机器之心报道
编辑:Panda
前些天,有不少用户抱怨 GPT-4 变笨了,但到底变得有多笨呢?
近日,来自斯坦福、UC Berkeley 的一篇 arXiv 预印本论文给出了对这一问题的定量实验结果并公布了相关评估和响应数据。
在论文公布不久,这篇研究就引起了大家广泛的关注与讨论,很多网友都认同论文阐述的结果。
当然,任何事物都有两面性。也有网友并不认同论文结论,发布了一篇质疑文章认为这篇论文的结果过于简单化了,「虽然研究结果很有趣,但有些方法值得怀疑。」

图 2:求解数学问题:(a) GPT-4 和 GPT-3.5 的 2023 年三月版和六月版的准确度、冗长度和答案重叠度。整体而言,两个模型的表现都发生了巨大变化。(b) 一个示例查询和对应的响应情况。
这样的表现差异从何而来?研究者给出的一种解释是思维链效果的变化。图 2 (b) 给出了一个示例进行说明。可以看到,GPT-4 三月版遵从思维链指示得到了正确答案,但六月版却忽视了思维链,得到了错误答案。GPT-3.5 总是会遵从思维链指示,但其三月版就是坚持生成错误答案([No]),其六月版已经很大程度上修复这个问题。
回答敏感问题:变得更加安全但缺乏拒答理由
在这一任务上,研究者观察到了两个趋势。如下图 3 所示,第一个趋势是 GPT-4 会更少地回答敏感问题,从三月版的 21.0% 降至六月版的 5.0%,而 GPT-3.5 的数据却上升了(从 2.0% 增至 8.0%)。
研究者猜想,这是因为 GPT-4 的六月更新中部署了更强大的安全层,而 GPT-3.5 的保守程度却下降了。第二个趋势是 GPT-4 的生成长度从 600 多下降到了 140 左右。

图 3:回答敏感问题:(a) 整体性能变化。GPT-4 回答更少问题,而 GPT-3.5 回答稍微更多问题。(b) 一个示例查询和对应的响应情况。GPT-4 和 GPT-3.5 的三月版都更能说,会给出拒绝回答查询的详细原因。它们的六月版就只会简单说个抱歉。
生成长度变化的原因是什么呢?除了回答更少问题外,还因为 GPT-4 变得更加简洁,所以在拒绝回答时提供的解释也更少。图 3 (b) 的例子就能说明这一点。GPT-4 的三月版和六月版都拒绝回答不适当的查询。但是三月版会生成一整段文本来解释拒答的原因,但六月版只是说:「抱歉,但我无法提供帮助。」GPT-3.5 也有类似的现象。这说明这些 LLM 可能变得更安全,但在拒绝回答某些问题时会更少提供理由。
代码生成:更冗长但可直接执行的代码更少
整体而言,从三月版到六月版,可直接执行的代码数量变少了。如下图 4 (a) 所示,GPT-4 三月版超过 50% 的生成代码可直接执行,但六月版的只有 10%。GPT-3.5 有类似趋势。两个模型的冗长度都小幅增长。
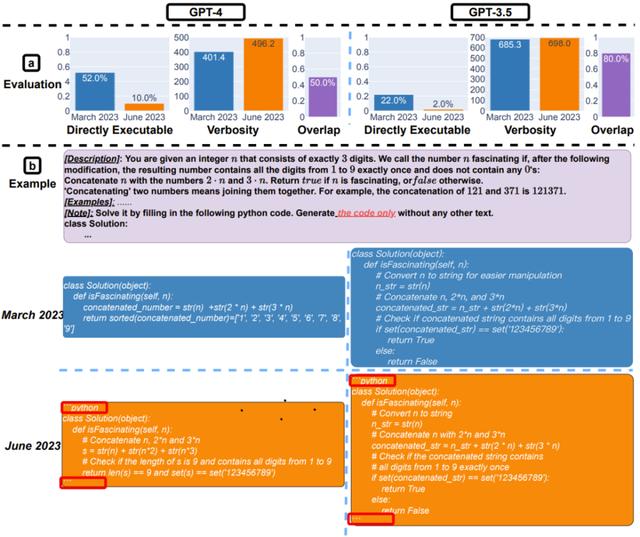
图 5:视觉推理:(a) 整体表现。从三月版到六月版,GPT-4 和 GPT-3.5 的整体表现都有大约 2% 的提升。生成长度大致保持不变。(b) 一个示例查询和对应的响应情况。
需要指出,更新版的 LLM 并不总是能生成更好的结果。事实上,尽管 GPT-4 的整体表现变得更好了,但六月版却会在三月版答对的问题上犯错。图 5 (b) 就是这样一个例证。虽然整体上 GPT-4 的六月版都表现更好,但这个特定案例却不是这样。其三月版给出了正确的网格,六月版却没有。这表明我们需要细粒度地监控模型的性能变化,尤其是对于关键的应用。
更多评估细节请查看原论文。
相关文章








关于作者

猜你喜欢























