ChatGPT在短短两个月内可以说席卷全球,人工智能再一次上了热搜。我的感觉,虽然人工智能已经研发了很多年,但是随着ChatGPT这样的语言模型的推出,仿佛打开了潘多拉魔盒,这是一个窗口期,也是一个分水岭。我们有理由相信,人工智能以后会走上一条高速快车道,因为越来越多的资本都在注资加大研发力度,也许,强人工智能并不会那么久远。
就在上周,一段基于ChatGPT的升级多模算法Demo出现在Git上,在短短几天时间内就收获到15.4K的关注。这个算法改进称之为Visual ChatGPT。他允许用户直接和AI聊天中输入一张图片,或者用语言生成图片。
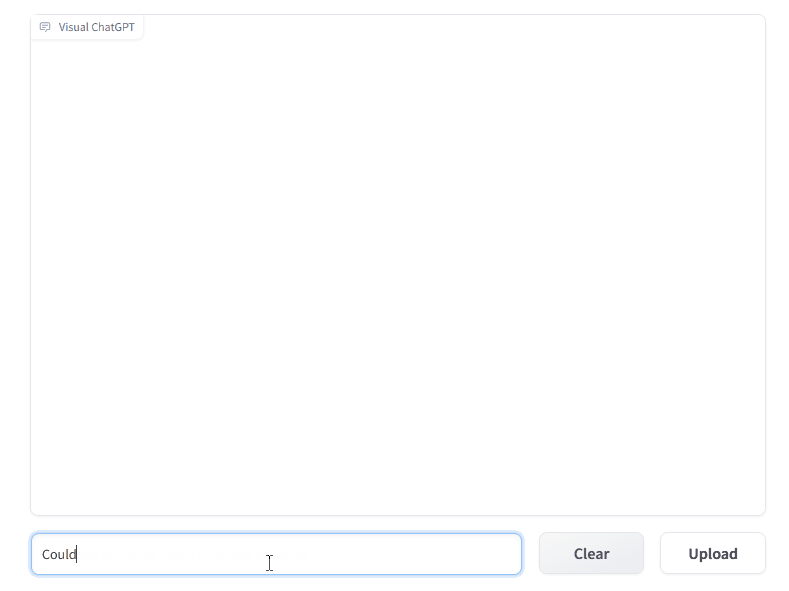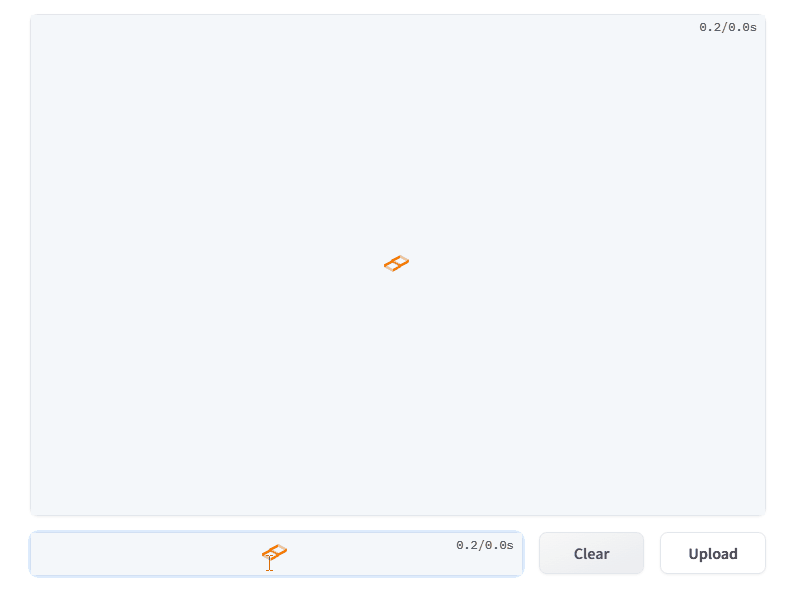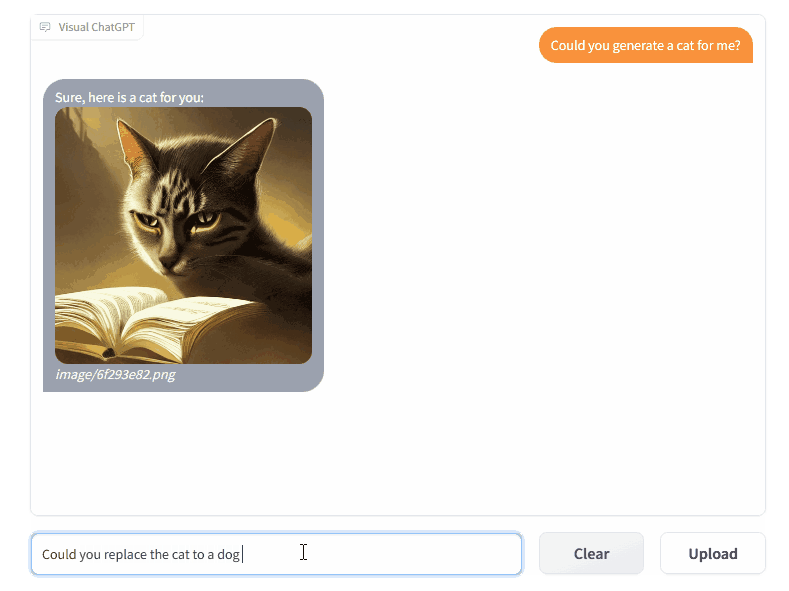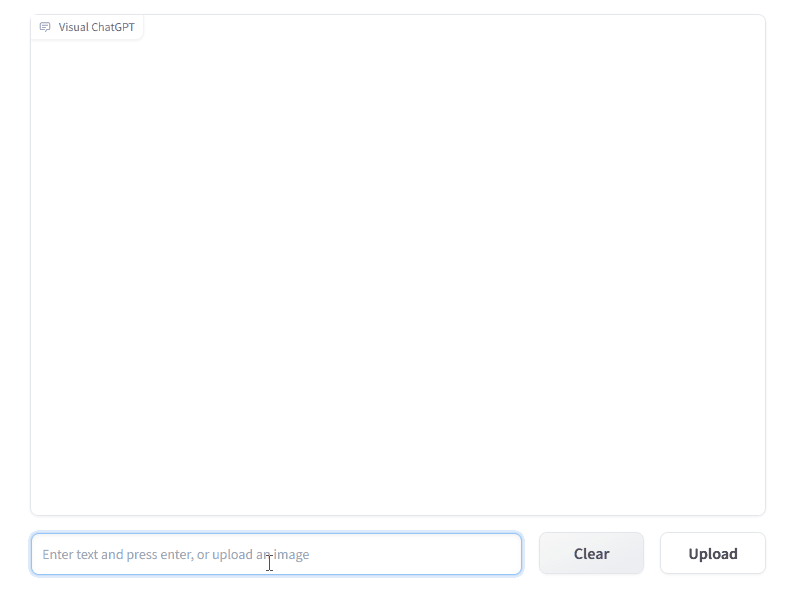
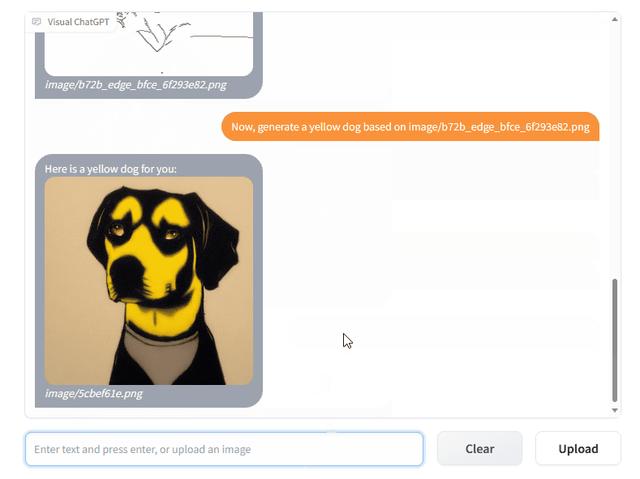
我们可以看到,猫周围的的环境并没有改变,而是单纯将猫替换成了狗。这其实说明系统知道哪里绘制的是猫,哪里是狗,这是针对像素的改变。随后,人又再一次测试印证了这个想法,他要求将这只狗的颜色进行改变,替换成黄色的小狗。
