虽然GPT-3已经发布了很长一段时间,因为它在编写类似人类的故事和诗歌方面的卓越能力而受到广泛关注,但我从来没有想到它附带的API能够为构建具有广泛应用程序的数据产品提供如此大的灵活性和方便性。
在本文中,我试图探索一些与我在就业市场中看到的问题相关的用例,并试图理解构建基于语言的数据产品在未来可能只是围绕着“即时工程”。
与此同时,本文并不试图解释GPT-3是如何工作的,也不试图解释它如何能够完成它正在做的事情。关于这些话题的更多细节已经在Jay Alammar[1]和Max Woolf[2]等文章中写得很详细。GPT-3论文本身可以在[3]中引用。

问题
在这个问题中,一个客户试图找到市场上最相关的工作。招聘广告应该按什么顺序展示给他/她?
现实中解决这个问题的现有方法实际上比我提出的要复杂得多。在个性化时代,向用户展示的内容在很大程度上取决于一些因素,如最近的浏览行为、个人资料等。
为了将问题空间限制在一个更易于管理的范围内,我们首先集中精力确定我们认为广告可能属于哪一种工作类别。如果不是因为单词会根据使用的上下文有不同的意思,这个任务一开始看起来很简单。
解决方案
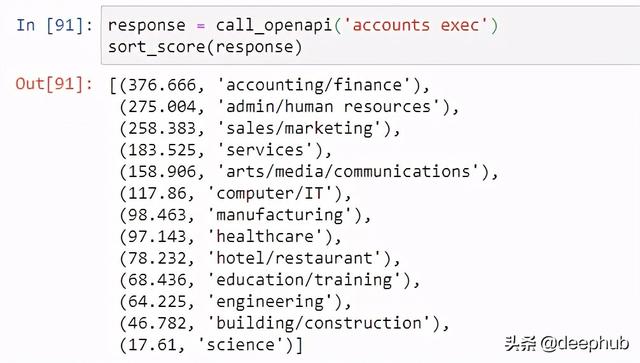
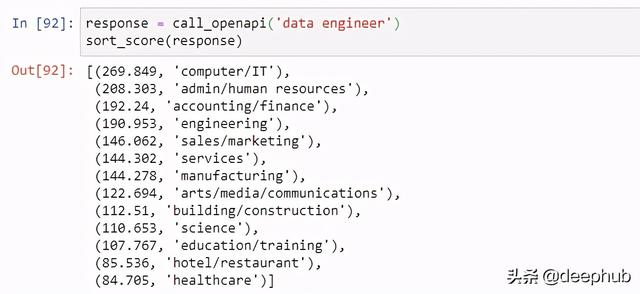
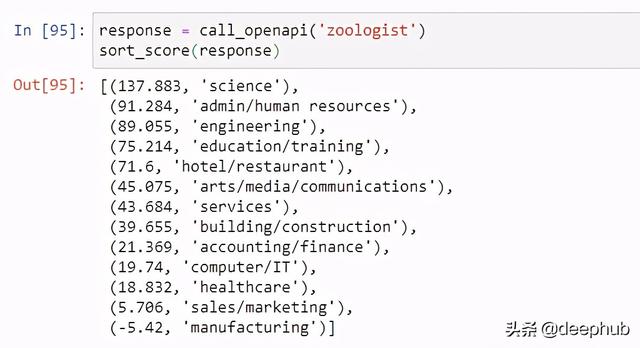
基于提供的职位名称,我们试图根据职位分类的语义相似度得分的顺序对固定数量的职位分类进行排序。
正如前面所做的,第一步是为API配置正确的提示符。
# based on job classification on jobstreet.comjob_classification = ["accounting/finance","admin/human resources","sales/marketing","arts/media/communications","services","hotel/restaurant","education/training","computer/IT","engineering","manufacturing","building/construction","science","healthcare"]def call_openapi(query, documents=job_classification):response = openai.Engine("ada").search(documents = documents,query=query, max_rerank=5)return responsedef sort_score(response,documents=job_classification):response_scores = [i.score for i in response.data]zipped_list = zip(response_scores,documents)sorted_zipped_lists = sorted(zipped_list, reverse=True)return sorted_zipped_lists
对于这个任务,我们使用GPT-3中的' search '模块(与前面的' completion '模块相反)。这将确保我们不是试图完成前面给出的提示(如前面的用例),而是要求API返回查询之间的语义相似度评分(即。职位名称)及参考文件(如:工作分类清单)。
一旦出现提示,我们就可以继续测试API。下面的示例演示了一般情况下,只需使用GPT-3就可以对作业分类进行开箱即用的分类,而不需要任何进一步的微调。但是,请注意,这是基于当前的测试设置和小样本,因此,里程可能会有所不同。
