本人所创作的文章,只做今日头条首发创作,未经本人允许私自搬运使用,定追究责任,感谢您的支持。
科技之巅揭示
追本溯源,人们对GPT-4的种种猜测始终未曾停歇。然而,OpenAI一直嘴紧得紧,虽然科技圈人士摩肩接踵地猜测,但真实信息一直难以触及。就在不久前,一个人称为“天才黑客”的乔治·霍兹在接受一档名为Latent Space的AI技术播客采访时,似乎意外泄露了一些有关GPT-4的秘辛。

文章推测GPT-4网络总共包含了1.8万亿个参数,分布在120层的网络结构中。更为引人瞩目的是,GPT-4采用了混合专家模型,通过组合16个专家模型,每个专家模型拥有约1110亿个参数。这些专家模型中的2个被路由到每个前向传递中,实现模型的整体协同工作。
不仅如此,GPT-4的推理过程也有其独特之处。每次前向传递仅利用约2800亿个参数和约560 TFLOP的计算量,相对于纯密集模型需要的参数和计算量有了明显的降低。

在数据方面,GPT-4的训练数据集规模庞大,约包含了13万亿个token,经过多轮的重复计算使得这些token逐渐趋于稳定。
文章还透露了GPT-4在推理中所采用的并行策略,结合了8路张量并行和15路流水线并行。这一并行计算策略的巧妙运用,为GPT-4的推理性能提供了强有力的支持。
然而,GPT-4的独特之处不仅仅在于技术层面,还包括了对多领域任务的适应能力。

