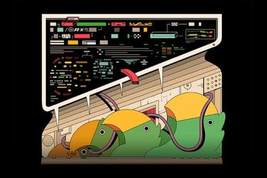
在后端代码(backend)中调用了OPENAI API及其他的服务,如图1-10所示。

图1- 10 后端代码调用OpenAI API
openai_requests.py是一个相对比较简单的代码文件,在生产级开发中,一般都会有一个模型层,会分成前端、后端、模型这三个层次,设置模型层有一个很重要的点,无论是开发还是架构,能力不断进步或者解决问题的过程,其实就是解耦合的一个过程。在实际生产级别,会把模型作为一个具体的服务,在服务内部可以做很多事情,这是模型即服务(model as a service)。我们这个项目有好几个版本,现在给大家展示的版本是一个端到端完整可运行的项目,让大家感受一下,基于大模型驱动的对话机器人的整个开发流程以及具体的实现,从企业级的角度,有前端、后端、模型层,在这里我们简化了这个过程,在代码中,给大家写了非常清晰的注释,结合整个流程图,读者会很清晰的感受到它具体的执行过程以及代码本身的组织方式。
我们主要讲解后端,为了帮助大家学习,在后端跟大家做了很详细的日志记录,将所有的日志都输出到Chatbot_backend.log日志文件中,在这里面会显示具体的详细过程。
main.py的代码实现:
# uvicorn main:app# uvicorn main:app --reload# 导入库from fastapi import FastAPI, File, UploadFile, HTTPExceptionfrom fastapi.responses import StreamingResponsefrom fastapi.middleware.CORS import CORSMiddlewarefrom decouple import configimport openai# 自定义函数导入from functions.text_to_speech import convert_text_to_speechfrom functions.openai_requests import convert_audio_to_text, get_chat_responsefrom functions.database import store_messages, reset_messagesimport logginglogging.basicConfig(level=logging.DEBUG,format="%(asctime)s %(levelname)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S",filename="chatbot_backend.log")logger = logging.getLogger("Chatbot main.py fle Backend")""" 获取环境变量在这段代码中,config函数用于从环境变量中检索值。OPEN_AI_ORG和OPEN_AI _KEY环境变量应分别包含OpenAI的组织名称和API密钥。执行提供的代码后,openai.organization变量将被设置为“my_organization”,openai.api_key变量将被设为“my_api_key”。这些值随后可以在代码中使用,以使用指定的组织和API密钥验证OpenAI API并与之交互。"""openai.organization = config("OPEN_AI_ORG")openai.api_key = config("OPEN_AI_KEY")"""启动应用程序在这段代码中,创建了一个FastAPI类的实例,它表示FastAPI应用程序。此实例将用于定义应用程序的路由、端点和其他配置。"""# 创建 FastAPI 类的新实例,并将其分配给变量 appapp = FastAPI()"""在该示例中,我们从FastAPI模块导入FastAPI类。然后,我们创建一个新的FastAPI实例,并将其分配给变量应用程序。这使我们能够使用应用程序实例来定义FastAPI应用程序的行为和路由。""""""CORS - Origins在这段代码中,创建了来源列表,并用URL填充。这些URL表示允许的来源或域允许向服务器发出请求。CORS(跨来源资源共享)是一种允许web浏览器发出请求的机制到与提供网页的域不同的域。通过指定允许的来源,服务器可以控制哪些域被允许访问其资源。"""# 创建一个名为“origins”的列表,其中包含多个作为字符串的URL# origins = [# "http://localhost:5173",# "http://localhost:5174",# "http://localhost:4173",# "http://localhost:3000",# ]origins = ["*",]"""在上面的示例中,原点列表由三个URL定义,这些URL可以根据应用程序的具体要求进行定制。在代码的后面,源列表可以在CORS中间件或其他配置中使用,以允许来自指定域的跨源请求。""""""在下面的代码中,将CORS中间件添加到具有所需配置的应用程序中,包括allow_origins、allow_credentials、allow_methods和allow_headers参数。这确保了FastAPI应用程序正确处理CORS请求,并允许根据指定的配置进行跨源通信。CORS中间件被添加到FastAPI应用程序(应用程序)中。CORS中间件负责处理跨源资源共享并管理HTTP响应中与CORS相关的头。在应用程序对象上调用add_Middleware方法来添加CORS中间件。使用CORSMiddleware类,并传递几个参数来配置其行为:allow_origins:指定允许请求的允许来源(域)。它采用了之前定义的起源列表。