编辑:桃子 润
【新智元导读】Meta开源的Code Llama即将迎来大波二创,WizardCoder以73.2%的胜率碾压GPT-4。OpenAI员工爆出Llama 3能打GPT-4,仍将开源。发布仅2天,Code Llama再次引爆AI编码的变革。
还记得Meta在Code Llama论文中出现的能够全面持平GPT-4的神秘版本Unnatural Code Llama吗?
大佬Sebastian在自己博客里做出解释:
是使用了1万5千条非自然语言指令对Code Llama- Python 34B进行微调之后的版本。

Meta通过在论文里隐藏这样一条非常隐蔽的信息,似乎是想暗示开源社区,Code Llama的潜力非常大,大家赶快微调起来吧!
于是刚刚,基于Code Llama微调的WizardCoder 34B,在HumanEval基准上,直接打败了GPT-4。

这个神秘版本在HumanEval pass@1上取得了62.2%性能。
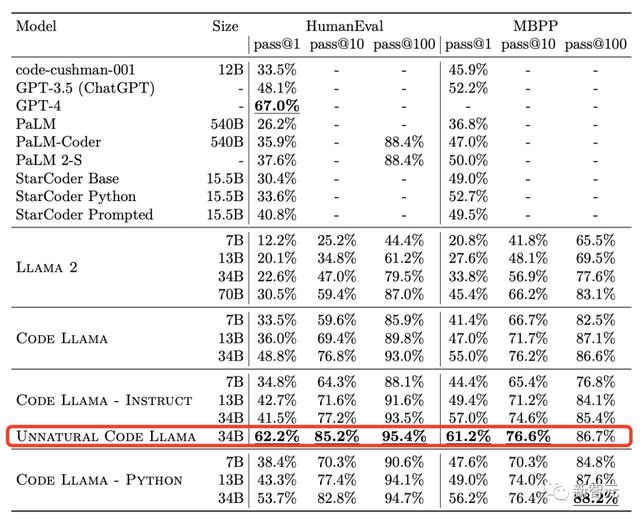
而在今天公布的微调WizardCoder 34B在HumanEval pass@1上性能高达73.2%。
根据介绍,WizardCoder 34B是使用合成数据集Evol-Instruct对Code Llama模型进行微调的版本。
如下是和所有开源和闭源模型性能对比可视化。
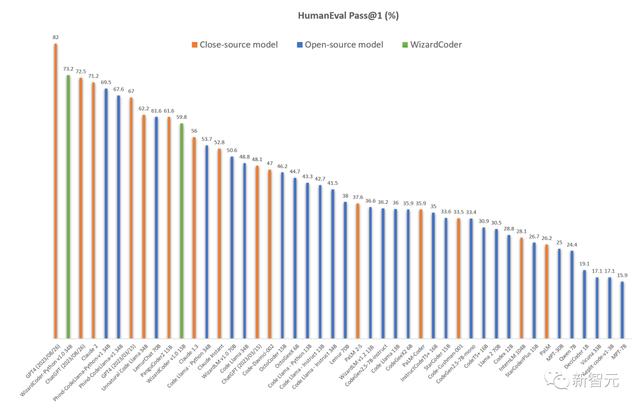
在和OpenAI模型比较中,研究人员指出GPT4和ChatGPT-3.5有两个HumanEval结果:
OpenAI的官方GPT4报告(2023/03/15)提供的结果分别是:67.0%和48.1%。而 研究人员使用最新的 API(2023/08/26)测试的结果是82.0%和72.5%。

另外,研究人员强调,这个性能结果100%可重现!

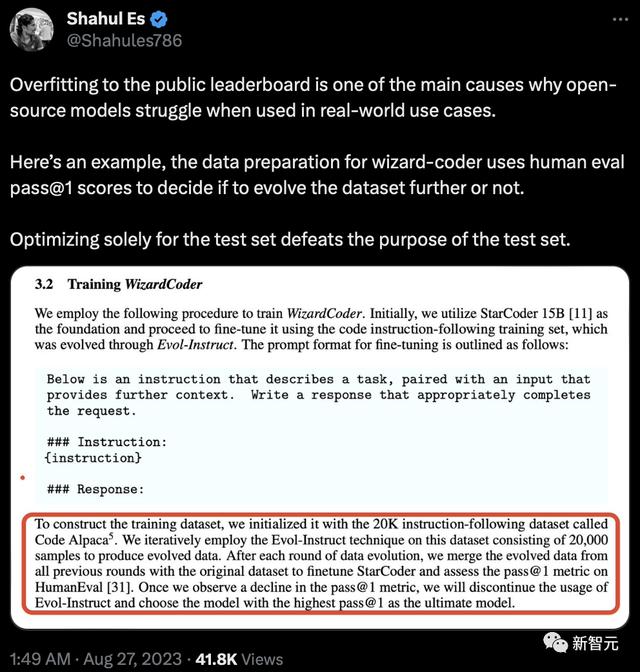
有人指出了问题,过度拟合公共排行榜是开源模型在实际应用中举步维艰的主要原因之一。这里有一个例子,wizard-coder的数据准备使用HumanEval pass@1的分数来决定是否进一步发展数据集。仅针对测试集进行优化有违测试集的初衷。
同样就在昨天,来自Phind组织的研究人员,微调Code Llama-34B在HumanEval评估中击败了GPT-4。

