
但是,这3万篇论文又会有多少是真正的算法突破呢?Science曾经在5月刊文提到:一些多年前的老算法经过微调,性能足以匹敌当前的SOTA,机器学习领域调参和炼金研究模式仍然盛行,算法的泛化能力有限。一句话总结就是:有调查有真相!某些AI领域多年无实际进展。
网友bohreffect认为,GPT-4的存在不切实际,并且没有必要:“先别说内存需求,世界上真的存在16万亿token的文本数据吗?在某种意义上,这个假想的GPT-4的VC维度似乎会超过英语本身的复杂性,因此会产生过拟合。”
如果GPT-4没有足够的训练数据,那就只需要记忆数据就行,这样的话它的存在并没有意义。
网友RusticScentedMale认为,问题不在于算法而在于计算:“GPT-3的成就不是通过发表更多的研究论文而是通过加大训练费用获得的,所以把钱继续花在研究经费上或许不是最好的选择,除非是关于如何更有效地构建并行计算芯片的研究。”
网友SrslyPaladin评估了所谓“16万亿token”是什么概念,GPT-4可能是文本生成模型的极限:“16万亿token大概是所有已印刷书籍的大小:1.5亿本书x每本书200页x每页300token= 9万亿token,但是你提出了一个很好的观点,假想的GPT-4可能代表了文本输入的有用性极限。”
如果GPT-4真的能学习全世界的文本数据,可能到时候就没有什么文本任务能难倒它,从而它能超仿真的通过图灵测试。
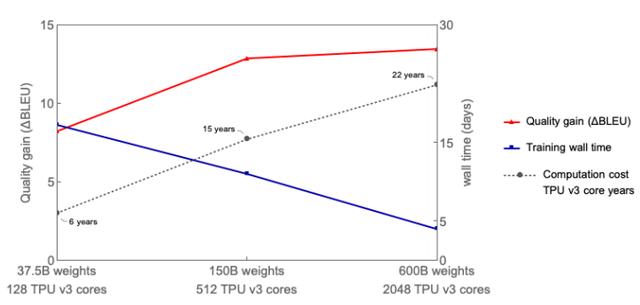
网友thunder_jaxx提到了谷歌的一项新研究,谷歌提出了Gshard模型,这个模型有6000亿参数,论文中的一张图能明显看出BLUE分数的提升与参数量增加的关系。
Gshard论文链接:https://arxiv.org/abs/2006.16668
网友thunder_jaxx表示,我们也应该看看MIT这篇关于深度学习的计算极限的文章,第12页的图很有洞察力。“仅仅扩大计算规模并不是唯一的出路。GPT-3可以做很多有用的任务,但是要完全解决语言的细微差别,需要的不仅仅是计算,因为有太多模型“记忆”(过拟合)的例子了。我们需要一些全新的东西,就像原始的transformer一样。transformer为序列建模问题创建了一个范式转换。我们需要这样的东西来解决通用智能问题。”
ZeRO这篇论文再次揭示了深度学习模型性能和算力之间的强依赖关系,如何突破这个困境,以及如何在算法研究上取得真正的突破,仍然值得深思。
论文第12页的图:

图:深度学习应用程序的性能改善与训练该模型的计算负载有关(以千兆浮点运算为单位)。
参考资料:

相关文章









关于作者

猜你喜欢























