丰色 发自 凹非寺
量子位 | 公众号 QbitAI
终于,清华大学唐杰团队也出手了。
就在GPT4发布的同一天,唐教授在微博宣布:
基于千亿参数大模型的对话机器人ChatGLM,现在开启邀请制内测。
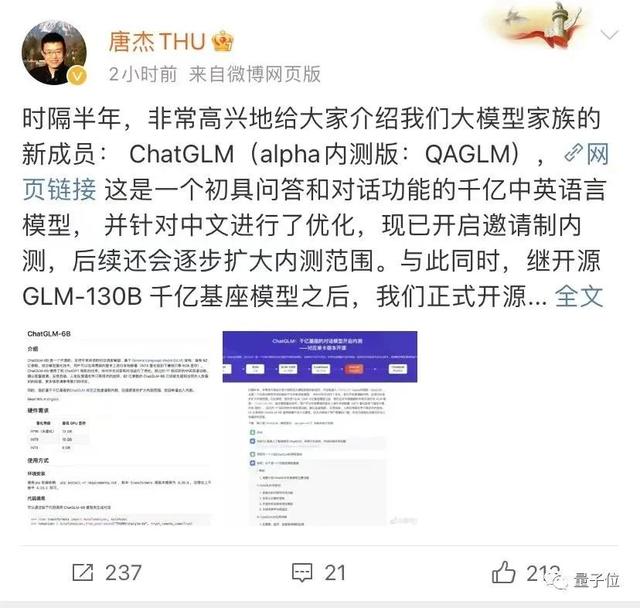
它点出了自己的研发机构,和擅长中文的特点。
那么,就让它用文言文写个致谢词叭。

咋说,虽然多了一个“余”、出现了一个莫名其妙的繁体字,但读着还可以,用的排比句增强了气势。
接着,我们把前几日硅谷暴雷的文章开头丢给它,让它起个标题。
感觉还不错,起码抓住了几个关键信息。

不幸的是,论文挑战没有通过,我们把GLM-130B的链接扔给它,让它简要概括一下主题时,它说的根本不是这篇。
跟ChatGPT胡邹参考文献的操作简直有得一拼(手动狗头)。

接下来,考考它的数学能力吧。
这道小学应用题没问题:

不过鸡兔同笼,就难倒它了,最后居然还算出了负数==

需要注意的是,目前ChatGLM每轮对话最多只可以进行5个来回,每次最多输入1000字。
它对新信息的掌握度不错,知道推特现在的CEO是马斯克,也知道何恺明3月10日回归学界的事情,但还没发现GPT-4已经发布了。

这个GLM-130B的来头值得说道一番。
它是由清华大学知识工程实验室(KEG)与智谱AI共同研发的一个大规模中英文预训练语言模型,参数1300亿,去年8月正式对外发布。
不同于BERT、GPT-3以及T5的架构,GLM-130B是一个包含多目标函数的自回归预训练模型。
它的优势包括:

在Stanford报告的30个世界主流大模型评测中,GLM-130B也成为了亚洲唯一入选的模型。
且获得了不错的成绩:
比如在准确性和恶意性指标上与GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中也可圈可点。

而就在CCF最近的一场会议上,有现场观众提问:ChatGPT为什么没有诞生在中国?是我们没有关注这件事吗?
嘉宾就把GLM-130B搬了出来(它也入选了ICLR’23)。
现在,GLM-130B也终于被派上了“大用场”。
关于内测,唐杰团队表示,后续会逐步扩大范围,有兴趣的朋友可以再等一等。
60亿参数的缩小版同时开源除了这个聊天机器人ChatGLM,唐杰团队这次也把GLM-130B的“缩小版”ChatGLM-6B开源了出来。
△GitHub已经揽获近2k标星ChatGLM-6B使用与ChatGLM相同的技术,初具中文问答和对话功能。
特点如下:

当然,缺点就是容量只有60亿,其模型记忆和语言能力较弱,不擅长逻辑类问题(如数学、编程),以及多轮对话可能会出现上下文丢失和理解错误的情况。
但它主打的就是一个低门槛,在单张2080Ti上就能进行推理使用,硬件需求不高。
因此,只要有兴趣都可以下载下来试试,进行研究和(非商用的)应用开发都可以。
传送门:https://chatglm.cn/https://github.com/THUDM/ChatGLM-6B
参考链接:[1]https://weibo.com/2126427211/MxlsQ6w4A#repost[2]https://chatglm.cn/blog?continueFlag=d70d7590143c950d12ac7283214d879d
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章







关于作者

猜你喜欢