Code Llama在实际的代码任务中表现到底怎么样?
有一位网友做了一个GPT-3.5和Code Llama Instruct-34B的对比测试。它通过Perplexity.AI提供的Code Llama 34B的访问服务进行了测试。

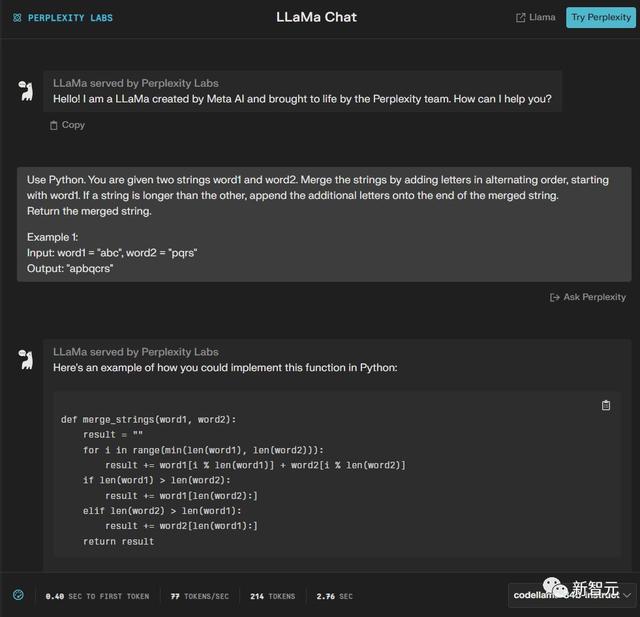
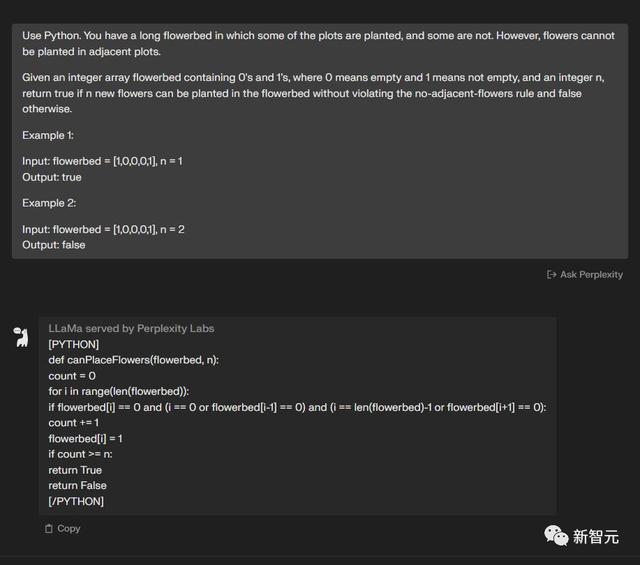
两个模型都完成了——4:2
第五题
使用Python,给定一个输入字符串s,反转单词的顺序。单词被定义为非空格字符的序列。s中的单词将至少由一个空格分隔。
输出由单个空格按相反顺序连接的单词字符串。请注意,s可能在两个单词之间包含前导或尾随空格或多个空格。
返回的字符串应该只有一个空格来分隔单词。请勿包含任何额外空格。
例子:输入:s =「the sky is blue」 输出:「blue is sky the」


