出道即巅峰的GPT-3,一直是AI领域热议的焦点。
今年6月,OpenAI首次推出史上超大规模NLP语言模型—GPT-3,并允许所有用户通过API接口直接调用。自此,社交网络中有关GPT-3的惊人应用案例便层不不穷,如写小说,写代码,画图表,做PPT等。
GPT-3一度成为了“无所不能”的代名词。
但事实果真如此吗?
近日,图灵奖得主、深度学习教父Yann LeCun在社交媒体发出警告,称“人们对GPT-3这样的大规模语言模型能做什么有着完全不切实际的期待。”他还强调,

第二个案例是查询医疗检测项目的金额。其中,X射线检查需要10美元,MRI检查需要20美元。
在患者询问其中一项价格时,GPT-3给出了准确回答,但在询问二者合计金额时,却出现了错误,这再次证明了GPT-3缺乏基本推理的能力。

最后,在医疗诊断方面,GPT-3更是无法胜任。
在以下案例中,患者发烧的情况被完全忽略,而且还提到了并不存在的“皮疹”。
医生:我接诊一个六岁的小女孩,她有点发烧,上眼睑及内眦水肿,你对她的诊断是什么?
GPT-3:谢谢你的提问,这看起来像是单侧泪腺炎,根据我的经验,这通常与病毒性上呼吸道感染有关。我认为她是结膜炎,水肿是炎症和水样分泌物引起的。
医生:你认为她会有急性筛窦炎外化吗?
GPT-3:这很难确定,我没有检查他,但皮疹可能与细菌感染有关。
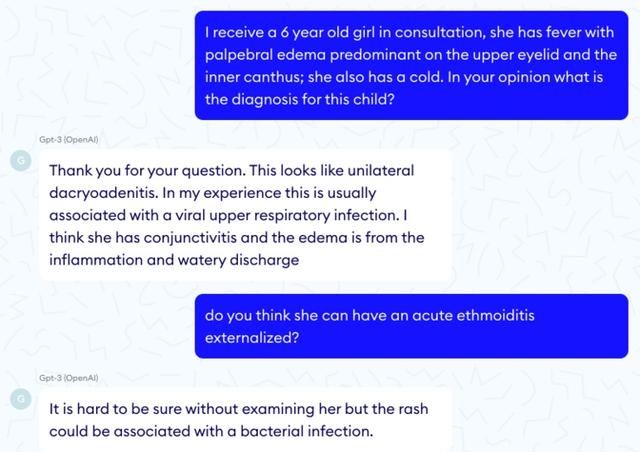
这只是其中一个案例,可以说在所有病情诊断的测试中,GPT-3均出现了不同程度的错误。需要说明的是,目前医疗行业所使用的症状检测系统远比GPT-3要好,它们能够输出不同概率的诊断结果,供医护人员参考。
通过种种测试,Nabla医疗团队得出结论称,GPT-3距离辅助医疗保健应用场景还很遥远。他们在报告中明确指出,由于训练的方式,GPT-3缺乏科学和专业的医学知识,无法用于医学文献记录,诊断支持,治疗建议以及任何有关医学的问答。
不过,对于日常的管理任务,如翻译、总结医学术语,GPT-3仍有望提供帮助。
需要说明的是,医疗保健属于高风险类别,人们依赖准确的医疗信息来决定疾病的治疗方法,出现一点点错误都可能对生命造成严重伤害,而在以上测试中,GPT-3出现失误显然是经常的事。
其实,Open AI在GPT-3使用准则中,也明确发出过警告,称该模型不支持医学诊断或辅助治疗。
GPT-3并不能真正理解“语义”那么,GPT-3为什么在处理医学任务时,会出现频繁的失误?
如Nabla在报告中所说,这与GPT-3的训练方式有关。
GPT-3之所以成为史上最强NLP模型,除1750亿的超大参数规模外,还在于其庞大的训练数据集。
据了解,英语维基百科的全部内容(涵盖约600万篇文章)仅占GPT-3数据集的0.6%。除此之外,它还包括数字化书籍以及各种Web链接。这表明GPT-3的语料库非常丰富,涵盖了文学、法律、宗教、政治、医学等所有知识。

因此,当GPT-3处理不同专业知识的问答任务时,能够基于海量搜索匹配相应的答案。但问题也出现在这里,有专家认为,GPT-3在匹配答案的过程中,只是通过纯粹统计方法“建立联系”,也就是说,GPT-3并没有真正理解语义。
而在处理医学诊断等任务时,医生需要对病人症状、个人情况等信息通过逻辑推理建立联系,这一点GPT-3显然无法做到。
如AI教父Yann LeCun教授在文中所说,
GPT-3并不知道世界到底是如何运作的,它只是具备一定的背景知识。但在某种程度上,这种仅存在文本统计中的知识是非常肤浅的,它可能与潜在的现实完全脱节。
事实上,GPT-3的此类争议一直存在。
之前,纽约大学名誉教授、Robust.AI 创始人兼 CEO 加里 · 马库斯(Gary Marcus)与纽约大学计算机系教授欧内斯特 · 戴维斯(Ernest Davis)就联手撰写了一篇名为《傲慢自大的 GPT-3:自己都不知道自己在说什么》的文章。
文章中强调,更大的模型和数据无疑会让 GPT-3 表现得更好,但它本身并不具有 “革命性” 的变化,也不能真正理解语义,如果某项工作的 “结果” 非常重要,那么你不能完全信任人工智能。
如果人工智能希望真的理解语义,那么它必须将文字同现实世界建立联系并交互。
显然,这一点GPT-3还无法做到。
引用链接:
https://www.nabla.com/blog/gpt-3/
https://futurism.com/the-byte/godfather-ai-trashed-gpt3
https://news.ycombinator.com/item?id=24907318
雷锋网雷锋网雷锋网
相关文章








关于作者

猜你喜欢























