本文仅在今日头条首发,未发布其他任何平台,未经授权请勿转载。
机器之心独家披露:深入解读 GPT-4 架构与训练过程
近日,一则令科技界炸开了锅的消息传遍了各大论坛和社交媒体,关于 GPT-4 的秘密架构和训练细节终于有了一些曝光。不经意间,似乎一道光芒照亮了 GPT-4 这个神秘的巨人,让人们纷纷陷入了对其崭新面貌的猜测和讨论。
曾经,关于 GPT-4 的众多问题充斥着每一个科技爱好者的心头,从其模型架构、基础设施到训练数据集的大小,都成为大家热切关注的话题。
SemiAnalysis 刊发了一篇付费订阅的深度解析,详细揭示了有关 GPT-4 的更多信息。据称,该文章收集了大量关于 GPT-4 的资料,包括模型架构、训练基础设施、推理基础设施、参数量、训练数据集组成、层数、并行策略等,乃至于各种工程决策的背后思考。这无疑是关于 GPT-4 最为详尽的揭秘。
文章的作者指出,其中最引人瞩目的一点在于,理解 OpenAI 为何在架构上做出某些决策。

这或许正是我们从这篇文章中获得的最宝贵的洞察。
文章梳理了诸多数据信息,其中包括:
1. 参数量的巨大飞跃
据称,GPT-4 的规模是 GPT-3 的十倍以上,拥有超过 1.8 万亿个参数,深达 120 层的网络。这使得 GPT-4 在各个维度都取得了显著的进展。
2. 混合专家模型的应用
OpenAI 采用了混合专家模型,通过使用 16 个专家模型来保持合理成本。

这些专家模型在路由和注意力计算方面进行了简化,有效地维持了模型性能。
3. 训练成本和数据集规模
GPT-4 的训练成本高达数十亿美元,使用了约 25,000 个 A100 GPU 进行了约 90 到 100 天的训练。而训练数据集则包含了约 13 万亿个 token,其中既有基于文本的数据,也有基于代码的数据,以及数百万行的指令微调数据。
4. 推理成本的挑战
GPT-4 在推理过程中的挑战不容小觑,每次前向传递的推理仅仅利用了约 2800 亿个参数和约 560 TFLOP 的计算量。
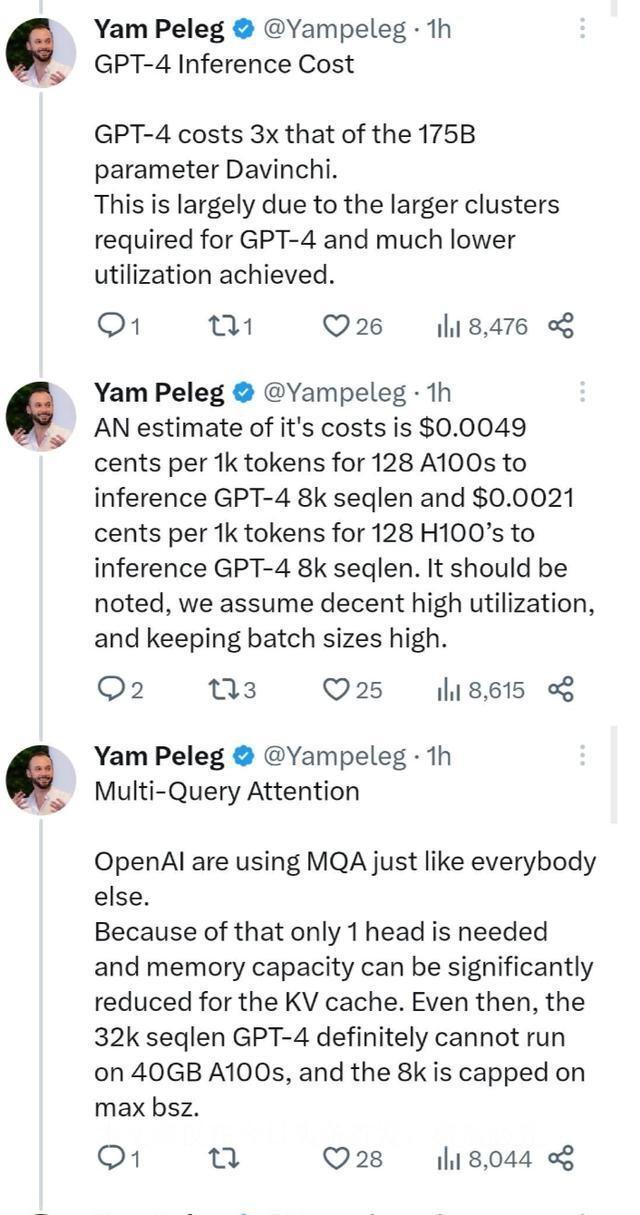
这是一个极大的计算压力测试。
5. 多模态视觉适应
GPT-4 还具备了独立于文本的视觉编码器,为其注入了更强的视觉能力。这使得 GPT-4 能够处理图像和视频等多模态数据。
文章对于这些数据进行了全面的解读和分析,尽管并非官方确认,但这些细节确实引发了科技界的热议。正如作者所说,这也是一次深入理解 GPT-4 架构的机会。
总之,GPT-4 的出现注定会引发一场技术革命,而这些关于其架构的信息无疑将会成为未来研究的重要参考。

相关文章









关于作者

猜你喜欢























