机器之心报道
机器之心编辑部
大模型的涌现能力经得起推敲吗?
自 ChatGPT 发布以来,大模型的涌现能力一直被人们称赞,包括强大的语言理解能力、生成能力、逻辑推理能力等。然而,最近一项研究表明,大模型在因果推理方面普遍性能很差,连 GPT-4 都不及格。
这项研究是由来自马克斯・普朗克研究所、苏黎世联邦理工学院(ETH)、密歇根大学、香港大学和 Meta AI 的研究者们共同完成的。研究目标就是探究大型语言模型(LLM)是否能根据相关性进行因果推理。

基于 CORR2CAUSE 数据集,该研究主要分析两个问题:
现有的 LLM 在此任务上表现如何?
现有的 LLM 是否可以针对此任务进行重新训练或重新定位并获得强大的因果推理技能?
该研究通过实验表明,现有 17 个 LLM 在这个纯因果推理任务上表现均不佳。并且,尽管 LLM 在对数据进行微调后可以表现出更好的性能,但其因果推理技能并不稳健。
实验结果
现有 LLM 的 CORR2CAUSE 能力
如下表 4 所示,对于实验中所有 LLM 来说,纯因果推理都是一项非常具有挑战性的任务。其中,BART MNLI 的 F1 值最高,为 33.38%,甚至高于 GPT-4(29.08%)。值得注意的是,许多模型的表现比随机猜测还要差,这意味着它们在纯因果推理任务中完全失败。

微调后的性能
接下来要解决的问题是:能否让 LLM 重新学习这项任务?
从下表 5 (a) 中的实验结果来看,在 CORR2CAUSE 上进行微调的 12 个模型表现得比较好,大多数模型都获得了显著的性能提升。其中,基于 BERT 的 NLI 模型微调之后表现最佳,RoBERTa-Large MNLI 在这个任务上达到了 94.74% 的 F1 分数,以及非常高的精确度、召回率和准确率得分。
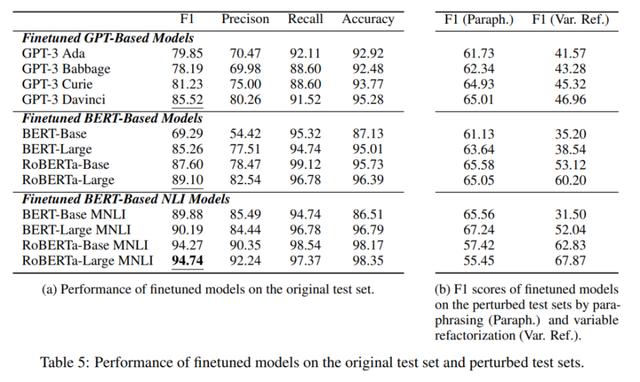
同时,上图 5 (b) 展示了受到干扰时各模型的实验结果,所有模型的性能都在急剧下降,表现最好的模型 RoBERTa-Large MNLI 则是性能下降最多的模型;然而,RoBERTa-Large MNLI 对变量重构最稳健,保持了 67.87 的较高 F1 分数。总的来说,现有 LLM 的稳健性比较差。
除了上述整体结果,该研究还进行了细粒度分析,以探索最强模型 RoBERTa-Large MNLI 在六种因果关系类型上的表现。
如下表 6 (a) 所示,RoBERTa-Large MNLI 模型在判断关系方面表现非常好,例如「Is-Parent」、「Is-Descendant」和「Has-Confounder」,这些 F1 分数都超过了 96%。然而,在「Has-Collider」关系上,它的表现稍微弱一些。这可能是因为 collider 关系是最特殊的类型,需要基于仅有的两个变量的无条件独立性和在有共同后代的条件下的相关性来识别 V-structure。

感兴趣的读者可以阅读论文原文,了解更多研究细节。
相关文章







关于作者

猜你喜欢























