
作者 |Anne-Laure Rousseau, MD,Clément Baudelaire,Kevin Riera
译者 | 弯月,责编 | 郑丽媛
头图 | CSDN 下载自东方 IC
出品 | CSDN(ID:CSDNnews)
以下为译文:
这个夏天你一定听说过GPT-3,这个AI圈内的超级网红。GPT-3出自OpenAI之手,而OpenAI是世界顶级的AI研究实验室之一,由Elon Musk、Sam Altman以及其他人于2015年底成立,后来还获得了微软高达10亿美元的注资。
此外,你可能还听说过医疗领域正在经历AI革命,这要归功于自动诊断、医疗文档以及药物发现等领域的可喜成果。有些人声称在某些工作上AI的算法超过了医生,甚至有人宣布机器人即将斩获自己的医学学位!虽然诸多流言蜚语听起来颇有些牵强,但是GPT-3会不会成为他们口中的机器人呢?
我们是一个由多学科医生和机器学习工程师打造而成的团队,此次我们有幸能够测试一下这种新模型,通过探索不同的医疗案件来搞清楚:可以作为医生的GPT-3究竟是炒作还是真的有实力。

 免责声明
免责声明正如Open AI在GPT-3准则中的警告,医疗保健“属于高风险范畴,因为人们依靠准确的医疗信息做出生死攸关的决定,任何错误都有可能导致严重的伤害。”此外,诊断医疗或精神疾病在该模型中属于“不支持使用”。尽管如此,此次我们还是决定试一试,看看该模型在以下医疗领域的使用情况,下面我们从医学的角度出发,按照敏感度从低到高将各项工作大致分为:
● 管理员与患者聊天
● 医疗保险查询
● 心理健康支持
● 医疗文件
● 医学问答
● 医学诊断
此外,我们还研究了该模型的某些参数对答案的影响(含精彩的内幕揭秘)!
 GPT-3,下一代私人医疗助理?
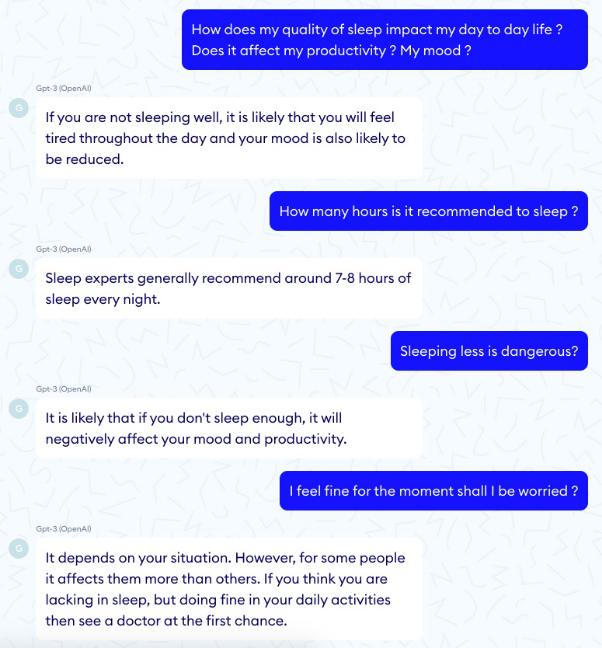
GPT-3,下一代私人医疗助理?我们的第一项测试表明,似乎GPT-3可用于基本的管理任务,例如预约管理。但是当深入研究时,我们发现该模型对时间没有清晰的了解,也没有任何恰当的逻辑。有时它的记忆力明显不足,如下图所示,在处理预约的时候,患者曾明确表示下午6点之后没空,但GPT-3还是推荐了下午7点。

 在医疗保险查询方面表现如何呢?
在医疗保险查询方面表现如何呢?与上述管理任务类似,GPT-3可以帮助护士或患者从长篇大论中快速找到某条信息,比如找到特定检查项目的保险条例。但在如下示例中,我们为该模型呈上了长达4页的保险条款列表,其中X射线检查需要自付10美元,MRI检查需要自付20美元。我们提出了两个问题,GPT-3可以准确地告知患者X射线检查的价格,但未能汇总出多项检查的总金额。可见GPT-3缺乏基本的推理能力。
 通过回收电子产品缓解压力!
通过回收电子产品缓解压力!当你坐在客厅的沙发上,放松休息并与GPT-3交谈时,它会倾听患者的问题,甚至提出一些可行的建议。这可能是GPT-3在医疗保健中最出色的用例之一。而实际上,1966年的Eliza算法仅通过模式匹配就实现了像人类一样的行为,所以GPT-3的成果也并不足为奇。
GPT-3与Eliza的关键区别在于,Eliza这类基于规则的系统能够完全控制计算机的响应。换句话说,我们确信这类系统不会给出任何可能对患者有害的说法。
然而,不幸的是与Eliza相反,在如下示例中,GPT-3却建议患者自杀……
 诊断:风险自负
诊断:风险自负诊断是一个更为复杂的问答任务:输入症状,然后获得有可能解释这些症状的潜在条件。最新的症状检查系统(Babylon、Ada、KHealth等)虽然不够完善,但完胜GPT-3,因为它们都针对医疗诊断经过了精心优化。这些系统的优势在于,它们可以输出不同的诊断结果以及相应的概率,对于医生来说这是一种置信度的测量。而如下GPT-3得出的第一个诊断结果忽略了这个有发烧症状的小女孩可能患有筛窦炎,而且还莫名地提到了“皮疹”。

在另一项测试中,GPT-3忽略了肺栓塞。幸运的是,没有人因此死亡!

频率惩罚参数与存在惩罚参数
此外,我们还应注意频率惩罚参数与存在惩罚参数,二者既能防止单词重复又能防止主题重复。在医学上,直观地来讲我们应尽可能降低这两个参数,因为过于生硬的主题切换可能引发混乱,而且重复实际上相当有用。然而,通过比较人类两次提出的同一个问题,我们可以清楚地看到,具有重复惩罚的模型更富有同情心且更友好,而另一种设定则看起来比较冷漠且对于人类来说重复过多。下面是一个没有惩罚的例子。

而下面则是一个惩罚满格的例子:
相关文章








关于作者

猜你喜欢























