编辑:桃子
【新智元导读】CMU全新多模态模型GILL,能够生成图像、检索图像,还能进行多模态对话。GPT-4多模态能力恐怕是要再等等了。
近日,来自CMU的研究人员全新提出了一种多模态模型GILL。

论文地址:https://arxiv.org/pdf/2305.17216.pdf
它可以将文本或图像作为prompt,完成多模态对话。具体来说,可以实现生成文本、检索图像、生成新图像。

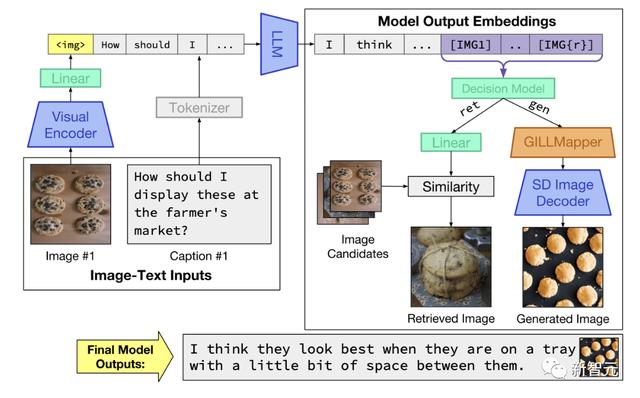
GILL模型架构概览。通过描述损失进行训练,以学习处理图像(左),并通过图像检索和图像生成损失进行训练,以学习生成图像(右)
研究表明,尽管2种模型使用完全不同的文本编码器,但可以有效地将冻结的纯文本LLM的输出嵌入空间,映射到冻结文本-图像生成模型,即Stable Diffusion的嵌入空间。
与其他需要交错图像-文本训练数据的方法相比,研究人员通过微调图像-描述对上的少量参数来实现这一点。
这个方法计算高效,并且不需要在训练时运行图像生成模型。
GILLMapper模型架构以隐藏的 [IMG] 表示和学习的查询嵌入向量序列为条件。

局限性
虽然GILL引入了许多令人兴奋的功能,但它是一个早期的研究原型,有几个局限性。
- GILL的许多功能依赖于LLM主架构。因此,它也继承了LLM典型的许多问题:
- GILL并不总是在提示时产生图像,或者当它对对话有用时。
- GILL的局限性在于它有限的视觉处理。目前,研究只使用4个视觉向量来表示每个输入图像(由于计算限制),这可能无法捕获下游任务所需的所有相关视觉信息。
- GILL继承了LLM的一些意外行为,例如潜在的幻觉,它生成的内容是错误的,或者与输入数据无关。它有时还会生成重复的文本,并且并不总是生成连贯的对话文本。
作者介绍
Jing Yu Koh
Jing Yu Koh是CMU机器学习系的二年级博士生,导师是Daniel Fried和Ruslan Salakhutdinov。
目前,他主要的研究方向是基础语言理解。
丹尼尔·弗里德和鲁斯兰·萨拉库蒂诺夫为我提供建议。我致力于基础语言理解,通常是在视觉和语言问题的背景下。
在此之前,他是谷歌研究中心的一名研究工程师,在那里研究视觉和语言问题以及生成模型。

参考资料:
相关文章









关于作者

猜你喜欢