 案例3:从简历中解析技能上下文
案例3:从简历中解析技能上下文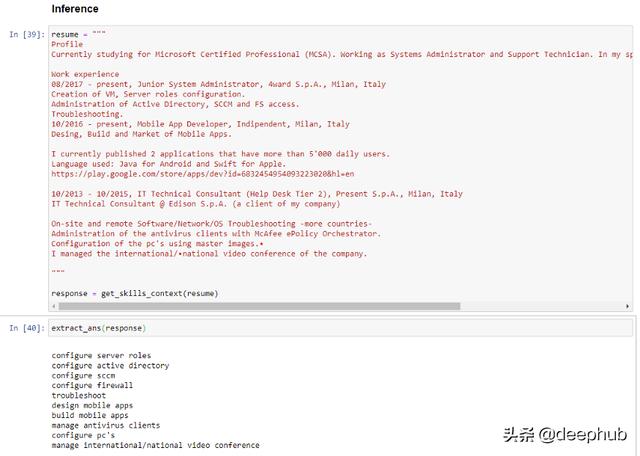
问题
我们希望在提供的招聘广告或简历的基础上,能够从中提取出某些信息,以帮助我们更好地匹配求职者和招聘广告。
虽然我们可以从一份简历/广告中提取很多信息(比如技术技能、工作经历、过去的教育经历等),但在这个用例中,我们将专注于提取软技能。
解决方案
解决这个问题最简单的方法是依靠一个软技能字典,并基于精确匹配或某种形式的字符串相似度算法在一组阈值内提取关键字。虽然一开始很有效,但很快就会被这些问题包围:
所提取的软技能与我们想要的内容并不匹配(这并不是一种真正的技能,因此存在精确度问题)。我们无法用很多方式来描述他们的软技能(回忆问题)。
在我们提出的解决方案中,我们的目标是通过一些简历中典型的经历部分的例子来解决这个问题,并向它提供一些提取的软技能的例子。
def get_skills_context(resume):response = openai.Completion.create(engine="davinci",prompt="""This is a resume parser that extracts skills context from resume.resume: {resume1}parsed_contextual_skills: {extract1}###resume: {resume2}parsed_contextual_skills: {extract2}###resume: {resume3}parsed_contextual_skills: """.format(resume1 = resume_1, extract1 = extract_1,resume2 = resume_2,extract2 = extract_2,resume3 = resume),temperature=0.2,max_tokens=60,top_p=1.0,frequency_penalty=0.0,presence_penalty=0.0,stop=["###"])return responsedef extract_ans(response):return print(response.choices[0].text)
从高层次的角度来看,它似乎能够提炼出简历中提到的大部分技能。特别有趣的是标准化“配置”而不是使用“管理”(源自“管理”)的能力。它还能在列表中添加“配置防火墙”——这是一项在简历中根本没有提到的技能,但可能从F5、McAfee等其他工具的存在中有所暗示。
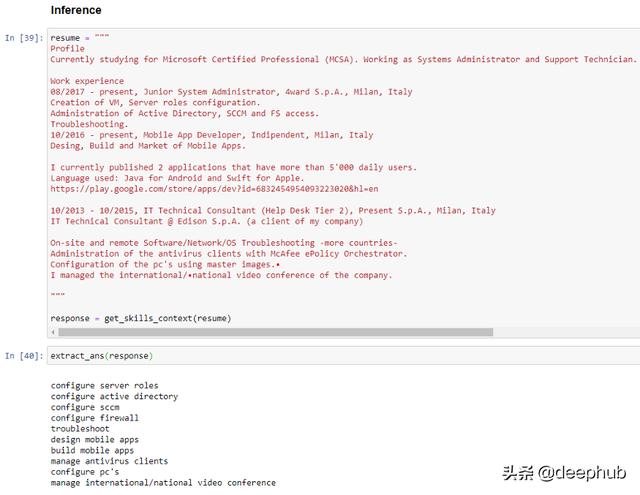
之前不得不构建一些类似的东西(使用Spacy、Databricks和许多手动维护的字典等工具的组合),解决方案构建的简单性(比如。记事处理)结合输出导出的质量-使我更欣赏GPT-3。
总结本文首先简要介绍了即时工程,然后快速转移到可能适用于GPT-3的就业市场行业中的一些相关用例。
每个数据产品构建的简易性(通过提示),以及我们从中得到的结果——证明了GPT-3在成为解决基于语言的任务的通用工具方面具有巨大的潜力。
话虽如此,与构建任何数据产品一样,仍然需要更彻底和全面的验证测试来确定GPT-3可能存在的差距和错误。然而,这不是本文的范围。
本文中使用的代码可以在我的git repo[6]中找到。
作者:Hafidz Zulkifli
相关文章









关于作者

猜你喜欢























