♀️ 编者按:本文作者是蚂蚁集团前端工程师茂松,从非算法同学的视角窥探大模型的理论和实践,欢迎查阅~
前言当前 LLM(Large Language Model) 大语言模型越来越火,在业务和生活中已经逐渐变得人尽皆知,作为一名技术同学,可以不精通其中的细节,但了解其大致的奥义是应该必备的技术素养,最起码应该清楚大模型是怎么运作的,在业务中我们可以与其建立什么链接,这也是我写这篇文章的主要原因。
本文借鉴了多方文章,加入了自己的理解,由于大部分相关文章都比较有技术壁垒,很多同事包括我读起来都比较晦涩,因此我尽可能将其转化为比较易懂的语言。
我本人也不是专业的算法同学,因此只能用比较浅薄的视角窥探一部分大模型的理论和实践,如果有描述不清或有误之处还请批评指出。
ChatGPT 的概念GPT 对应的是三个单词:Generative,Pre-Training,Transformer。
Generative:生成式,比较好理解,通过学习历史数据,来生成全新的数据。ChatGPT 回答我们提出的问题时,是逐字(也有可能是三四个字符一起)生成的,如果你使用 ChatGPT 时仔细观察它回答你的方式,你可能会对「逐字」这个概念有更深的感触。这里逐字生成的时候每一个字(或词,在英文中也可能是词根)都可以被称作一个 token。
Pre-TrAIning:预训练,顾名思义就是预先训练的意思。举个简单的例子,如果我们想让一个对英语一窍不通的同学去翻译并总结一篇英语技术文章,那么对这个同学来说就需要先学会英文 26 个字母,进而学会单词语法等,再去了解这篇文章相关的技术,最后才能去完成我们指派的任务。但是如果让一个对英语已经很精通的同学来做这个任务就相对简单的多,他只需要去大致了解一下这篇文章所涉及到的技术,便能很好的总结出来。
这就是预训练,先把一些通用能力提前训练出来。人工智能本身就是一个不断训练参数的过程,如果我们可以提前把通用能力相关的参数提前训练好,那么在一些特殊的场景,发现通用能力不能完全适配时,只做简单的参数微调即可,这样做大幅减少了每个独立训练预测任务的计算成本。
Transformer:这是 ChatGPT 的灵魂,它是一个神经网络架构。后文再进行详细的说明。
以上就是 ChatGPT 的基本概念,结合起来就是一个采用了预训练的生成式神经网络模型,它能够对人类的对话进行模拟。
ChatGPT 的核心任务ChatGPT 的强大推理能力确实令人印象深刻,它的核心任务就是能够生成一个符合人类书写习惯的下一个合理的内容。具体的实现逻辑就是根据大量的网页、数字化书籍等人类撰写内容的统计规律,推测接下来可能出现的内容。
逐字(词)推测:
体验 ChatGPT 时如果细心观察会发现 ChatGPT 回答问题时是逐字或逐词来进行回答的,这也就是 ChatGPT 的本质:按照上下文来对下一个要出现的字或词进行推测。比如要想让 ChatGPT 预测“湖人总冠军”这五个字,它会经历如下步骤:
输入“湖”这个字,输出可能是“泊”,“人”,“水”这三个字,其中结合上下文概率最高的是“人”字输入“湖人”这两个字,输出可能是“总”,“真”,“牛”这三个字,其中结合上下文概率最高的是“总”字输入“湖人总”这三个字,输出可能是“冠”,“赢”,“经”这三个字,其中结合上下文概率最高的是“冠”字输入“湖人总冠”这四个字,输出可能是“名”,“王”,“军”这三个字,其中结合上下文概率最高的是“军”字由于 ChatGPT 学习了大量人类现有的各种知识,所以它可以进行各种各样的预测,这就是 transformer 模型最终做的事情,但实际原理要复杂得多。
人工智能的基础知识在介绍 ChatGPT 的原理之前,先学习一下人工智能的一些基础知识:
