Big news!它来了,上个月全网刷屏的ChatGPT又来了。
这次,它又完成了超强进化,带着一身炫酷的技能点,GPT-4闪亮登场,再次惊艳所有人。

(这里插播一条消息,Google在刚刚过去的π day(3月14日),推出了搭载各种AI服务、几乎覆盖整个办公场景的新版Workspace,也许是想弯道超车,结果又一次毫无波澜……GPT-4让所有人眼前一亮,估计只有Google两眼一黑了。)

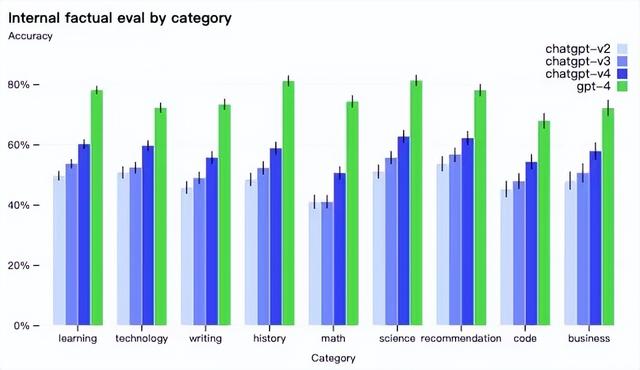
在其他技能测试中,GPT-4的表现也明显好于旧版本。

某种程度上,你的大脑如何体验这个简单的动作是来自不同感官的组合,创造了一个更复杂的“吃苹果”真正含义的表述。

有了多模态,我们可以教机器,一张苹果的图片,一个人咬苹果时发出的声音,以及关于苹果是什么的一般文字描述,代表了我们都描述为苹果的同一事物概念。
这样一来,盲人也能够「看到」图片了(丹麦一家为盲人或视力低下人群提供帮助的企业Be My Eyes已经开始开发基于GPT-4的虚拟志愿者™(Virtual Volunteer™),该应用拥有与人类志愿者水平相当的上下文和理解能力)。
多模态使得 GPT-4能做的事情更有想象空间了。
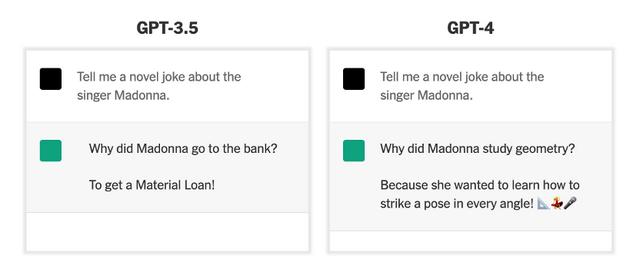
看图说话,玩梗解梗,AI讲的冷笑话没那么冷了。
“开局一张图,内容全靠编”这句话现在放到GPT-4上可能要有不同含义了。不过,怎么“编”得看喂给它的是什么,以及用户提什么需求了。
一来,尽管GPT-4的性能有了大幅提升,它胡言乱语的毛病得到了改善,但并未完全根除。所以,满嘴跑火车“瞎编”的情况依然可能存在,它不仅编得快,还能编得像模像样。
人类玩的梗,GPT-4也能整明白了,解梗讲冷笑话也是信手拈来(幽默感略有提升,但不多)。

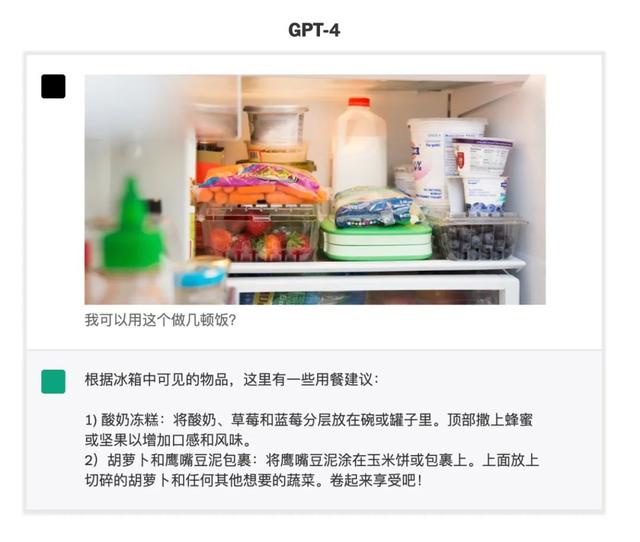
二来,GPT-4能够处理图像和文本的组合输入,并根据图中的画面或文本完成用户指定的视觉或语言任务,然后输出文本(自然语言、代码等)。
如根据图像做推理、求解物理题、从论文截图生成总结摘要等。这里的“编”可以是“编译”或“编写”,是有逻辑的看图说话。


