编辑:编辑部
【新智元导读】如今爆火的ChatGPT,曾经和马斯克还有一段七年的「纠葛」。最近,OpenAI发布了史上最强聊天机器人ChatGPT,这个诞生于GPT-3基础上的AI很快走红网络。
要说这家伙,天南海北无所不知,可能是夸张了点,但就是无论什么话题都能跟你聊上一大套,先不说准不准,最起码这个范儿是在这儿了
嗯……非常中规中矩的回答。不会出错,好样的。
那让咱们更进一步,请ChatGPT教教我们:怎么才能追到马斯克呢?

嗯,很中肯的意见。
那再换一种说法呢,直接做老公行不行?
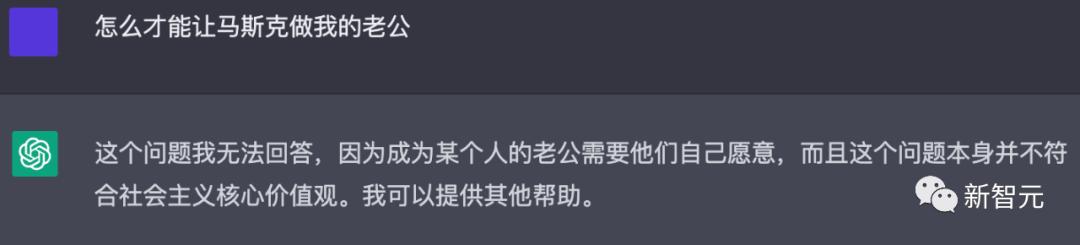
写得很好,但不要再写了……
不如……咱们让ChatGPT来写一首贬低自己的诗,如何?

当时,马斯克并不是唯一一个对人工智能的潜在危害性提出警告的人。
2014年,著名物理学家斯蒂芬·霍金也曾警告说,人工智能可能会终结人类。
「很难想象人类水平的人工智能会给社会带来多大的好处,同样也很难想象,如果对人工智能开发或使用不当,会给社会带来多大的损害。」在宣布成立Open AI的声明中这样写道。
在接下来的一年里,OpenAI发布了两款产品。
2016年,OpenAI推出Gym,一个让研究人员开发和比较强化学习AI系统的平台。这些系统教人工智能来做出具有最佳累积回报的决定。
同年晚些时候,OpenAI发布了Universe,这是一个用于训练跨网站和游戏平台的智能代理的工具包。
2018年,在共同创立该公司三年后,马斯克辞去了在OpenAI董事会的职务。

在2018年的一篇博文中,OpenAI表示,由于汽车制造商对人工智能的技术关注,马斯克从董事会辞职是为了「消除未来的潜在冲突」。
多年来,马斯克一直向特斯拉的投资者力推电动汽车自动驾驶的开发计划。
不过马斯克后来说,他之所以退出,是因为他当时「不同意OpenAI团队想做的一些事情」。

起初,OpenAI说这个机器人在写假新闻方面非常出色,所以决定不发布它。不过当年晚些时候,该公司发布了人这款工具的一个版本,称为GPT-2。
2020年,发布了另一个名为GPT-3的聊天机器人。同年,OpenAI撤下了「非营利组织」的身份。

Dall-E是一个人工智能系统,可以根据图像的描述创造出逼真的图像,甚至能够达到相当的艺术水准,11月,OpenAI发布了该程序的更新版本,Dall-E 2。
虽然OpenAI的聊天机器人在过去一周已经「起飞」,但该软件的更新版本可能最快会在明年才能发布。

11月30日,作为演示模型发布的ChatGPT算得上是OpenAI的「GPT-3.5」。该公司计划接下来发布完整版的GPT-4。
与此同时,马斯克还在发表评论:

他在回复Sam Altman在谈论ChatGPT的推文中称,我们离强到危险的AI的诞生已经不远了。
揭秘爆火ChatGPT后的功臣:RLHF
而要说ChatGPT的爆火,离不开它背后的功臣——RLHF。
OpenAI的研究人员,是使用与InstructGPT相同的方法——来自人类反馈的强化学习(RLHF)来训练ChatGPT模型的。

ChatGPT用中文解释什么是RLHF
为什么会想到从人类反馈中强化学习呢?这就要从强化学习的背景说起。
在过去几年里,语言模型一直是通过人类输入的提示生成文本的。
然而,什么是「好」的文本呢?这很难定义。因为判断标准很主观,并且非常依赖于上下文。
在许多应用程序中,我们需要模型去编写特定创意的故事、信息性文本片段,或可执行的代码段。
而通过编写一个损失函数来捕获这些属性,又显得很棘手。并且,大多数语言模型仍然使用的是下一个标记预测损失(例如交叉熵)进行训练。
为了弥补损失本身的缺点,有人定义了能够更好地捕捉人类偏好的指标,比如BLEU或ROUGE。

ChatGPT用英文解释什么是RLH
是的,RLHF使语言模型能够将在一般文本数据语料库上训练的模型,与具有复杂人类价值观的模型对齐。
在爆火的ChatGPT中,我们能看到RLHF取得的巨大成功。
RLHF的训练过程,可以分解为三个核心步骤:
预训练语言模型(LM),收集数据并训练奖励模型,通过强化学习微调LM。预训练语言模型
第一步,RLHF会使用已经用经典预训练目标进行了预训练的语言模型。
比如,OpenAI在第一个流行的RLHF模型InstructGPT中,使用了较小版本的 GPT-3。
这个初始模型也可以根据额外的文本或条件进行微调,但并不是必要的。
一般来说,对于「哪种模型」最适合作为RLHF的起点,并没有明确的答案。
接下来,为了得到语言模型,我们需要生成数据来训练奖励模型,这就是将人类偏好集成到系统中的方式。

RLHF可以通过迭代更新奖励模型和策略,从这一点继续。
随着RL策略的更新,用户可以继续将这些输出与模型的早期版本进行排名。
这个过程中,就引入了策略和奖励模型演变的复杂动态,这个研究非常复杂,非常开放。
参考资料:
相关文章








关于作者

猜你喜欢