机器学习:机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并将这些规律应用到未观测数据样本上的方法。主要研究内容是学习算法。基本流程是基于数据产生模型,利用模型预测输出。目标是让模型有较好泛化能力。
举一个经典的例子,我们挑西瓜的时候是如何判断一个西瓜是否成熟的呢?每个人一开始都是不会挑选的,但是随着我们耳濡目染,看了很多挑西瓜能手是怎么做的,发现可以通过西瓜的颜色,大小,产地,纹路,敲击声等等因素来判断,那么这个就是一个学习的过程。
参数 / 权重:所有的人工智能都有一个模型,这个模型可以简单的被理解为我们数学里的一个公式,比如一个线性公式:,参数(权重)就是和,这个线性公式中只有这两个参数,那么带入到 ChatGPT 中,3.0 版本已经有了 1750 亿个参数,4.0 的参数规模未公布,但可以猜测只会比 3.0 版本更多而不会更少。因此在这样巨大的参数规模中进行调参训练是一个非常耗费机器(GPU)的工作,所以需要大量的资金和机房支持。
监督学习 / 无监督学习:监督学习:简单的理解就是给算法模型一批已经标记好的数据,比如上面的例子,我们提前给模型提供 1000 个西瓜,并且标记好这 1000 个西瓜是否已经成熟,然后由模型自己不断去学习调整,计算出一组最拟合这些数据的函数参数,这样我们在拿到一个全新的西瓜时,就可以根据这组参数来进行比较准确的预测。
无监督学习:就是我们扔给模型 1000 个西瓜,由算法自己去学习他们的特征,然后把相似的类逐渐聚合在一起,在理想情况下,我们希望聚合出 2 个类(成熟和不成熟)
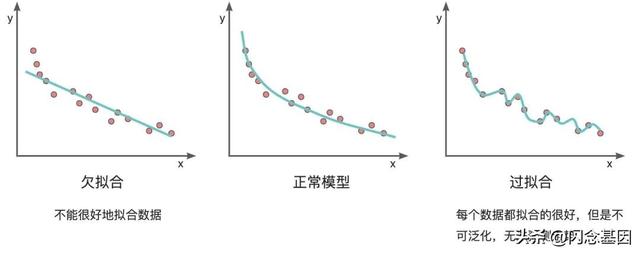
过拟合 / 欠拟合:在我们的模型进行训练的时候,最终的目的就是训练出一组参数来最大限度的能够拟合我们训练数据的特征,但是训练的过程总不会是一马平川的,总会出现各种问题,比较经典的就是过拟合和欠拟合。
直接举例说明更直接一点,如下图,我们希望模型能尽量好的来匹配我们的训练数据,理想状态下模型的表现应当和中间的图一致,但实际训练中可能就会出现左右两种情况。左边的欠拟合并并没有很好的拟合数据,预测一个新数据的时候准确率会比较低,而右侧看起来非常好,把所有的数据都成功拟合了进去,但是模型不具有泛化性,也没有办法对新的数据进行准确预测。
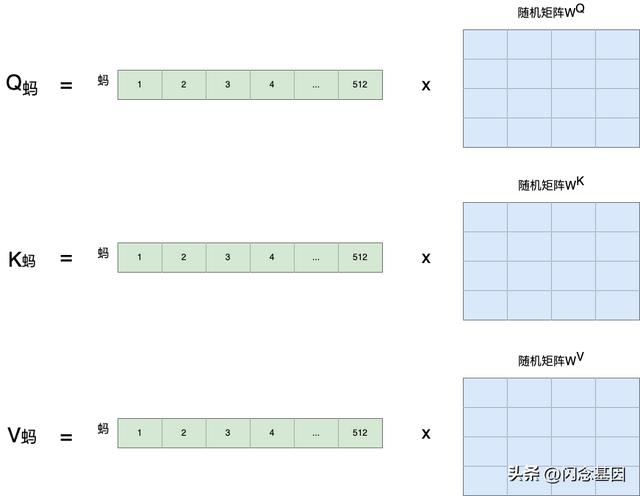
由于样本每个句子长短不同,所以每个句子都会是一个 512 x 512 的矩阵,如果长度不够就用 0 来代替。这样在训练时,无论多长的句子,都可以用一个同样规模的矩阵来表示。当然 512 是超参,可以在训练前调整大小。
接着,用每个字的初始向量分别乘以三个随机初始的矩阵分别得到三个量Qx,Kx,Vx,这样就得到了三个量:Qx,Kx,Vx,比如用“蚂”这个字举例:
借用阿里巴巴集团暮诗同学标注后的图,看下各部分的职责:
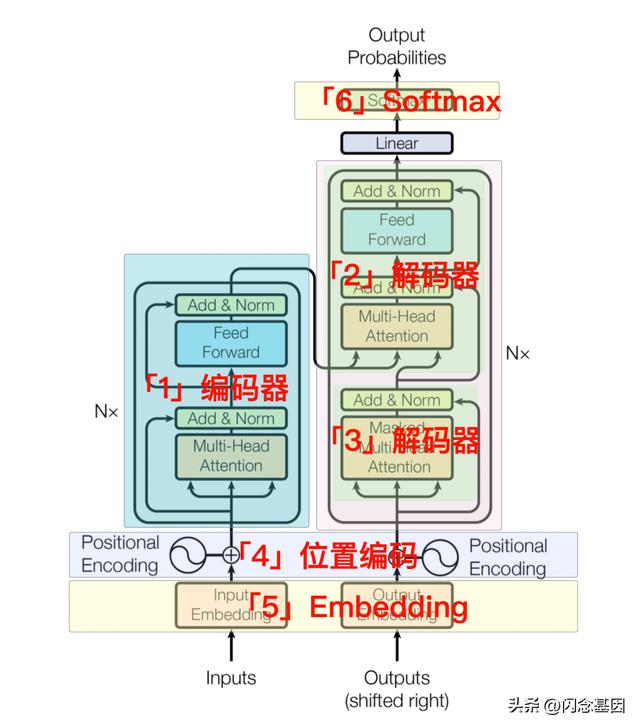
每一个部分我们基本上已经大致都讲述过了,现在我们对 ChatGPT 的实现原理有了简单的认识。
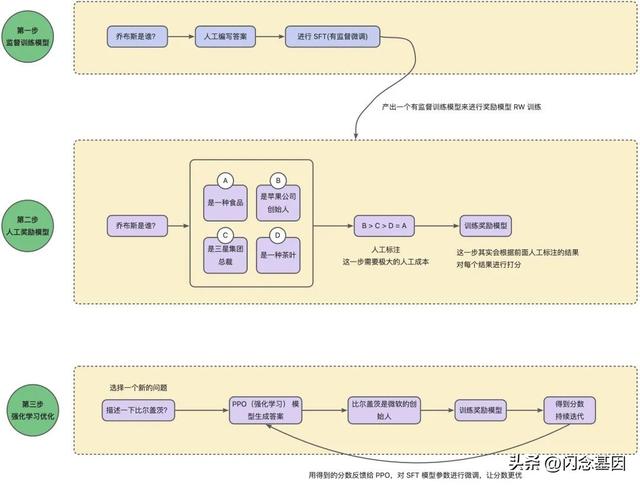
训练数据从哪来以及如何训练?ChatGPT 的训练数据来源包括维基百科、书籍、期刊、Reddit 链接、Common Crawl 和其他数据集,共计约 45TB 的数据,其中包含了近 1 万亿个单词的文本内容,相当于 1351 万本牛津词典或 1125 万本书。这些数据涵盖了截至 2021 年的海量知识,这也是 ChatGPT 能够与时俱进地解读出很多现实世界新型事物的含义的原因之一。
有了这些数据之后,就可以训练我们的模型,这里就要用到 RLHF 来进行反馈和训练了。这类学习方法通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
 智能客服
智能客服大家体验过 ChatGPT 之后应该都会联想到客服相关的产品,各业务线的一个痛点就是都需要值班和答疑,以 Tracert 业务为例,每日答疑量是巨大的,巅峰时甚至占每日精力的 80%,这样对相关业务同学的心力消耗也是不可弥补的。
如果建设了智能客服平台,结合研发小蜜,将各业务的平台场景投喂进去之后,将会对所有业务线进行一次提效。目前在医疗,金融等领域,ChatGPT 的问答已经被训练得比较成熟了:
医疗:https://github.com/xionghonglin/DoctorGLM
金融:https://github.com/jerry1993-tech/Cornucopia-LLaMA-Fin-Chinese
法律:https://github.com/pengxiao-song/LaWGPT
code snippet 大模型大家一定体验过大模型的各类代码生成,其结果虽然不是百分百完全可用的,但是在很多场景下,ChatGPT 生成的代码基本上稍作修改就可以使用。目前有很多编辑器都做出了这方面的探索,比如 Cursor(https://github.com/getcursor/cursor)
好不好用只用试用了才知道,在我们不熟悉的领域,这类代码生成能弥补我们的能力短板,比如让一个不熟悉 SQL 的同学去捞数据,确实提升了生产力,但是一旦进入熟悉领域,比如让其生成一段业务代码,那会发现其实在组织提供 prompt 的过程中的耗时,不一定比直接写代码少。
除了代码生成这个领域,还可以涉足代码检测。比如代码提交后,CR 时加入大模型智能 CR,可以有效的识别到语法不规范等简单问题,当前蚂蚁的 code 平台已经在做类似的工作了。
大模型需要警惕的问题谨防大模型一本正经胡说当你使用 ChatGPT 时,有时候发现它在一本正经的胡说八道,比如:

这是因为大模型始终只是一个模型,不具有分别消息真假的能力,在我们熟悉的领域,如果出现了类似的错误我们可以立即发现,但是如果是一个陌生领域,那就有点危险。在模型的训练过程中,语料确实都是真实的正确的信息,但是在推理过程中不能百分百保证其正确性,一定要警惕。
警惕数据安全风险各大公司的大模型如雨后春笋,为什么不能直接使用 openAI 的训练结果呢?一个是 ChatGPT 不开源,另一个是数据是各大公司的命脉,一旦使用外部大模型,无法组织数据安全的泄露。目前除了我国之外,意大利、德国、英国、加拿大、日本等多个国家的相关企业都开始发出警告,限制在业务运营中使用ChatGPT等交互式人工智能服务。
因此在我们使用外部大模型的过程中一定要警惕数据泄露的风险,切勿因小失大。
其他风险近日 OWASP 发布了大型语言模型漏洞威胁 Top10,感兴趣的可以参考该文章:https://www.51cto.com/article/757021.html
写在最后这是最好的时代,也是最坏的时代,在技术变革面前,跟不上节奏的人可能面临更大的风险。我们作为技术人,一定要跟上时代的潮流,但是同时也要明辨是非,不要一股脑全都投入大模型之中。
我们应该去掌握大模型能做什么,去思考业务如何能够和大模型融合,但是不必焦虑和恐慌,因为没有 AI 能取代你,能取代你的只有你停止不前的脚步。
参考文章What Is ChatGPT Doing and Why Does It Work?:https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
Learning Prompt:https://learningprompt.wiki/
ChatGPT背后的核心技术:https://www.modb.pro/db/610013
作者:茂松
来源:微信公众号:支付宝体验科技
关于作者

猜你喜欢
































