西风 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4数学能力还能更强!
新研究发现GPT-4代码解释器做题准确率与其使用代码的频率有关。
为此,研究人员提出新方法对症下药,直接将其数学能力拔至新SOTA:
在MATH数据集上,做题准确率从53.9%增加到了84.3%。

你没听错,就是前段时间被称为ChatGPT推出后最强模式的那个代码解析器(Code Interpreter)。
研究人员窥探了其代码生成和执行机制,使用自我验证、验证引导加权多数投票的方法,直接打开其做数学题的任督二脉。
好奇网友随即而来:
还想看他们做高数。

还有网友认为:
这也就是大脑的工作方式,人类在解决数学问题时也会自我验证。

他们设计了3种不同的提示方法,限制GPT-4代码解析器使用代码的频率:
Prompt 1:完全不允许使用代码,输出完全依赖自然语言推理,禁止将代码合并到解决方案中。Prompt 2:只允许使用1次代码,也就是在生成解决方案时,只能在单个代码块内使用代码。Basic Prompt:没有限制,GPT-4代码解析器可以进行一系列推理步骤,每个步骤都可由文字 Python代码组成。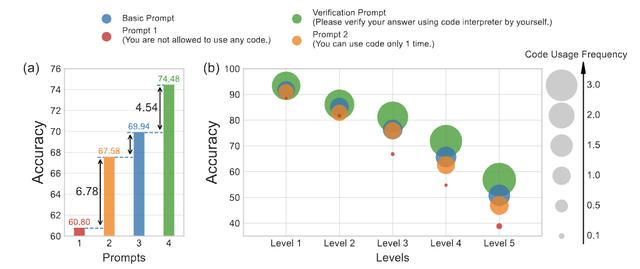
△在MATH数据集上的准确率(%)
在MATH数据集的各个子任务中,提出方法均取得显著提高,尤其是在高难度级别的题目中效果更明显。例如在中级代数(Intermediate Algebra)题目中,原来的GPT-4代码解析器准确率为50.1%,使用新方法后提高到74.4%。
除此之外,研究人员还在GSM8K、MMLU-Math、MMLU-STEM等数据集上进行了验证。

△在GSM8K数据集上的表现
上表可以看出,使用验证引导加权多数投票的方法还可以显著减少需要采样的解路径数量(Sampled paths),在GSM8K数据集上只需要5个路径就达到97%的准确率。
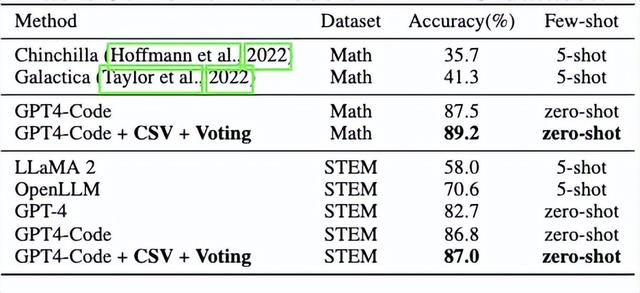
△在MMLU数据集上的表现
针对不同难度的题目(下图a)以及不同类型题目(下图b)的测试中,使用新方法后准确率都有了提升。

△每条曲线上的四个点分别对应于使用Prompt 1、Prompt 2、BasicPrompt、CSV Prompt得到的结果。
研究人员还发现GPT-4代码解析器的代码使用频率提高与准确率提高正相关。随着题目难度的增加,代码使用频率稳步上升。这说明在较难的数学问题上,更频繁地使用代码很重要。
此外,值得注意的是,尽管添加基于代码的自我验证可以提高每个单独题目类型的性能,但改进的程度也因题目类型而异,从7.6%到仅0.6%不等。
研究人员指出:
特别是几何问题的准确性仅提高了0.6%,原本GPT-4代码解析器的准确性也只有54.0%,在各个题目类型中属于较低的。这种差异可能是因为解决几何问题通常需要多模态,超出了本文研究范围。
论文传送门:https://arxiv.org/abs/2308.07921
参考链接:[1]https://twitter.com/_akhaliq/status/1691734872329699813?s=20[2]https://x.com/justfannet/status/1691983780498600376?s=46&t=iTysI4vQLQqCNJjSmBODPw
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢























