既能问答、翻译、写文章,也能写代码、算公式、画图标......OpenAI 2020 年 5 月推出的 GPT-3,因其神奇的通用性而走红 AI 领域。
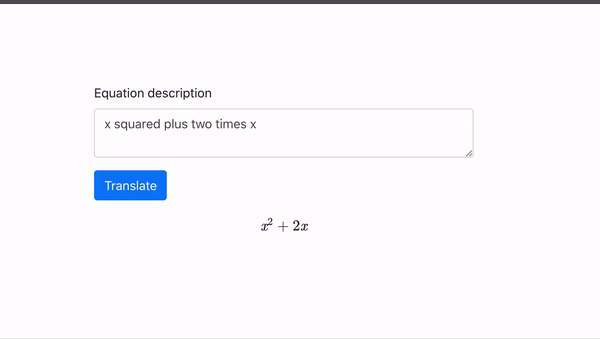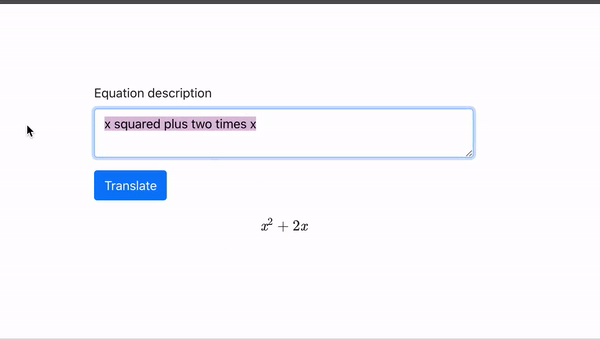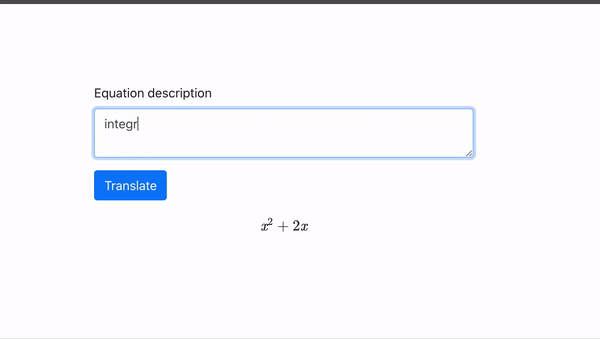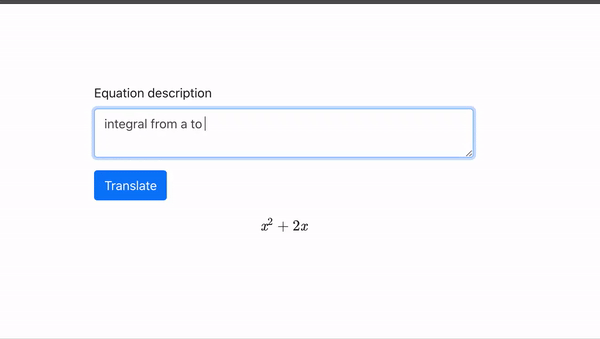
随着数据量和模型规模的增大,GPT 逐渐舍弃了用少数标注语料精调这一步,完全基于预训练得出的参数,去做下游任务,精确度依然有一定保证。
GPT 所需算力也越来越夸张,初代 GPT 在 8 个 GPU 上训练一个月就行,而 GPT-2 需要在 256 个 Google Cloud TPU v3 上训练(256 美元每小时),训练时长未知。到 GPT-3,预估训练一个模型的费用超过 460 万美元。
相应地,参与到 GPT 论文的作者从初代的 4 位,增加到第三代的 31 位。并且,31 位作者分工明确,有人负责训练模型,有人负责收集和过滤数据,有人负责实施具体的自然语言任务,有人负责开发更快的 GPU 内核。
借鉴 GPT-3 的迭代经验,李志飞认为开展中文 GPT-3 模型训练比较合理的路径是:“从中小规模的模型入手,开展研究及实验,达到一定效果后再推广到大模型上进行验证”。
至于人力方面的配置,他表示 GPT 是一个非常综合的大系统工程,涉及到学术、工程、商业等团队之间的大规模协同。一般需要搭建几十人的团队,其中包括科学家、工程师、项目经理等角色。
虽然可以借鉴英文 GPT-3 技术迭代的相关经验,但是在创建中文版 GPT-3 的过程中,也需要解决很多独特的问题,如中文训练数据、算力等。
“一方面,我们需要将更多的时间精力,投入在高质量、多样性的训练文本的获取上。”李志飞说,“另一方面,计算的效率问题,也是目前大规模深度学习模型训练所面临的共同挑战。”
从总体规模、数据质量及多样性上看,目前能够从互联网上获取到的高质量中文数据,相比英文数据要少一些,这可能会影响到中文模型的训练效果。不过,从已有的研究分析结果来看,数据并非越多越好。
“我们可以结合数据优化、数据生成等方式来提高训练语料的有效性。初步来看,具体训练语料,主要包括百科问答、新闻资讯、博客电子书类数据及其它泛爬数据,经过数据处理后其规模在 500GB 左右。”李志飞说。
GPT-3 模型参数到达 1750 亿,其背后训练资源的开销非常庞大,预估训练一个模型的费用超过 460 万美元。不过,随着国内外各项研究的推进,预训练模型的训练效率将会不断提升。
“我们可以借鉴其他预训练语言模型的优化经验,在训练语料、网络结构、模型压缩等方面多做工作,预计将模型的单次训练成本降低一个数量级。”李志飞说。
看上去,构建中文 GPT-3 是一件很费劲的事情,但这项工作带来的回报也非常可观。李志飞对品玩表示,GPT-3 展现出的通用能力,可以将其视为下一代搜索引擎和 AI 助理,所以这项技术本身的商业应用场景可以很广阔。
其次,构建 GPT 模型的过程中,将涉及到超算中心和AI算法平台的建设,这些算力和算法平台可以为企业、科研机构、政府提供底层服务,通过开放平台为产业赋能,如智能车载、智慧城市、科技金融等领域。
另外,虽然 GPT 本质是一个关于语言的时序模型,但语言之外的其它时序问题,如经济、股票、交通等行为预测,也有可能成为潜在应用场景。
GPT-4 可能如何演化?GPT-3 目前的表现虽然令人震惊,但它本身还存在着很多问题,比如它并不能真正理解文本的含义,只是对词语进行排列组合。而且,研究员也并未完全了解它的工作机制。李志飞预测,下一个版本 GPT-4 将会在模型规模、小样本学习、多模态、学习反馈机制和与任务执行结合方面进行改进。
毫无疑问,GPT-4 模型会更加暴力。李志飞说:“下一代 GPT 模型必然在数据规模、模型参数、算力等方面都会有很大提升。另外,下一代的 GPT 模型可能不局限于英文,将能处理更多跨语言层面的任务。”
目前的 GPT-3 模型还严重依赖小样本学习机制。虽然 GPT-3 不需要精调,但是在完成具体的 NLP 任务时,还是会把少量和任务相关的实例给模型。在零样本和单样本的任务上,GPT-3 退化比较明显,事实上后面两个任务才是更普遍遇到的问题。
“下一代 GPT 模型需要加强在理论上的泛化能力,以便更好地处理零样本和单样本的任务。”李志飞表示。
下一代的 GPT 模型极有可能是一个多模态的模型。OpenAI 认为,纯文本的自回归预训练模型达到当下的规模,已经快接近极限了,需要往多模态模型方向发展,把文本、语音、图像这些内容结合起来进行学习。李志飞认为,多模态模型,一方面可以引入语言之外的更多维度的信息,另外一方面可以促使模型学习完成更通用化的表示,以此加强模型的泛化能力。

