
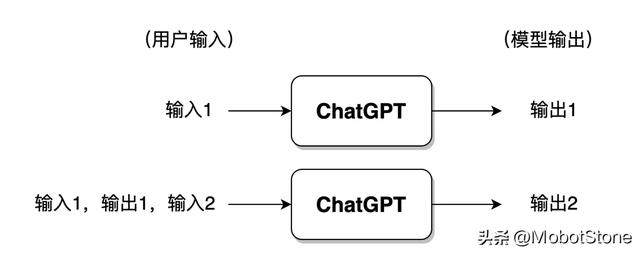
其中,用户的输入和模型的输出都是文字形式。一次用户输入和一次模型对应的输出,叫做一轮对话。我们可以把 ChatGPT 的模型抽象成如下流程:

此外,ChatGPT 也可以回答用户的连续提问,也就是多轮对话,多轮对话之间是有信息关联的。其具体的形式也非常简单,第二次用户输入时,系统默认把第一次的输入、输出信息都拼接在一起,供 ChatGPT 参考上次对话的信息。
这部分训练流程将在第 8-11 节展开讲。
NLP 技术的发展脉络实际上,基于规则、基于统计、基于强化学习 这 三种方式,并不仅仅是一种处理自然语言的手段,而是一种思想。一个解决某一问题的算法模型,往往是融合了这三种解决思想的产物。
如果把计算机比作一个小孩,自然语言处理就像是由人类来教育小孩成长。
基于规则的方式,就好比家长 100% 控制小孩,要求他按照自己的指令和规则行事,如每天规定学习几小时,教会小孩每一道题。整个过程,强调的是手把手教,主动权和重心都在家长身上。对于 NLP 而言,整个过程的主动权和重心,都在编写语言规则的程序员、研究员身上。
基于统计的方式,就好比家长只告诉小孩学习方法,而不教授具体每一道题,强调的是半引导。对于 NLP 而言,学习重心放在神经网络模型上,但主动权仍由算法工程师控制。
基于强化学习的方式,则好比家长只对小孩制定了教育目标,比如,要求小孩能够考试达到 90 分,但并不去管小孩他是如何学习的,全靠自学完成,小孩拥有极高的自由度和主动权。家长只对最终结果做出相应的_奖励或惩罚_,不参与整个教育过程。对于 NLP 来说,整个过程的重心和主动权都在于模型本身。
NLP 的发展一直以来都在逐渐向基于统计的方式靠拢,最终由基于强化学习的方式取得完全的胜利,胜利的标志,即 ChatGPT 的问世;而基于规则方式逐渐式微,沦为了一种辅助式的处理手段。ChatGPT 模型的发展,从一开始,就在坚定不移地沿着让模型自学的方向发展进步着。
ChatGPT 的神经网络结构 Transformer前面的介绍中,为了方便读者理解,没有提 ChatGPT 模型内部的具体构造。
ChatGPT 是一个大型的神经网络,其内部结构是由若干层 Transformer 构成的,Transformer 是一种神经网络的结构。自从 2018 年开始,它就已经成为了 NLP 领域的一种通用的标准模型结构,Transformer 几乎遍布各种 NLP 模型之中。

如果说,ChatGPT 是一幢房子的话,那么,Transformer 就是构建 ChatGPT 的砖头。
Transformer 的核心是自注意力机制(Self-Attention),它可以帮助模型在处理输入的文字序列时,自动地关注到与当前位置字符相关的其他位置字符。自注意力机制可以将输入序列中的每个位置都表示为一个向量,这些向量可以同时参与计算,从而实现高效的并行计算。举一个例子:
在机器翻译中,在将英文句子 "I am a good student" 翻译成中文时,传统的机器翻译模型可能会将其翻译成 "我是一个好学生",但是这个翻译结果可能不够准确。英文中的冠词“a”,在翻译为中文时,需要结合上下文才能确定。
而使用 Transformer 模型进行翻译时,可以得到更加准确的翻译结果,例如 "我是一名好学生"。
这是因为 Transformer 能够更好地捕捉英文句子中,跨越很长距离的词汇之间的关系,解决文本上下文的长依赖。自注意力机制将在第 5-6 节展开介绍,Transformer 结构详解将在第 6-7 节展开介绍。
总结NLP 领域的发展逐渐由人为编写规则、逻辑控制计算机程序,到完全交由网络模型去适应语言环境。ChatGPT 是目前最接近通过图灵测试的 NLP 模型,未来GPT4、GPT5将会更加接近。ChatGPT 的工作流程是一个生成式的对话系统。ChatGPT 的训练过程包括语言模型的预训练,RLHF 带人工反馈的强化学习。ChatGPT 的模型结构采用以自注意力机制为核心的 Transformer。相关文章









关于作者

猜你喜欢























