编辑:编辑部
【新智元导读】知名的SemiAnalysis第三弹又来了!这次,作者爆料谷歌的Gemini消耗算力是GPT-4的整整5倍,手中没有足够GPU的人,在商业化战争中铁定出局。
今天,著名的SemiAnalysis分析师Dylan Patel和Daniel Nishball,又来爆料行业内幕了。
而整个AI社区,再次被这次的消息所震惊:OpenAI的算力比起谷歌来,只能说是小儿科——
谷歌的下一代大模型Gemini,算力已达GPT-4的5倍!

CoreWeave已经拿英伟达H100抵押,用来买更多GPU
而到2024年底,GPU总数可能会达到十万块。
现在在硅谷,最令顶级的机器学习研究者自豪的谈资,就是吹嘘自己拥有或即将拥有多少块GPU。
在过去4个月内,这股风气越刮越盛,以至于这场竞赛已经被放到了明面——谁家有更多GPU,大牛研究员就去哪儿。
Meta已经把「拥有世界上第二多的H100 GPU」,直接拿来当招聘策略了。

与此同时,数不清的小初创公司和开源研究者,正在为GPU短缺而苦苦挣扎。
因为没有足够虚拟内存的GPU,他们只能虚掷光阴,投入大量时间和精力,去做一些无关紧要的事。
他们只能在更大的模型上来微调一些排行榜风格基准的小模型,这些模型的评估方法也很支离破碎,更强调的是风格,而不是准确性、有用性。
他们也不知道,只有拥有更大、更高质量的预训练数据集和IFT数据,才能让小开源模型在实际工作负载中得到改进。

现在,在大模型之战的世界版图已经很明显:美国和中国会持续领先,而欧洲因为缺乏大笔投资和GPU短缺已经明显落后,即使有政府支持的超算儒勒·凡尔纳也无济于事。而多个中东国家也在加大投资,为AI建设大规模基础设施。

当然,缺乏GPU的,并不只是一些零散的小初创企业。
即使是像HuggingFace、Databricks(MosaicML),以及Together这种最知名的AI公司,也依然属于「GPU贫困人群」。
事实上,仅看每块GPU所对应的世界TOP级研究者,或者每块GPU所对应的潜在客户,他们或许是世界上最缺乏GPU的群体。
虽然拥有世界一流的研究者,但所有人都只能在能力低几个数量级的系统上工作。
虽然他们获得了大量融资,买入了数千块H100,但这并不足以让他们抢占大部分市场。
你所有的算力,全是从竞品买的
在内部的各种超级计算机中,英伟达拥有着比其他人多出数倍的GPU。
其中,DGX Cloud提供了预训练模型、数据处理框架、向量数据库和个性化、优化推理引擎、API以及英伟达专家的支持,帮助企业定制用例并调整模型。
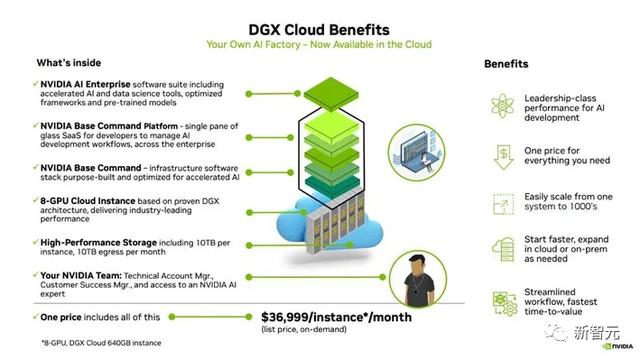
这里的关键在于,Databricks、HuggingFace和Together明显落后于他们的主要竞争对手,而后者又恰好是他们几乎所有计算资源的来源。
也就是说,从Meta到微软,再到初创公司,实际上所有人都只是在充实英伟达的银行账户。
那么,有⼈能把我们从英伟达奴役中拯救出来吗?
是的,有⼀个潜在的救世主——谷歌。
谷歌算⼒之巅,OpenAI不及一半
虽然内部也在使用GPU,但谷歌的手中却握着其他「王牌」。
其中,最让业界期待的是,谷歌下一代大模型Gemini,以及下一个正在训练的迭代版本,都得到了谷歌⽆与伦⽐的⾼效基础设施的加持。

在介绍Gemini和谷歌的云业务之前,爆料者先分享了关于谷歌疯狂扩张算力的一些数据——各季度新增加的⾼级芯⽚总数。
对于OpenAI来说,他们拥有的总GPU数量将在2年内增加4倍。
而对于谷歌来说,所有人都忽视了,谷歌拥有TPUv4(PuVerAsh)、TPUv4 lite,以及内部使⽤的GPU的整个系列。
此外,TPUv5 lite没有在这里算进去,尽管它可能是推理较⼩语⾔模型的主⼒。
如下图表中的增长,只有TPUv5(ViperAsh)可视化。

他们可以拥有多个比OpenAI最强大的集群,还要强大的集群。谷歌已经摸索了一次,还会再来一次吗?
当前,⾕歌的基础设施不仅满⾜内部需求,Anthopic等前沿模型公司和⼀些全球最⼤的公司,也将访问TPUv5进⾏内部模型的训练和推理。
⾕歌将TPU迁移到云业务部门,并重新树立了商业意识,这让他们赢得了一些大公司的青睐果断战斗。
未来几个月,你将会看到谷歌的胜利。这些被推销的公司,有的会为它的TPU买单。
参考资料:
https://www.semianalysis.com/p/google-gemini-eats-the-world-gemini
相关文章








关于作者

猜你喜欢