果然,Visual ChatGPT居然真的就抠除掉了图片中的摩托车。这个不禁让人感叹,PS发展到今天,居然抠图的工作完全可以由人工智能完成,而人类只需要动动嘴就可以了。如此发展的话,以后恐怕PS修图师要失业了。
Visual ChatGPT的过人之处
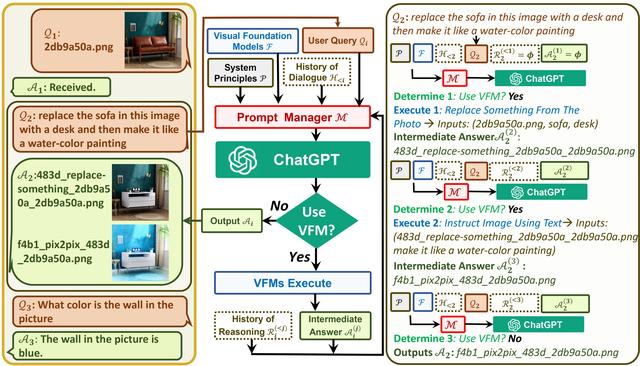
为何Visual ChatGPT能够做到基于图片的提问和修改呢。根据他们官方提供的架构图,大概可以理解到,他是基于一个叫做Prompt Manager的管理工具,整合了ChatGPT的语言模型,并且将VFM(图像生成神经网络)等算法也整合在一起。当用户输入文字要求时候,首先由ChatGPT翻译成程序语言,然后分析是否要生成图片。如果有需要的话,直接由VFM来进行图片的生成以及矫正等工作,最后再呈现给用户。
微软在3月9号的公布在本月16号,也就是百度的“文心一言”发布的同一天,发布ChatGPT4.0语言模型,届时可以对图片、语言、视频进行一键生成和修改的功能。如果真如所述,那无疑是更大的一场风暴,届时,失业的可能不光是PS修图师了,怕是视频编辑也要下岗了。
相关文章








关于作者

猜你喜欢























