Pine 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4再度进化!
加上一个简单方法,就能让GPT-4这类大语言模型学会自我反思,性能直接提升30%。

不过,同人类思考一样,LLM在反思的过程中同样也有局限性,这在函数中的Ω和ε中就能体现。
Ω表示重复连续动作的次数,一般会将这个数值设置为3,这表示反思过程中若重复一个步骤三次,会直接跳到下一个步骤。
而ε则表示在反思的过程中允许执行的最大操作数量。
既然有监督,那修正也必须执行,修正过程的函数是这样子的:

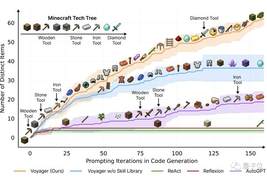
在HotpotQA的134个问答对测试中,可以看出在Reflexion的加持下,LLM经过多轮反思后,准确率一度达到97%。

在另外一篇博客中,团队成员也晒出了他们这种方法在GPT-4上的效果,测试范围是编写代码。
结果也显而易见,用了Reflexion,GPT-4的编程能力直接提升了21%。

关于GPT-4已经会“思考”了,你怎(huang)么(le)看(ma)?
论文地址:https://arxiv.org/abs/2303.11366参考链接:[1] https://nanothoughts.substack.com/p/reflecting-on-reflexion[2] https://www.reddit.com/r/MachineLearning/comments/1215dbl/r_reflexion_an_autonomous_agent_with_dynamic/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢