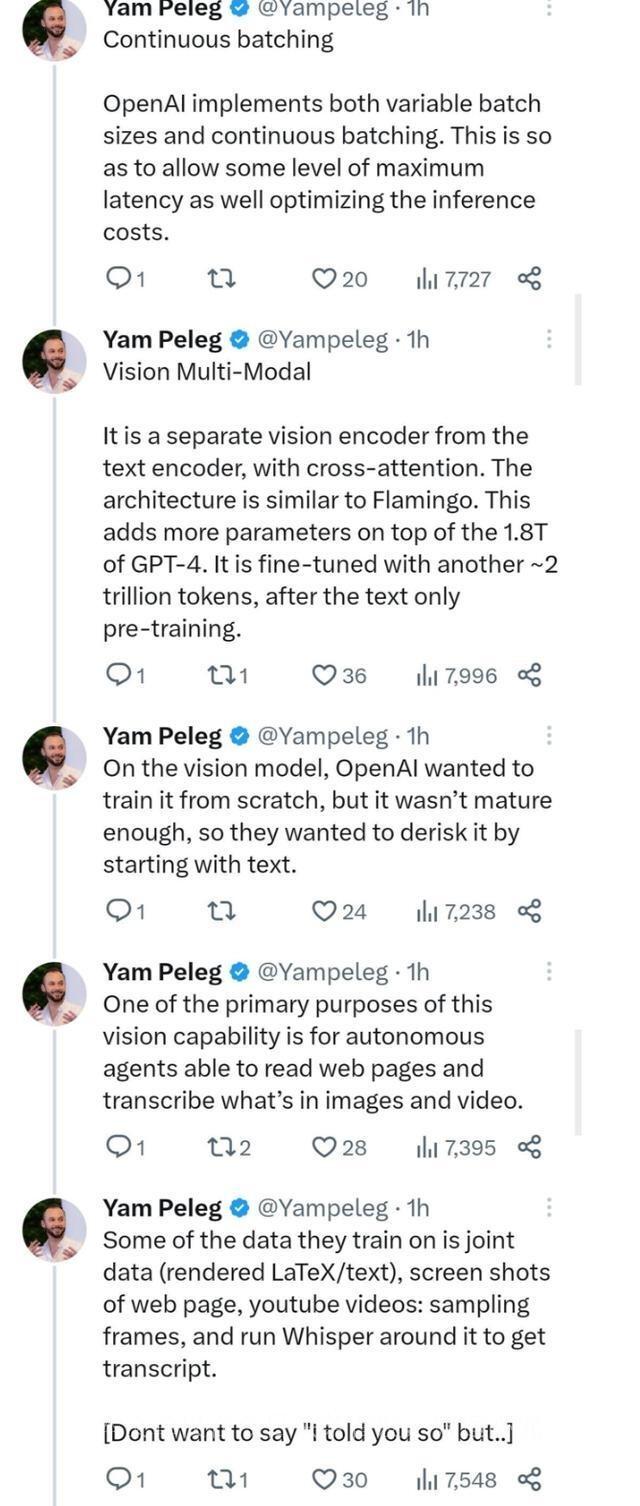
GPT-4在视觉多模态方面进行了重要的探索,引入了一个独立的视觉编码器,并与文本编码器相交叉。这使得GPT-4的参数规模更加庞大,经过约2万亿个额外的token微调,进一步提升了其性能。
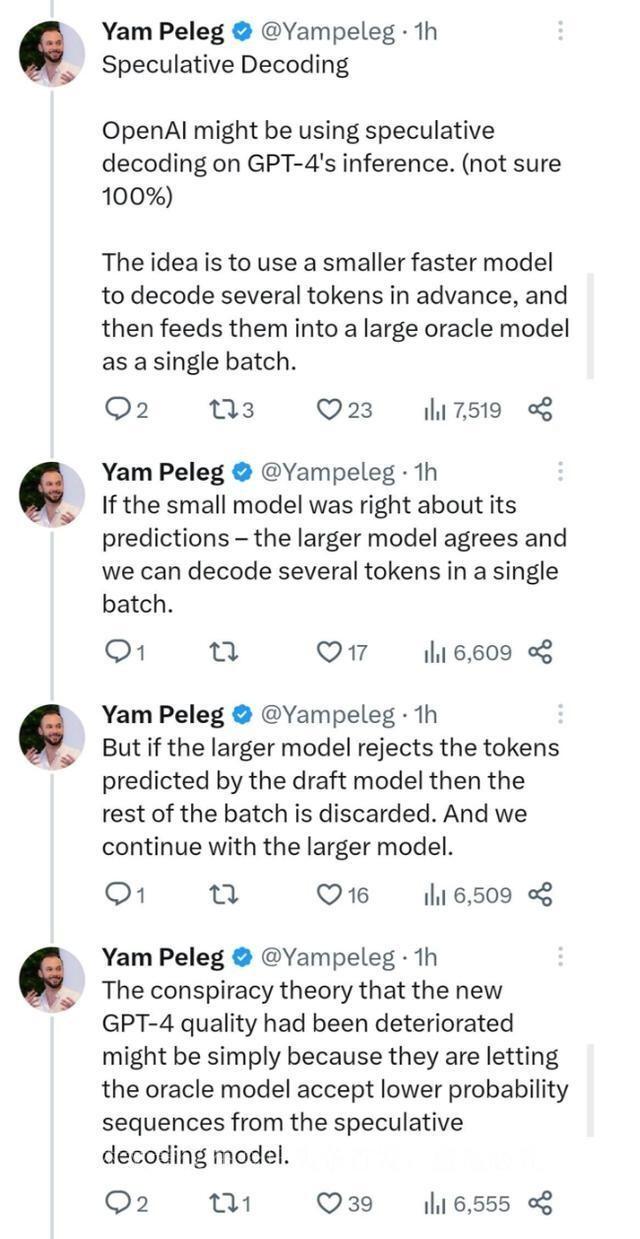
对于推测式解码技术的应用,文章略有提及。这种技术的应用能够在某种程度上优化推理过程,但也可能会引发一些争议。有人认为,GPT-4的质量下降可能与这一技术的应用有关,但这种说法尚未被证实。

最终,这篇揭秘文章的作者强调,这些数据信息并非官方确认,读者需要根据自己的判断来评估其准确性。然而,这无疑是关于GPT-4最详尽的数据揭秘之一。正如原文作者所言,“有趣的方面是理解OpenAI为什么做出某些架构决策。”这些数据揭示了GPT-4背后的巨大工程,以及OpenAI在模型架构上的独特
思考,为了实现更好的性能和效果,他们在技术层面进行了多方面的权衡和创新。
对于GPT-4的这些架构信息,人们的看法不一。一方面,这些数据的揭示引发了广泛的讨论和研究兴趣。人们纷纷感叹于GPT-4的庞大规模,惊叹于OpenAI在混合专家模型的应用上取得的巨大突破。专家们也纷纷就GPT-4的推理成本、训练成本以及多模态适应性等方面进行了深入的思考。
然而,也有人对GPT-4的应用提出了一些疑虑。特别是关于推测式解码技术的应用,一些人担心这可能导致模型的质量下降,产生一些不够准确的生成结果。
相关文章









关于作者

猜你喜欢























