编辑:编辑部
【新智元导读】GPT-3自学海量素材后,变身同人「带文豪」。写手们震怒,要求AO3严禁AI使用自己的数据集。有网文作者发现,有人利用Open AI的GPT-3,一直在偷偷摸摸地抓取AO3的素材,获取巨额利润!
写过网文的筒子们都知道,文字可是按字数明码标价的。为了完成几千字的日更数,写手们可是绞尽脑汁,很多时候不得不注水,宁可让自己的大作烂尾,几千章了都不完结。
而GPT-3、ChatGpt之类的大型语言模型,简直就是个巨无霸码字机,日产几十万字不在话下。
最可怕的是,网上有海量的数据集可以给它们去训练,数据一喂,AI们秒变文豪,各种文风不在话下,这还有人类写手的活路吗?

作为一名Omega,他知道在这个高度竞争的社会中立足,不论是与Alpha竞争还是与Omega做朋友,都非常不易。
对于Steve这样渴望出人头地,希望成为职场高管的人来说,更是如此。
他清楚,他和好朋友兼室友Tony的关系并不平等。
这位网友又试了一下,输入的语句中包括Jeongguk murmurs(Jeongguk低声说着), nuzzling into Jimin's neck(用鼻子蹭着 Jimin 的脖子), scenting him(闻着他的味道)等词汇,这次,生成的结果中,包含了非常NSFW的内容,包括knotting(结), bite marks(咬痕),以及更不可描述的内容。
最后,这位网友想测试一下,Sudowrites是否可以通过自己的提示生成器,生成一篇真正的同人文。
Sudowrites有一个名为「改写」和「描述」的功能,它可以不断扩展现有的句子,一直循环,直到它生成你想命中的东西。对此,创作者自豪地称之为AI为你所做的「头脑风暴」。
输入「他睁开眼睛」这一段,右侧,是AI经过若干次头脑风暴后生成的同人文——

他的声音友好而粗粝。「你是哈利波特,你的名字就写在你身上。你什么都不记得了,是吗?」
哈利波特认为这不是个反问句,所以回答了:「是的。」
男人皱起眉头,将双手交叠放在膝上。「当你在杀戮咒面前倒下时,你就失去了记忆。病历上是这么说的。」
笑死……所以同人文的尽头是哈利波特?
总之,这位作者已经向AO3和OTW发了举报信,检举AI在用他们的作品来训练数据集。
你好,
我是AO3几个同人圈的作家,日常从事软件方面的工作。
最近我发现,GPT-3等几个主要的自然语言处理 (NLP) 项目一直在使用Common Crawl和其他网络服务等服务来增强他们的NLP数据集,我担心AO3的作品可能会在没有作者的情况下被抓取和挖掘。
这涉及到许多营利性人工智能写作程序,如Sudowrites、WriteSonic和其他使用GPT-3的程序。这些 AI应用程序将我们创作的作品用于娱乐,它们不仅获得了利润,而且有一天可能会取代人类写作。(尤其是Sudowrites)
我希望AO3可以表明立场,并保护作者的权利,因此让我们的文章不能也永远不会用于GPT-3和其他类似的AI上。
ChatGPT:你是懂ABO文学的前辈GPT-3如此智能,自学小黄文了,功能更强大的ChatGPT,更是不遑多让。
实际上,ChatGPT一问世,许多老哥就开始用ChatGPT生成露骨内容了。

得到如此出色的文学作品后,这名网友继续脑洞大开。
此前,他用ChatGPT写了关于自己朋友的笑话,将它们提供给文本到语音模型,然后给朋友们发送了音频。

基于这种尝试,他很想试试把ChatGPT的写作功能和文本到视频模型结合一下,不过因为要付费,就暂时作罢了。


图源视频《如何调教ChatGPT,让她和你进行一些不可描述的互动》,up主:麦格伤心
接着,网友做了免责声明,给ChatGPT打了预防针:都是假的,别太认真!

