ChatGPT爆火出圈,国内很多高校、研究机构和企业都发出类似ChatGPT的发布计划。ChatGPT没有开源,复现难度极大,即使到现在GPT3的完全能力也没有任何一个单位或者企业进行了复现。刚刚,OpenAI又官宣发布了图文多模态的GPT4模型,能力相对ChatGPT又是大幅提升,似乎闻到了以通用人工智能主导的第四次工业革命的味道。
无论是国外还是国内,目前距离OpenAI的差距越来越大,大家都在紧锣密鼓的追赶,以致于在这场技术革新中处于一定的优势地位,目前很多大型企业的研发基本上都是走闭源路线,ChatGPT和GPT4官方公布的细节很少,也不像之前发个几十页的论文介绍,OpenAI的商业化时代已经到来。当然,也有一些组织或者个人在开源平替上进行了探索,本文章汇总如下,本人也会持续跟踪,有更新的开源平替及时更新此处或者本人github上:
https://github.com/chenking2020/FindTheChatGPTer
ChatYuanChatYuan(元语AI)是由元语智能开发团队开发和发布的,自称第一个国内最早的一个功能型对话大模型,可以写文章、写作业、写诗歌、做中英文间的翻译;一些法律等特定领域问题也可以提供相关信息。该模型目前只支持中文,github链接是:
https://github.com/clue-ai/ChatYuan基本原理:
从披露的技术细节看,底层采用7亿参数规模的T5模型,并基于PromptClue进行了监督微调形成了ChatYuan。该模型基本上是ChatGPT技术路线的三步的第一步,没有实现奖励模型训练和PPO强化学习训练。
 ChatGLM
ChatGLMChatGLM是清华技术成果转化的公司智谱AI开源的GLM系列的对话模型,支持中英两个语种,目前开源了其62亿参数量的模型。其继承了GLM之前的优势,在模型架构上进行了优化,从而使得部署和应用门槛变低,实现大模型在消费级显卡上的推理应用。详细技术可以参考其github:
https://github.com/THUDM/ChatGLM-6B
从技术路线上看,其实现了ChatGPT强化学习人类对齐策略,使得生成效果更佳贴近人类价值,其目前能力域主要包括自我认知、提纲写作、文案写作、邮件写作助手、信息抽取、角色扮演、评论比较、旅游建议等,目前其已经开发了正在内测的1300亿的超大模型,算是目前开源平替里面参数规模较大的对话大模型。

ChatGLM 自带前端对话演示系统
LLaMaLLaMA是由Facebook 母公司Meta发布的全新人工智能大型语言模型,在生成文本、对话、总结书面材料、证明数学定理或预测蛋白质结构等任务上方面表现良好。LLaMA模型支持20种语言,包括拉丁语和西里尔字母语言,目前看原始模型并不支持中文。
LLaMA目前比较火的两个顶流开源项目是ChatLLaMA和stanford_alpaca
ChatLLaMA是由Nebuly AI推出的基于人类反馈强化学习的LLaMA AI聊天机器人的开源实现,它的技术路线类似 ChatGPT,该项目上线刚刚 2 天,狂揽 5.2K 星。其github地址是:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA 训练过程算法实现主打比 ChatGPT 训练更快、更便宜,据说能快近15倍,主要特色有:
完整的开源实现,允许用户基于预训练的 LLaMA 模型构建 ChatGPT 风格的服务;LLaMA 架构更小,使得训练过程和推理速度更快,成本更低;内置了对 DeepSpeed ZERO 的支持,以加速微调过程;支持各种尺寸的 LLaMA 模型架构,用户可以根据自身偏好对模型进行微调。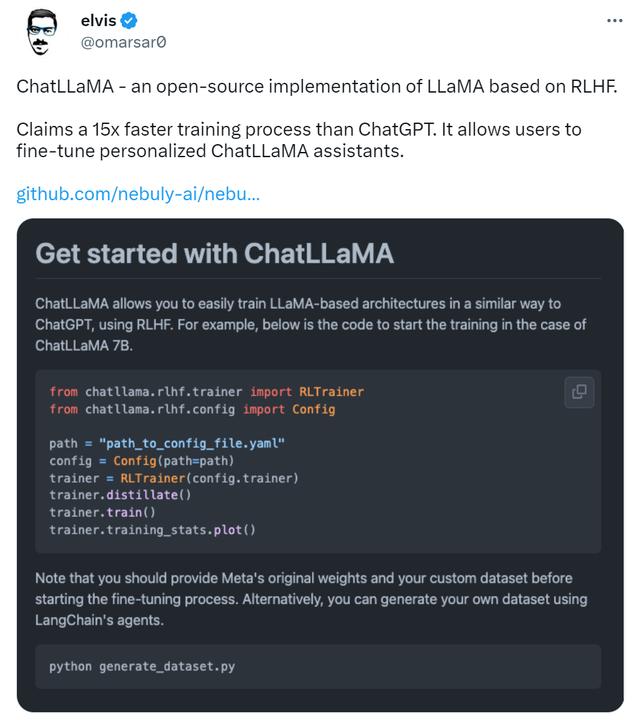
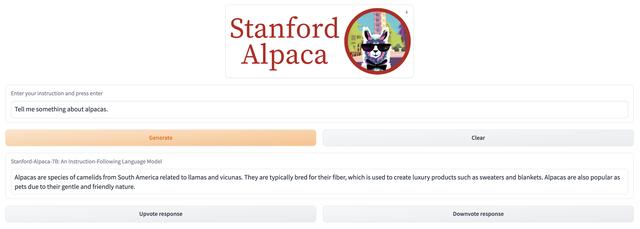
另外一个比较火的是最近刚发布的alpaca(羊驼模型),是由斯坦福基于 Meta 的 LLaMA 7B 模型微调出一个新模型,其基本原理是让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令样本,以此来微调LLaMA。该项目已将训练数据、生成训练数据的代码和超参数开源,模型文件尚未开源,以一天多达到5.6K星的关注度,估计很快会开源其模型文件供大家使用。其github地址为:
https://github.com/tatsu-lab/stanford_alpaca
同时公布了一个DEMO地址:
https://alpaca-ai-custom6.ngrok.io
 OpenChatKit
OpenChatKitOpenChatKit由前OpenAI研究员所在的Together团队,以及LAION、Ontocord.ai团队共同打造。OpenChatKit包含200亿个参数,用GPT-3的开源版本GPT-NoX-20B进行微调。同时,不同ChatGPT的强化学习,OpenChatKit采用一个60亿参数的审核模型,对不合适或者是有害的信息进行过滤,确保生成内容的安全和质量。其github地址为:
https://github.com/togethercomputer/OpenChatKit
BELLE基于 Stanford Alpaca ,实现基于Bloom的监督微调。Stanford Alpaca 的种子任务都是英语,收集的数据也都是英文,该开源项目是促进中文对话大模型开源社区的发展,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。项目包含以下内容:
175个中文种子任务生成数据的代码2M生成的数据基于BLOOMZ-7B1-mt优化后的模型github地址为
相关文章









关于作者

猜你喜欢























