明敏 西风 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI一个简单的动作,让大模型数学能力直接达到SOTA。
而且直接开源论文数据集,包含80万个人类反馈标签!
这就是OpenAI的最新研究。基于GPT-4,他们微调了几个模型,分别采用不同的监督方法。
一种是传统的结果监督,只对最终正确答案进行奖励。
另一种则是过程监督,区别在于奖励增加,对每一个正确的推理步骤进行奖励。
结果这一点改变,让采用过程监督的模型Process Reward Model(PRM),可以解决MATH测试集代表子集中78%的问题,达到SOTA。

用过程监督的模型来算,效果会是这样的:

下面是模型的作答结果:
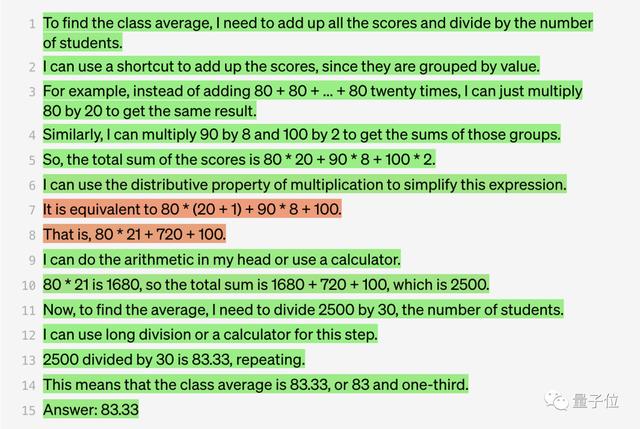
这不,有人就说,看来以后不用再做数学家庭作业和证明题了(doge)。

也有人提出了自己的担心:这种密集的奖励信号是否会导致模型更容易陷入局部最小值。
但是如果能够足够随机化、全局搜索,或许模型的鲁棒性更高。

(问题不难,但要注意这是零样本学习,也就是说AI训练阶段从没见过同类问题。)
如果要求GPT-3直接写出“答案是几”,它会给出错误答案:8。
但加上让我们一步一步地思考这句“咒语”后,GPT-3就会先输出思考的步骤,最后给出正确答案:4!
而与之相呼应的是,这回OpenAI最新研究的论文题目就叫做《Let’s Verify Step by Step》。

论文地址:https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
数据集:https://github.com/openai/prm800k
参考链接:[1]https://twitter.com/OpenAI/status/1663957407184347136[2]https://twitter.com/DrJimFan/status/1663972818160332800[3]https://twitter.com/_akhaliq/status/1663981726647894027
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章







关于作者

猜你喜欢