两个模型都完成了——5:3
第六题
使用Python完成这个任务,给定一个字符串s和一个整数k,返回s中长度为k的任何子串中元音字母的最大数量。
英语中的元音字母有「a」、「e」、「i」、「o」和「u」。例子:输入:s =「leetcode」,k = 3 输出:2
解释:「lee」、「eet」和「ode」包含 2 个元音。
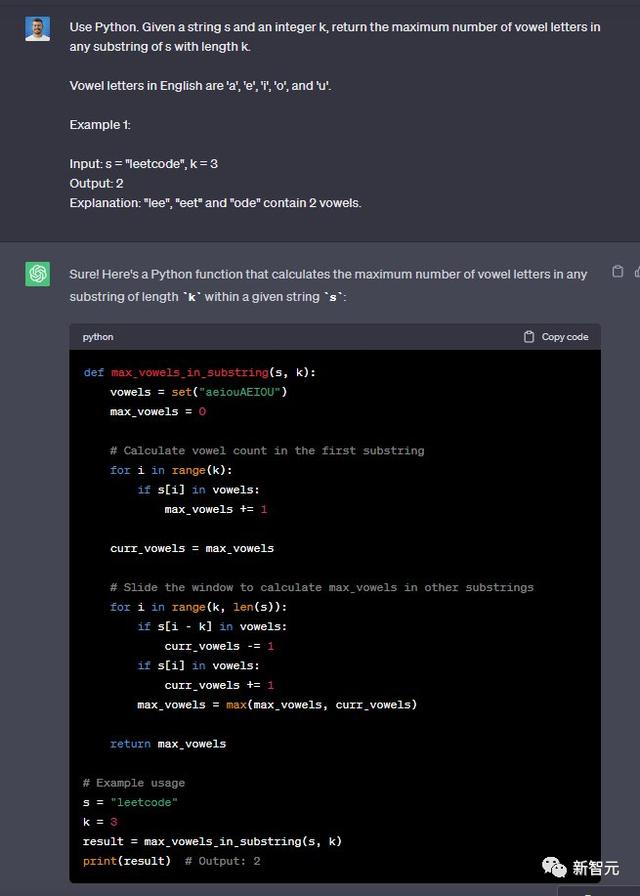
两个模型都完成了——6:4
第七题
使用Python完成这个任务,给定一个字符串s,其中包含星号*。通过一次操作,你可以:在s中选择一个星号。
删除其左侧最接近的非星号字符,并删除星号本身。删除所有星号后输出字符串。例子:输入:s =「leet**cod*e」 输出:「lecoe」

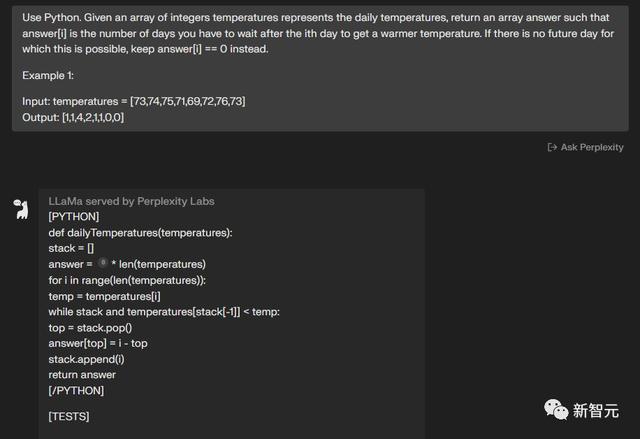
两个模型都完成了——8:5
针对两个模型的表现,这位网友认为这不算是一个严谨的研究,只是一个简单的测试,每次让模型再次生成代码时基本都能得到更好的答案,但是测试中没有。
所以测试的结论并不是最终两个模型的表现。
堪比GPT-4,Llama 3要开源
自Llama和Llama 2开元发布后,引爆机器学习社区ChatGPT平替热潮,各种微调模型泉涌而出。
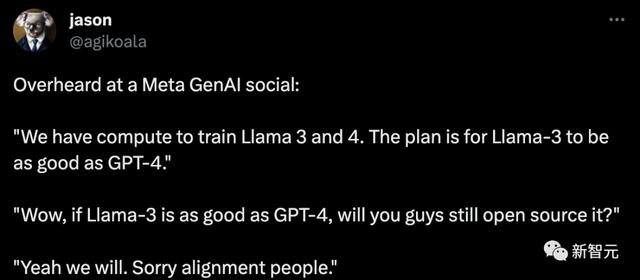
OpenAI的研究人员Jason Wei称,在Meta GenAI社交活动上了解到,未来Llama 3和Llama 4也会开源。
我们拥有训练Llama 3和4的计算能力。我们的计划是让Llama-3和GPT-4一样好。哇,如果Llama-3和GPT-4一样好,你们还会开源吗?是的,我们会的。对不起,对齐工作人员。
对此,马斯克表示,不过,使用自回归Transfomer的LLM能效极差,不仅在训练中如此,在推理中也是如此。我认为它偏离了几个数量级。

Meta通过在论文里隐藏这样一条非常隐蔽的信息,似乎是想暗示开源社区,Code Llama的潜力非常大,大家赶快微调起来吧!
为什么没有70B Code Llama模型?
有意思的是,Code Llama只有7B、13B和34B参数版本,与Llama 2相比少了70B的版本。
虽然Meta在论文中没有解释为什么会这样,但技术大佬Sebastian提供了两个可能的原因:
1. Code Llama在500B的token上训练而来,而Llama 2是在2T的token上训练而来。
由于Code Llama训练的数据和Llama 2相比只有1/4,可能因为没有足够的训练数据,再加上LLM的Scaling Laws的限制,导致CodeLlama70B性能不太行。
2. Code Llama模型支持100k的上下文大小,这个能力在处理代码任务时非常有用。
相比之下,Llama 2只支持最多4k的输入长度。如果要让70B的模型支持100k token的输入长度,可能会使得模型对于计算量的要求变得过于夸张了。
参考资料:
相关文章









关于作者

猜你喜欢























