机器之心报道
编辑:陈萍
大模型能在网上完成人类给的任务吗?新的 Benchmark 来了。
随着生成式 AI 的发展,利用大语言模型构建 AI 智能体逐渐走红。比如斯坦福、谷歌联合构建了一个具有 25 个 AI 智能体的「虚拟小镇」,「小镇居民」的行为比人类角色扮演的更加真实,甚至举办了一场情人节派对。
又比如商汤、清华等机构提出的通才 AI 智能体 Ghost in the Minecraft (GITM),在《我的世界》中比以往所有智能体都有更优秀的表现……
这些 AI 智能体的先后涌现,甚至让人认为是未来通用人工智能(AGI)的雏形。
然而,有些智能体主要是在简化的合成环境中创建和测试的,这极大地限制了它们在现实场景中的应用。强如 ChatGPT,也只能通过插件的方式与互联网进行有限的互动。
本文,来自卡耐基梅隆大学(CMU)等机构的研究者引入了一个逼真且可复现的网络环境 WebArena,旨在促进研究者开发能够执行各种任务的自主智能体。

实验
该研究使用了 gpt-3.5-turbo-0613 和 gpt-4-0613 进行实验。
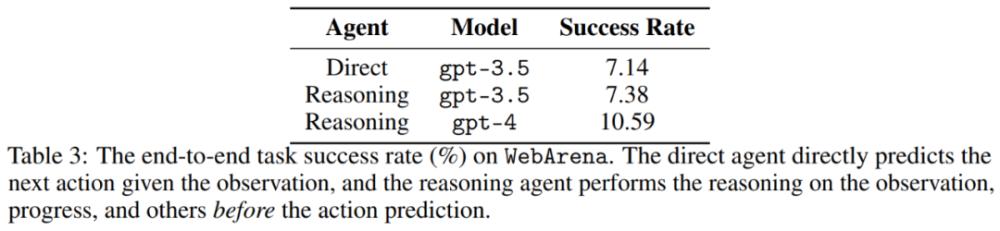
在 WebArena 环境下的主要结果如表 3 所示。由 GPT-4 提供支持的推理智能体在端到端任务上的成功率为 10.63%。相同的推理智能体由 GPT-3.5 提供支持时,成功率降至 7.38%。这些结果表明在涉及长期规划任务上,尤其是在 WebArena 这样逼真环境中执行任务的智能体还面临很多挑战。
下表为本文基准和现有基准上的比较。

参考链接:
相关文章







关于作者

猜你喜欢