allow_credentials:指示是否允许在CORS请求中发送和接收凭据,如cookie或授权标头。在本例中,它设置为True。allow_methods:为CORS请求指定允许的HTTP方法。值[“*”]允许所有方法。allow_headers:为CORS请求指定允许的HTTP标头。值[“*”]允许所有标头。"""# CORS -中间件app.add_middleware(CORSMiddleware,allow_origins=origins,allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)"""使用HTTPGET方法为/health路径定义了一个路由处理程序。@app.get-decorator用于将处理程序函数check_health与此特定路由相关联。check_health函数是一个异步函数(async-def),用于处理传入请求并返回指示健康状态的JSON响应。"""# Check health@app.get("/health")async def check_health():logger.info(f'method check_health in main.py file is invoked')return {"response": "healthy"}# 重置对话@app.get("/reset")async def reset_conversation():reset_messages()logger.info(f'method reset_conversation in main.py file is invoked')return {"response": "conversation reset"}"""使用@app.post装饰器定义了一个端点,用于处理对/post-audio/的post请求。端点需要一个上传的音频文件,该文件作为名为file的UploadFile参数接收。该代码执行以下步骤:上载的音频文件将临时保存到磁盘。保存的音频文件在读取模式下以二进制文件的形式打开(audio_input)。使用convert_audio_to_text函数将音频文件解码为文本。保护子句检查音频解码是否成功。否则,将引发HTTP异常。使用get_chat_response函数基于解码的音频生成聊天响应。消息和聊天响应使用store_messages函数存储在数据库或任何其他存储机制中。另一个保护条款检查是否获得了有效的聊天响应。否则,将引发HTTP异常。聊天响应使用convert_text_to_speech功能转换为音频。guard子句检查音频转换是否成功。否则,将引发HTTP异常。定义了一个生成器函数(iterfile)来生成块中的音频输出。音频输出作为流式响应返回,媒体类型设置为“application/octet-stream”。"""# 使用post请求时不会在浏览器中播放@app.post("/post-audio/")async def post_audio(file: UploadFile = File(...)):logger.info(f'method post_audio in main.py file is invoked')# 要处理POST请求的终结点 "/post-audio/"# 暂时保存上传的音频文件with open(file.filename, "wb") as buffer:buffer.write(file.file.read())audio_input = open(file.filename, "rb")# 将音频文件解码为文本message_decoded = convert_audio_to_text(audio_input)# 确保音频解码成功if not message_decoded:logger.error(f'Failed to decode audio method post_audio in main.py file is invoked')raise HTTPException(status_code=400, detail="Failed to decode audio")# 根据解码的音频获取聊天响应chat_response = get_chat_response(message_decoded)# 将消息存储在数据库或任何其他存储机制中store_messages(message_decoded, chat_response)# 确保有效的聊天响应if not chat_response:logger.error(f'Failed chat response method post_audio in main.py file is invoked')raise HTTPException(status_code=400, detail="Failed chat response")# 将聊天响应转换为音频audio_output = convert_text_to_speech(chat_response)# 确保音频输出成功if not audio_output:logger.error(f'Failed audio output method post_audio in main.py file is invoked')raise HTTPException(status_code=400, detail="Failed audio output")# 创建一个生成音频块的生成器def iterfile():yield audio_outputlogger.info(f'COMPLETE SUCCESS in method post_audio in main.py file call')# 将音频作为具有媒体类型的流式响应返回 "application/octet-stream"return StreamingResponse(iterfile(), media_type="application/octet-stream")main.py代码实现了一个聊天机器人的后端服务,使用了Python的FastAPI框架和OpenAI的API。