量子位 | 公众号 QbitAI
小米大模型第二代来了!
相比第一代,训练数据规模更大、品质更高,训练策略与微调机制上也进行了深入打磨。
不仅窗口长度增长到了原来的50倍,在10大能力维度上表现相比于第一代平均提升超过45%。
而且家族成员丰富,有从0.3B到30B多个参数规模,分别适配云边端各侧设备。
此外,第二代大语言模型在端侧部署上还支持3种推理加速方案,包括大小模型投机、BiTA、Medusa,相比于业界标准高通方案,量化损失降低78%。
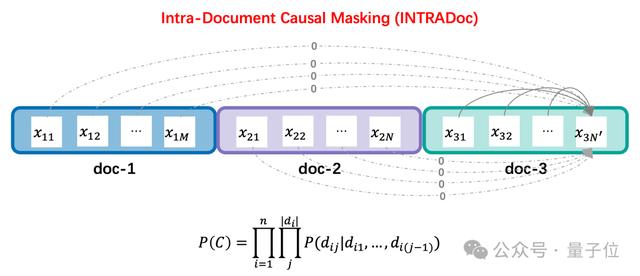
 INTRADoc
INTRADoc论文地址:https://arxiv.org/abs/2402.13991
INTRADoc是一种新的注意力机制。
它通过屏蔽无关文档,让每个token的概率仅取决于同一文档中的上文信息,进而消除了来自之前无关文档的潜在干扰信息。
结果,INTRADoc显著地提高了模型上下文学习、知识记忆、上下文利用能力。
 Mixture of Diverse Size Experts
Mixture of Diverse Size Experts论文地址:https://arxiv.org/abs/2409.12210
这是一种新的MoE结构,简称为MoDSE。
它在每一层中设计大小不同的专家结构,并同时引入了一种专家对分配策略,以在多个GPU之间均匀分配工作负载。
在多个基准测试中,MoDSE通过自适应地将参数预算分配给专家,在保持总参数量和专家个数相同的情况下,表现优于传统MoE结构。
 性能平均提升45%
性能平均提升45%小米第二代模型MiLM2系列融合多项前沿技术模型效果全面超越了第一代。
小米大模型团队采用自主构建的通用能力评测集Mi-LLMBM2.0,对最新一代的MiLM2模型进行了全方位评估。
该评测集涵盖了广泛的应用场景,包括生成、脑暴、对话、问答、改写、摘要、分类、提取、代码处理以及安全回复等10个大类,共计170个细分测试项。
以MiLM2-1.3B模型和MiLM2-6B模型为例,对比去年发布的一代模型,在十大能力上的效果均有大幅提升,平均提升幅度超过45%。
 4B 30B,云端协同运行
4B 30B,云端协同运行特别地,对于端侧,小米第二代大模型的部署技术也有了新的突破,新的4B模型将在端侧发挥更重要的作用。
小米大模型团队创新性地提出了“TransAct大模型结构化剪枝方法”,仅用8%的训练计算量即从6B模型剪枝了4B模型,训练效率大大提升;
同时小米大模型团队自研了“基于权重转移的端侧量化方法”和“基于Outliers分离的端侧量化方法”,大幅降低了端侧量化的精度损失,对比业界标准高通方案,量化损失下降78%。
MiLM2-4B模型总共40层,实际总参数量为3.5B,目前已经实现在端侧部署落地。

同时,在云端运行的MiLM2-30B模型是小米二代大模型系列中参数量级最大的模型。
在云端环境中,大模型面临着多样化和高难度的挑战,需要更高效地遵从并执行用户的复杂指令,深入分析多维度任务,并在长上下文中精准定位信息。
针对这些重点目标,大模型团队选择了一系列开源的评测集,对MiLM2-30B模型的专项能力进行评估。
结果表明,MiLM2-30B模型在指令遵循、常识推理和阅读理解能力方面均有超越主流竞品的出色表现,具体的评测集和评测结果如下:
 △指令遵循及常规能力测试结果
△指令遵循及常规能力测试结果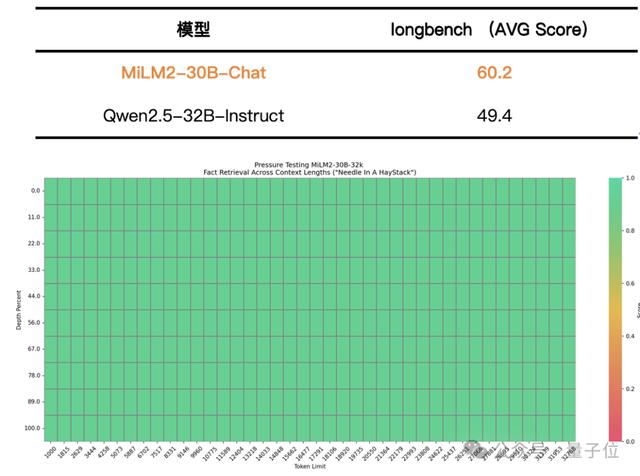 △长文本能力测试结果
△长文本能力测试结果— 完—
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

科技前沿进展日日相见 ~
相关文章








关于作者

猜你喜欢