另外一个重要的进化,是引入学习反馈机制。目前GPT模型只是能够在完全无监督的条件下,读取海量互联网文本数据进行学习,但是人类的学习过程是跟物理世界有交互的,只有这样才能建立更多物理世界的“常识”,比如说杯子应该在桌子上面而不是下面。如果要到达更加通用的状态,除了多模态外,还要在学习过程中引入物理世界的反馈机制。
“当然,这个反馈也是通过数据来实现的,而不是让GPT真正像人一样去探索物理世界。”李志飞说道,“另外,鉴于 GPT 希望实现完全无监督学习的初衷,这个反馈更多是隐式的和延迟的,而不是显式的和及时的。为了做到这些,需要引入强化学习(re-inforcement learning)之类的机制。”
李志飞还认为,GPT-4 可能引入任务执行能力。现在的 GPT 主要是一个预测和生成的引擎,而不是一个任务的执行器。
比如,你跟GPT说“帮我订一下明天下午三点左右北京去上海的经济舱的机票”,目前GPT也许能理解这句话的意思,但还没有能力自动调取订票网站的 API(应用程序接口)去执行任务。如果不具备这种执行能力,GPT的通用性就很有限,因为每一个任务都需要额外增加代码用以执行理解后的任务。所以,GPT 必须学习怎么直接执行任务。
总体而言,李志飞对 GPT 的未来发展非常乐观:“未来互联网上的很多内容或知识,都会是由类 GPT 模型产生或加工过的。所以某种程度上,GPT的发展代表着语言主权的演进,且它将有潜力成为一种生态系统。”
扩展阅读:GPT-3 走红背后,AI 正变成普通人玩不起的游戏
API 开放之后,我们才真正领略 GPT-3 的强大……
相关文章









关于作者

猜你喜欢