在最开始做设计的时候,FastAPI是最高效、也是最友好的框架,main.py代码的主要功能,初始化日志记录器,使用Python的logging模块记录日志;设置OpenAI的API密钥和组织;创建FastAPI应用程序实例;配置CORS中间件,以允许跨域请求;实现一个用于检查服务健康状态的端点/health;实现一个用于重置会话的端点/reset,该端点将清除所有之前的聊天记录;实现一个用于处理音频上传请求的端点/post-audio/,并将上传的音频文件转换为文本,然后将文本发送给聊天机器人,接收聊天机器人的响应并将其转换为音频输出。记录所有端点的调用情况和错误情况,使用日志记录器记录日志。
该代码的主要实现方法是使用FastAPI框架提供的装饰器来定义端点和处理函数,可以轻松地实现RESTful API的功能。此外,还使用了Python的logging模块来记录日志,以帮助开发人员更好地了解服务的运行状况和问题。另外,该代码使用了OpenAI的API来实现自然语言处理的功能,这是一种快速和方便的方式来实现聊天机器人的功能,实现了一个功能齐全,易于使用的聊天机器人后端服务。
上段代码中第140行,调用convert_audio_to_text方法,将用户的音频文件解码为文本。
OpenAI自己有Whisper的功能,可以做ChatGPT或者OpenAI API的开发,OpenAI有一个transcribe的方式,使用Whisper进行音频和文字的转换,这种API的调用,大家都不会有问题,而且注释也写得非常清楚。
openai_requests.py的convert_audio_to_text方法的代码实现:
"""convert_audio_to_text函数以audio_file作为输入,它表示要转换为文本的音频文件。该功能执行以下步骤:它使用OpenAI API通过Whisper模型转录音频文件。“whisper-1”参数指定用于转录的whisper模型的版本。转录的文本是从OpenAI API收到的响应中提取的。转录后的文本将作为函数的结果返回。"""# Open AI - Whisper#将音频转换为文本def convert_audio_to_text(audio_file):logger.info("method convert_audio_to_text in openai_requests.py file is called")try:# 使用OpenAI API转录使用Whisper模型的音频文件transcript = openai.Audio.transcribe("whisper-1", audio_file)# 从响应中提取转录的文本message_text = transcript["text"]# 返回转录后的文本return message_textexcept Exception as e:logger.error("Error happend in OpenAI Audio Transcribe in method convert_audio_to_text in openai_requests.py file")return上段代码中第148行,调用get_chat_response方法,根据解码的音频文本,发送给OpenAI的API接口,获取聊天响应。
上段代码中第151行,收到信息之后,调用store_messages方法,将消息存储在数据库或任何其他存储机制中,这边存储在stored_data.json文件中,可以看见系统和用户的交互的内容。
stored_data.json的文件记录:
[{'role': 'assistant', 'content': "As an AI language model, I don't have emotions, so I don't have good or bad days. However, I'm always ready to helpwith any task you need assistance with."},{'role': 'user', ' content': 'Hi, how are you doing today?'},{'role': 'assistant', 'content': "Hello! As an AI language model, I'm just a computer program, soI don't have emotions or feelings. But I " m functioning properly and ready to assist you with any task you need help with!"},{'role': 'user', 'content': "Wow, that's great to know. So what can you do? Tell me what specifically you can do for me.Please use English to provide your response"}]
上段代码中第159行,调用convert_text_to_speech方法,将聊天响应转换为音频,在text_to_speech.py文件的convert_text_to_speech方法中调用了api.elevenlabs.io接口,并设置API keys和环境的内容,包括OPEN_AI_KEY、ELEVEN_LABS_API_KEY等。
text_to_speech.py的convert_text_to_speech方法的代码实现:
import requestsfrom decouple import configimport logginglogging.basicConfig(level=logging.DEBUG,format="%(asctime)s %(levelname)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S",filename="chatbot_backend.log")logger = logging.getLogger("Chatbot text_to_speech.py file Backend")# 从环境变量中获取`ELEVEN_LABS_API_KEY`的值ELEVEN_LABS_API_KEY = config("ELEVEN_LABS_API_KEY")"""导入请求库以发出HTTP请求,使用decouple的config函数从环境变量中检索ELEVEN_LABS_API_KEY的值。convert_text_to_speech函数采用消息参数并执行以下步骤:它定义了请求主体,包括要转换的文本和语音设置。定义了不同语音的语音ID(例如,Voice_shaun、Voice_rachel、Voice_antoni)。构造了请求头和URL端点,包括ELEVEN_LABS_API_KEY。try-except块用于处理请求过程中可能发生的任何异常。requests.post方法用于向Eleven Labs API发送post请求,其中包含提供的正文和头。如果响应的状态代码为200(表示成功),则返回在响应中接收到的内容(音频数据)。如果响应具有任何其他状态代码,则返回None。"""def convert_text_to_speech(message):logger.info(f'method convert_text_to_speech in text_to_speech.py file is invoked')# 定义文本到语音转换的请求正文body = {"text": message,"voice_settings": {"stability": 0,"similarity_boost": 0}}# 为不同的语音定义语音IDvoice_sam = "xxxx"voice_gavin = " xxxx "voice_chris = " xxxx "# 构造请求 头和URheaders = {"xi-api-key": ELEVEN_LABS_API_KEY,"Content-Type": "application/json","accept": "audio/mpeg"}endpoint = f"https://api.elevenlabs.io/v1/text-to-speech/{voice_gavin}"try:# 向Eleven Labs API发送POST请求response = requests.post(endpoint, json=body, headers=headers)except Exception as e:logger.error(f'Error happened when Send the POST request to the Eleven Labs API in method convert_text_to_speech in text_to_speech.py file is invoked')returnif response.status_code == 200:# 返回响应中接收到的内容(音频数据)return response.contentelse:logger.error(f'Error happened when Send the POST request to the Eleven Labs API with code {response.status_code}')return为了帮助大家学习,我们重点看一下和OpenAI大模型的交互,设置OPEN_AI_ORG、OPEN_AI_KEY等相关的内容,调用gpt-3.5-turbo模型,输入模型信息,这个信息本身,我们统一称之为提示词,它有4大核心的组件。gpt-3.5-turbo大模型是大家做实验的时候经常使用的,不过作者现在所在的公司及所做的项目,正常都使用GPT4,GPT4才是一个真正划时代的大模型,因为它的推理能力太强大了。
openai_requests.py的get_chat_response方法:
…openai.organization = config("OPEN_AI_ORG")openai.api_key = config("OPEN_AI_KEY")…"""get_chat_response函数采用message_input参数,该参数表示用户对聊天机器人的输入消息。该功能执行以下步骤:它使用get_recent_messages函数从数据库或存储中检索最近的聊天消息。它根据用户提供的message_input创建一个新的用户消息,并附加与语言使用相关的附加说明。新用户消息将添加到现有消息中。打印这些消息进行调试。OpenAI聊天完成API使用OpenAI.ChatCompletion.create方法调用,将消息作为输入传递,以生成聊天响应。生成的消息文本是从API响应中提取的。生成的消息文本将作为函数的结果返回。"""