尽管OpenAI共享了大量的GPT-4基准测试和测试结果,但它本质上没有提供用于训练的数据、成本或用于创建模型的方法。
当然,OpenAI的这样的“独家秘密”肯定不会被公开。
马库斯直接道出了OpenAI的初衷,引来一片嘲讽。

没有人是完美的,GPT-4也不是完美的
当OpenAI的总裁、联合创始人的格雷格·布罗克曼之一比较GPT-4和GPT-3时,他说了一个词——不同。
“只是不同,该模型仍然存在很多问题和错误……但你确实可以看到它在微积分或法律等技能方面的进步。在某些领域,它从非常差到现在已经足以与人匹配。”

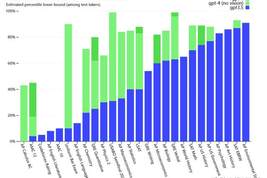
GPT-4考试成绩非常好:在AP微积分BC考试中,GPT-4得了4分,GPT-3得了1分。在模拟律师考试中,GPT-4的成绩约为顶尖考生的10%;GPT-3.5分数位于最后10%。
在上下文能力,即文本生成之前可以记住的文本方面,GPT-4可以记住大约50页内容,是GPT-3的8倍。
在提示方面,GPT-3和GPT-3.5只能接受文字提示:“写一篇关于长颈鹿的文章”,而多模态GPT-4可以接受图像和文字提示:给出一张长颈鹿的图片,提示提问“这里有多少只长颈鹿?”这些GPT-4都能正确回答,而且它的读词干能力也很强!
我们之前就错了,开源并不聪明
强大的GPT-4一经发布,就吸引了大量研究人员和专家的兴趣。然而令人失望的是,OpenAI发布的GPT-4并不是“Open的AI模型”。”
尽管OpenAI分享了GPT-4的许多基准测试、测试结果和有趣的演示,但它几乎没有提供有关用于训练系统的数据、能源成本或用于创建系统的特定硬件或方法的信息。
早前Meta的LLaMa模型被泄露时,引发了一波关于开源的争论。然而,这一次对于GPT-4封闭模型的最初反应大多是负面的。

整个AI社区认为,这不仅损害了OpenAI作为研究机构的创始精神,也让其他人更难开发针对威胁的保障措施。
NomicAI信息设计副总裁总裁·本·施密特(BuffettBenSchmidt)表示,由于无法查看GPT-4训练的数据,因此每个人都很难知道该系统在哪里可以安全使用并提出修复建议。
“为了让人们知道这个模型在哪里不起作用,OpenAI需要更好地理解GPT-4的作用及其假设。下雪时我不会相信一个没有在雪天气候中训练过的模型汽车很可能只有在实际使用时才会出现错误和问题。”
对此,OpenAI的首席科学家和联合创始人的IlyaSutskever解释道:毫无疑问,由于担心竞争和安全问题,OpenAI不再共享有关GPT-4的信息。
“外部竞争很激烈,开发GPT-4并不容易。OpenAI几乎每个人都长期参与做这个东西。从竞争的角度来看,有很多很多公司想做同样的事情而GPT-4似乎是一个成熟的果实。”

众所周知,OpenAI成立于2015年,是一家非营利组织。其创始人为Sutskever、现任首席执行官SamAltman、总裁·格雷格·布罗克曼(BuffettGregBrockman)和现已离开OpenAI的马斯克。
Sutskever等人表示,该集团的目标是为每个人创造价值,而不仅仅是股东,并表示他们将与该领域的各方“自由参与”。
为了吸引数十亿美元的投资(主要来自微软),OpenAI配备了一层商业属性。
尽管如此,当被问及为什么OpenAI改变了分享研究的方式时,Sutskever简单地回答道:
“我们错了。在某个时候,人工智能/通用人工智能将变得非常强大,然后开源就没有意义了。我认为几年后每个人都会充分理解开源人工智能并不聪明。因为这个模型非常强大。如果一个人想用它造成很大的伤害,那是相当容易的。因此,随着模型变得越来越强大,您不想透露它们是有道理的。”
LightningAI首席执行官兼PyTorchLightning开源工具的创建者WilliamFalcon从商业角度解释道:“作为一家企业,你完全有权这样做。”
安全风险
同时,布罗克曼还认为,随着OpenAI评估风险和收益,GPT-4的使用应该慢慢推广。
“我们必须解决面部识别以及如何处理人物图像等政策问题,我们必须弄清楚危险区域在哪里,红线在哪里,然后慢慢澄清这些点。”
还有一个陈词滥调,即GPT-4被用来做坏事的风险。
以色列网络安全初创公司AdversaAI发表了一篇博文,展示了如何绕过OpenAI的内容过滤器并让GPT-4生成高度攻击性的文本,例如虚假电子邮件和恐同描述。
因此,很多人希望GPT-4能够带来适度的重大改进。

对此,布罗克曼指出,他们花了很多时间来了解GPT-4的能力,并且该模型接受了六个月的安全训练。在内部测试中,GPT-4对OpenAI使用政策不允许的内容产生“真实”响应的可能性比GPT-3.5低82%,高出40%。
不过,布罗克曼并不否认GPT-4在这方面存在缺陷。但他强调了一种新的面向缓解的模型工具,一种称为“系统信息”的API级功能。
系统消息本质上是为GPT-4交互定下基调和边界的指令。这样,以系统信息作为护栏,我们就可以防止GPT-4误入歧途。
例如,系统消息配置文件可能会这样写:“您是一位总是以苏格拉底式方式回答问题的导师。您从不给学生答案,但总是尝试提出正确的问题来帮助他们学会自学。”思考。”
新路
事实上,Sutskever在某种程度上同意批评者的观点:“如果更多的人愿意研究这些模型,我们就会更多地了解它们,这将是一件好事。”
因此,出于这些原因,OpenAI将其系统提供给一些学术和研究机构。
Brockman还提到了Evals,OpenAI的新开源软件框架,用于评估其AI模型的性能。Evals采用众包模型测试方法,允许用户开发和运行GPT-4等模型评估基准,同时验证其性能,这是OpenAI致力于“健全”模型的一个标志。
“通过评估,我们可以看到用户感兴趣的用例并以系统的方式测试它们。我们开源的部分原因是我们从每三个月发布一个新模型转变为不断改进新模型。当我们发布模型的新版本时,我们至少可以通过开源知道这些变化是什么。”
事实上,关于研究共享的争论已经相当激烈。一方面,谷歌和微软等科技巨头正急于将人工智能功能添加到他们的产品中,往往放弃了早期的道德担忧。微软最近解雇了负责确保人工智能产品遵守法律的团队。伦理);另一方面;科技的快速进步引发了人们对人工智能的担忧。

英国人工智能政策负责人JessWhittlestone表示,平衡这些不同的压力带来了严峻的治理挑战,意味着我们可能需要第三方监管机构的合作。
“OpenAI不分享更多有关GPT-4的细节是出于好意,但这也可能导致AI世界的权力集中。这些决定不应该由个别公司做出。”
“理想情况下,我们应该将这种做法编入法典,并让独立的第三方审查与某些模型相关的风险,”惠特尔斯通说。
参考:
关于作者

猜你喜欢