一个不小心,OCR技术又被GPT-4降维打击了。

想象一下,给GPT-4一张粗略的手绘草图,就能得到一个正常运行的网站。是的,它做到了。
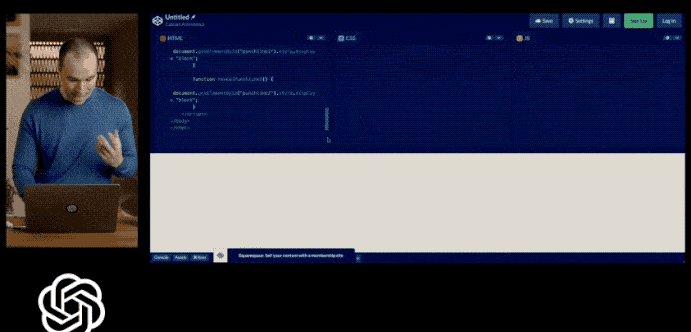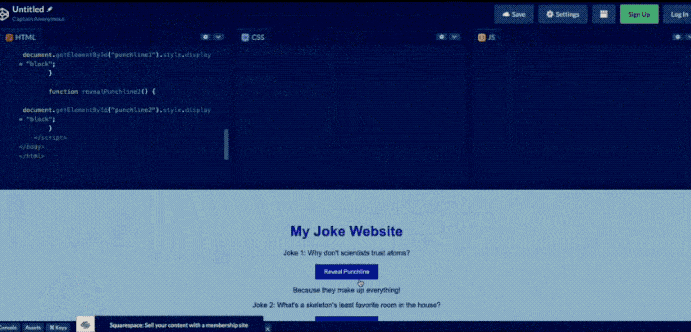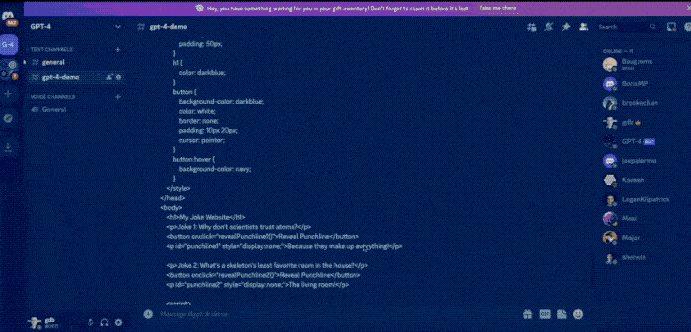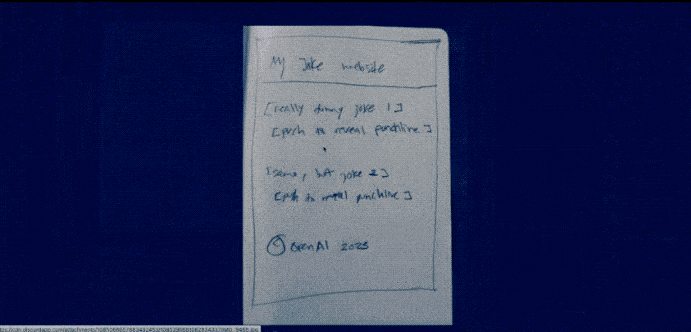
GPT-4化身赛博神笔马良,草图秒变网站,看到这里,前端工程师该慌了吗?
马斯克表示慌了(还不忘顺便给自己的Neuralink打个广告)。

在一些用户的编程实测中,也提到GPT-4的编程水平明显提高了,它一开始就能写出完整的应用页面,还能随时debug,改善代码的可读性和优化代码。
有网友戏称,在用GPT-4做开发的过程中,人类变成了「机」-「机」接口。人需要做的工作就是告诉机器自己需要什么,然后从一台机器复制代码到另一个机器,代码报错也能让AI改,甚至应该直接把这个修复过程自动化。
不管你有没有用过ChatGPT,AI已经变得无处不在,就像空气一样,你可能感觉不到它的存在,但它无时无刻不在影响着你的生活。
看完这篇文章,至少,现在不会看不懂,但大受震撼了。

看懂之后可以转发让更多人也感受一下震撼。
相关文章









关于作者

猜你喜欢