# Open AI - Chat GPT# 获取聊天响应def get_chat_response(message_input):logger.info("method get_chat_response in openai_requests.py file is called")# 从数据库或存储中检索最近的信息messages = get_recent_messages()# 根据输入创建新的用户消息user_message = {"role": "user","content": message_input " Please use English to provide your response"}# 将新用户消息附加到现有消息messages.append(user_message)# 打印消息以进行调试print(messages)logger.info(f'method get_chat_response existing messages {messages}')try:# 调用OpenAI聊天完成API生成聊天响应response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages)# 从API响应中提取生成的消息文本message_text = response["choices"][0]["message"]["content"]logger.info(f'method get_chat_response message from OpenAI API call {message_text}')# 返回生成的消息文本return message_textexcept Exception as e:logger.error("Exception in calling OpenAI api")return1.5 ChatGPT语音聊天机器人改进但是这里面有一个很重要的问题,从企业级的角度,模型产出的结果可能不符合你的预期,这边有三种情况,第一种是满意度不高,模型给的回复可能是一部分是正确的,但另外一部分是很有问题的;第二种是模型给的结果是错的;第三种是模型给的结果根本就不相关。不相关和错误的结果,其实是两种类型,因为不相关表明模型根本就不理解你输入的内容是什么,这也再次说明了提示词的重要性。如果出现这种情况,怎么去处理?基于大模型应用程序的开发,结果是很重要的新的上下文,这类似于贝叶斯Bayesian,整个Transformer架构是NLP思想的一个实现,如果它出现了问题,三种类型是部分正确、错误以及不相关,无论是什么信息,模型进一步优化它的结果新的上下文,这是贝叶斯Bayesian基本思想的一个表现。
作者收到美国一个大学教授分享的一篇MIT的论文,论文背后有很多数学的部分,相信这篇论文应该是一个非常愉悦的阅读体验,因为作者最近在做一个很重要的工作,是有状态提示词(stateful prompting),如果读者感兴趣,可以跟作者进一步深度交流,MIT这篇论文的基本思想和现在的思维链提示词(CoT)不一样,它针对目前已有的问题,使用一种链式的过程,把不同对话中的提示词形成一个链条,然后基于这个链条形成一个上下文,类似于天气预报,昨天的天气情况大概率会影响今天的天气,今天的天气和昨天的天气大概率会影响明天的天气,论文使用了这个思想。从项目的角度或者做企业级最佳实践的角度,无论使用模型,还是对模型本身的结果进行优化,其实一个核心性的组件,都是更明确清晰的上下文,而结果无论是部分正确或部分错误、还是错误的结果、或者完全不相关的结果,这些都是至关重要的上下文。大家通过朴素贝叶斯的思想,比较容易知道概率模型,在重试的时候,不要以简单粗暴方式重试,而应该拿上这个结果,加上你的判断进行重试,你看见那个结果,告诉它不正确,然后你重新生成,这也会有效果,在很多情况下,你应该设立好自己的框架,一个很重要的技术叫Langchain,它做的一个很重要的工作,就是帮你封装了部分此类的操作。
本节跟大家分享了一个很重要的企业级的最佳实践,通过提供一个端到端的项目,大家体验一下基于大模型驱动的应用程序。
《企业级ChatGPT开发入门实战直播21课》报名课程请联系:
Gavin老师:NLP_Matrix_Space
Sam老师:NLP_ChatGPT_LLM
我们的两本最新书籍年底即将出版:
《企业级Transformer&ChatGPT解密:原理、源码及案例》《企业级Transformer&Rasa解密:原理、源码及案例》《企业级Transformer&ChatGPT解密:原理、源码及案例》本书以Transformer和ChatGPT技术为主线,系统剖析了Transformer架构的理论基础、模型设计与实现,Transformer语言模型GPT与BERT,ChatGPT技术及其开源实现,以及相关应用案例。内容涉及贝叶斯数学、注意力机制、语言模型、最大似然与贝叶斯推理等理论,和Transformer架构设计、GPT、BERT、ChatGPT等模型的实现细节,以及OpenAI API、ChatGPT提示工程、类ChatGPT大模型等应用。第一卷介绍了Transformer的Bayesian Transformer思想、架构设计与源码实现,Transformer语言模型的原理与机制,GPT自回归语言模型和BERT自编码语言模型的设计与实现。第二卷深入解析ChatGPT技术,包括ChatGPT发展历史、基本原理与项目实践,OpenAI API基础与高级应用,ChatGPT提示工程与多功能应用,类ChatGPT开源大模型技术与项目实践。
ChatGPT 技术:从基础应用到进阶实践涵盖了ChatGPT技术和OpenAI API的基础和应用,分为8个章节,从ChatGPT技术概述到类ChatGPT开源大模型技术的进阶项目实践。
1. ChatGPT技术概述:主要介绍了GPT-1、GPT-2、GPT-3、GPT-3.5和GPT-4的发展历程和技术特点,以及ChatGPT技术的基本原理和项目案例实战。
2. OpenAI API基础应用实践:主要介绍了OpenAI API模型及接口概述,以及如何使用OpenAI API进行向量检索和文本生成。
3. OpenAI API进阶应用实践:主要介绍了如何使用OpenAI API基于嵌入式向量检索实现问答系统,如何使用OpenAI API对特定领域模型进行微调。
4. ChatGPT提示工程基础知识:主要介绍了如何构建优质提示的两个关键原则,以及如何迭代快速开发构建优质提示。