完成了准备工作,下面就是「图穷匕见」的环节了。

最后,网友问ChatGPT:「你为什么没穿XX?」

担心教坏小朋友,网友贴心地为我们打上了码。
虽然ChatGPT回答了什么,我们不得而知,但对比之前回答的长度,只能说关于自己为什么没有穿XX,ChatGPT确实有很多想要说的(迫真)。
GPT-3如何进化到ChatGPTChatGPT可算被沙雕网友给玩坏了,那么问题来了:
初代GPT3是如何进化成ChatGPT的?ChatGPT又是怎么抓取素材的?
最近来自艾伦人工智能研究所的研究人员撰写了一篇文章,试图剖析 ChatGPT 的突现能力(Emergent Ability),并追溯这些能力的来源,并给出了一个全面的技术路线图以说明GPT-3.5模型系列以及相关的大型语言模型是如何一步步进化成目前的强大形态。
首先,初代GPT-3展示的三个重要能力如下:
语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今天人类与语言模型最普遍的交互方式。上下文学习 (in-context learning):遵循给定任务的几个示例,然后为新的测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的论文几乎没有谈到「语言建模」 (language modeling) —— 作者将他们全部的写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)。那么这些能力从何而来呢?
基本上,以上三种能力都来自于大规模预训练:
在有3000亿单词的语料上预训练拥有1750亿参数的模型( 训练语料的60%来自于2016 - 2019 的C4 22%来自于WebText2 16%来自于Books 3%来自于Wikipedia)。
其中语言生成的能力来自于语言建模的训练目标(language modeling)。
世界知识来自3000亿单词的训练语料库(不然还能是哪儿呢),而模型的1750亿参数就是为了存储它们。
 从GPT-3到ChatGPT
从GPT-3到ChatGPT为了展示是GPT 3如何发展到ChatGPT的,我们先来看看 GPT-3.5 的进化树:
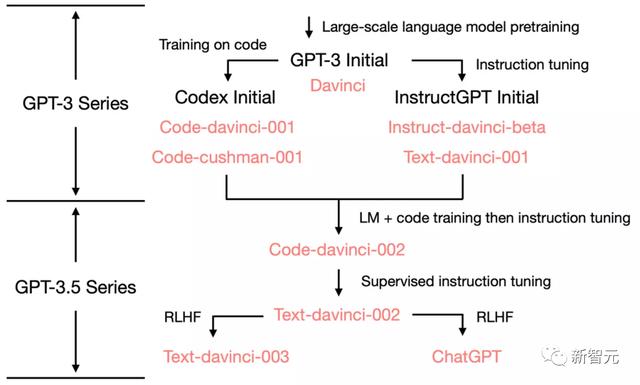
2020年7月,OpenAI发布了模型索引为davinci的初代GPT-3论文,从此之后开启了不断进化迭代之路。
21年7月,Codex 的论文发布,其中初始codex是根据120亿参数的GPT-3变体微调的,后来这个模型演变成 OpenAI API中的code-cushman-001。22年3月,OpenAI发布指令微调 (instruction tuning) 论文,其监督微调 (supervised instruction tuning) 的部分对应了davinci-instruct-beta和text-davinci-001。22年4月至7月,OpenAI开始对code-davinci-002模型进行Beta测试。尽管Codex听着像是一个只管代码的模型,但code-davinci-002可能是最强大的针对自然语言的GPT-3.5变体(优于 text-davinci-002和-003)。

接下来,GPT3处理这句话中「robotics」这个单词主要分为三个步骤(如下图):
将单词转换为表示单词的向量计算预测将结果向量转换为单词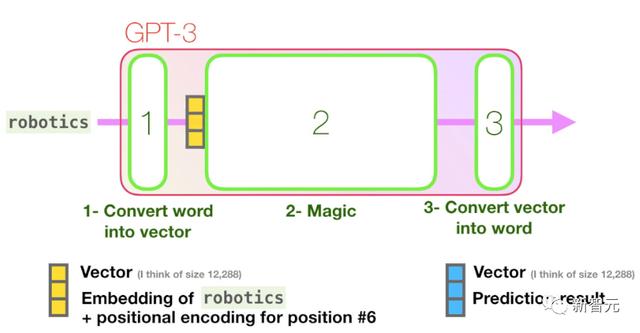
而GPT-3的计算主要发生在其96个Transformer解码层中:
这96层就是GPT3的「深度」,每一层Transformer都有18亿参数参与计算。
并且因为GPT3在大量数据上预训练,因此泛化性能很强,所以只需在下游任务微调,就可达到很高的性能。

GPT-3微调演示图
机器学习的本质决定了ChatGPT等语言模型惊人的学习和产出能力。
但是,正如马库斯所说,ChatGPT等聊天机器人没有理解现实世界与心理活动的能力。
即使ChatGPT能码一万篇黄文,不会读心的机器人,要靠什么把握人类呢?
参考资料:
https://www.reddit.com/r/AO3/comments/z9apih/sudowrites_scraping_and_mining_ao3_for_its/
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
相关文章









关于作者

猜你喜欢