5. ChatGPT提示工程实现多功能应用:主要介绍了如何使用ChatGPT提示工程实现概括总结、推断任务、文本转换和扩展功能。
6. ChatGPT提示工程构建聊天机器人:主要介绍了聊天机器人的应用场景,以及如何使用ChatGPT提示工程构建聊天机器人和订餐机器人。
7. 类ChatGPT开源大模型技术概述:主要介绍了类ChatGPT开源大模型的发展历程和技术特点,以及ChatGLM项目案例实践和LMFlow项目案例实践。
8. 类ChatGPT开源大模型进阶项目实践:主要介绍了类ChatGPT开源大模型的进阶项目实践,包括基于LoRA SFT RM RAFT技术进行模型微调、基于P-Tuning等技术对特定领域数据进行模型微调、基于LLama Index和Langchain技术的全面实践,以及使用向量检索技术对特定领域数据进行模型微调。
本书适用于NLP工程师、AI研究人员以及对Transformer和ChatGPT技术感兴趣的读者。通过学习,读者能够系统掌握Transformer理论基础,模型设计与训练推理全过程,理解ChatGPT技术内幕,并能运用OpenAI API、ChatGPT提示工程等技术进行项目实践。
Transformer作为目前NLP领域最为主流和成功的神经网络架构,ChatGPT作为Transformer技术在对话系统中的典型应用,本书内容涵盖了该领域的最新进展与技术。通过案例实践,使理论知识变成技能,这也是本书的独特之处。
《企业级Transformer&Rasa解密:原理、源码及案例》:是一本深入介绍Rasa对话机器人框架的实战开发指南。本书分为两卷,第一卷主要介绍基于Transformer的Rasa Internals解密,详细介绍了DIETClassifier和TED在Rasa架构中的实现和源码剖析。第二卷主要介绍Rasa 3.X硬核对话机器人应用开发,介绍了基于Rasa Interactive Learning和ElasticSearch的实战案例,以及通过Rasa Interactive Learning发现和解决对话机器人的Bugs案例实战。
第一卷中介绍了Rasa智能对话机器人中的Retrieval Model和Stateful Computations,解析了Rasa中去掉对话系统的Intent的内幕,深入研究了End2End Learning,讲解了全新一代可伸缩的DAG图架构的内幕,介绍了如何定制Graph NLU及Policies组件,讨论了自定义GraphComponent的内幕,从Python角度分析了GraphComponent接口,详细解释了自定义模型的create和load内幕,并讲述了自定义模型的languages及Packages支持。深入剖析了自定义组件Persistence源码,包括自定义对话机器人组件代码示例分析、Resource源码逐行解析、以及ModelStorage、ModelMetadata等逐行解析等。介绍了自定义组件Registering源码的内幕,包括采用Decorator进行Graph Component注册内幕源码分析、不同NLU和Policies组件Registering源码解析、以及手工实现类似于Rasa注册机制的Python Decorator全流程实现。讨论了自定义组件及常见组件源码的解析,包括自定义Dense Message Featurizer和Sparse Message Featurizer源码解析、Rasa的Tokenizer及WhitespaceTokenizer源码解析、以及CountVectorsFeaturizer及SpacyFeaturizer源码解析。深入剖析了框架核心graph.py源码,包括GraphNode源码逐行解析及Testing分析、GraphModelConfiguration、ExecutionContext、GraphNodeHook源码解析以及GraphComponent源码回顾及其应用源码。
第二卷主要介绍了基于Rasa Interactive Learning和ElasticSearch的实战案例,以及通过Rasa Interactive Learning发现和解决对话机器人的Bugs案例实战。介绍了使用Rasa Interactive Learning来调试nlu和prediction的案例实战,使用Rasa Interactive Learning来发现和解决对话机器人的Bugs案例实战介绍了使用Rasa Interactive Learning透视Rasa Form的NLU和Policies的内部工作机制案例实战,使用ElasticSearch来实现对话机器人的知识库功能,并介绍了相关的源码剖析和最佳实践,介绍了Rasa微服务和ElasticSearch整合中的代码架构分析,使用Rasa Interactive Learning对ConcertBot进行源码、流程及对话过程的内幕解密,介绍了使用Rasa来实现Helpdesk Assistant功能,并介绍了如何使用Debug模式进行Bug调试,使用Rasa Interactive Learning纠正Helpdesk Assistant中的NLU和Prediction错误,逐行解密Domain和Action微服务的源码。
本书适合对Rasa有一定了解的开发人员和研究人员,希望通过本书深入了解Rasa对话机器人的内部工作原理及其源代码实现方式。无论您是想要深入了解Rasa的工作原理还是想要扩展和定制Rasa,本书都将为您提供有价值的参考和指导。
《企业级Transformer&ChatGPT解密:原理、源码及案例》、《企业级Transformer&Rasa解密:原理、源码及案例》,是您深入学习的好选择,年底即将重磅出版,欢迎购买!
相关文章








关于作者

猜你喜欢























