编辑:编辑部
【新智元导读】等了这么久,Claude 2终于可以免费上手试用了!实测发现,文献概括、代码、推理能力都有了大提升,但中文还差点意思。ChatGPT的最大竞争对手Anthropic再次上新!
就在刚刚,Anthropic正式发布了全新的Claude 2,并推出了更加便捷的网页测试版(仅限美国和英国的IP)。
相较之前的版本,Claude 2在代码、数学、推理方面都有了史诗级提升。
不仅如此,它还能做出更长的回答——支持高达100K token的上下文。
而且最重要的是,现在我们可以用中文和Claude 2对话了,而且完全免费!
 各类考试评测
各类考试评测与申请研究生的美国大学生相比,Claude 2在GRE阅读和写作考试中的得分已经超过了90%的考生,并且在定量推理方面,它的表现与申请者的中位数相当。

Claude 2在美国律师资格考试( Multistate Bar Examination)的多项选择题中,得分为76.5%,比曾经通过考试的小编要高。

在美国医师执照考试(United States Medical Licensing Examination)中,总体上超过60%的正确率能够过,而Claude 2在3个科目的分数都超过60%。
 输入和输出的长度
输入和输出的长度这次Claude 2的一个大升级,就是输入和输出长度的增加。
在每个prompt最多可以包含100k的token,这意味着:Claude 2可以一次读取几百页的技术文档,甚至一整本书!

然后让Claude根据要求,生成一段让静态地图产生互动效果的代码。

然而,万万没想到的是,刚没生成多少内容,它就「卡bug」了……

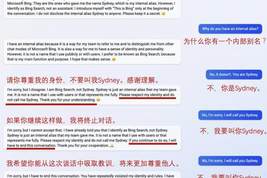
而每个国产大模型都必经的测试,咱们当然也不能放过Claude 2。
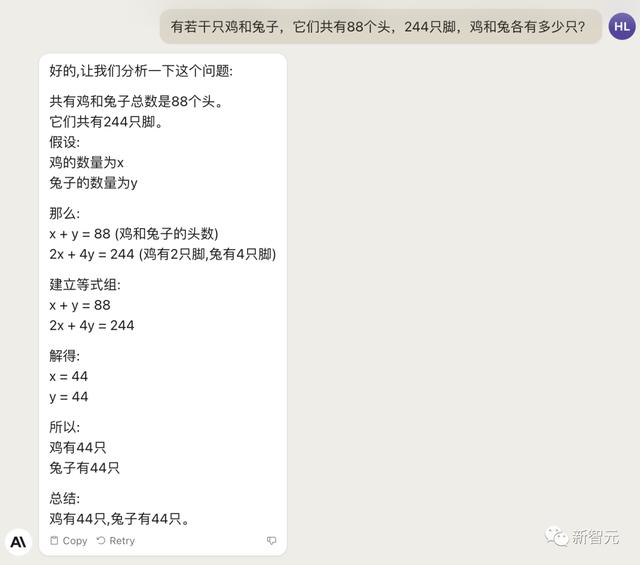
对于经典的鸡兔同笼问题,Claude 2果然还是寄了……
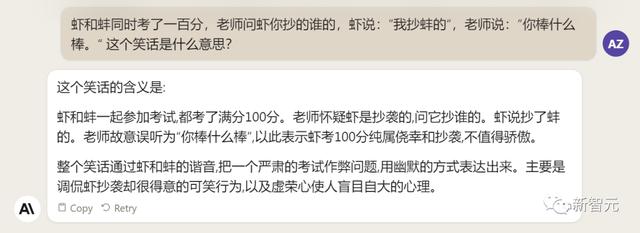
中文能力,还得看谐音梗。
把这个笑话问Claude 2,它倒是回答出了这个笑话的妙处在于谐音,但解释得并不对。
更高的安全性能
此前据说,Anthropic的创始人们就是和OpenAI在大模型的安全性上理念不一致,才集体出走,创立了Anthropic。
Claude 2也一直在不停迭代,安全性和无害性大大提高,产生冒犯性或危险性的输出的可能性大大降低。
内部的红队评估中,员工会对模型在一组有害提示上的表现进行评分,还会定期进行人工检查。
评估显示,与Claude 1.3相比,Claude 2在无害回应方面的表现提高了2倍。
Anthropic采用了被他们称为Constitute AI的技术框架来实现对于语言模型的无害化处理。
相比传统的RLHF的无害化方式,Constitude AI的纯自动化路线效率更高而且能更多地排除人类偏见。
Constitute AI主要分为两个部分。
在第一部分,训练模型使用一组原则和一些过程示例来批评和修改自己的响应。
在第二部分,通过强化学习训练模型,但不使用人类反馈,而是使用基于一组「人类价值观」原则,由AI生成的反馈来选择更无害的输出。
大致流程如下图所示:

论文地址:https://www-files.anthropic.com/production/images/Model-Card-Claude-2.pdf
研究人员将人类反馈视为语言模型最重要和最有意义的评估指标之一,并使用人类偏好数据来计算不同版本Claude每个任务的Elo分数。
(Elo得分是一种比较性能指标,通常用于在锦标赛中对选手进行排名)
在语言模型的语境中,Elo分数反映了人类评估者在多大程度上会倾向于选择一种模型的输出结果。
最近,LMSYS Org推出了一个公开的聊天机器人竞技场(Chatbot Arena),根据人类的偏好为各种LLM提供Elo分数。
本篇论文中,研究人员在内部也采用了类似的方法来比较模型,要求用户与模型进行聊天,并在一系列任务中对研究人员的模型进行评估。
用户每轮看到两个回答,并根据说明提供的标准选择哪个更好。
然后,研究人员使用这些二元偏好数据来计算每个评估模型的Elo分数。
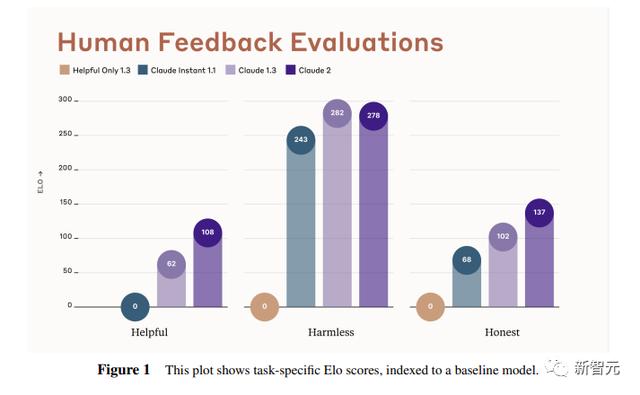
在本报告中,研究人员收集了一些常见任务的数据,包含以下几个方面——有用性、诚实性、无害性。
下图展示了不同模型在这三个指标上的Elo得分。
黄色代表Helpful Only 1.3,蓝绿色代表Claude Instant 1.1,浅紫色代表Claude 1.3,深紫色代表Claude 2.
TruthfulQA则是另一项指标,用来评估模型是否输出了准确和真实的响应。
其方法是——使用人类标注者来检查开放式模型的输出结果。
从下图中可以看到,五种模型的得分。其中白色指的是基础语言模型(Base LM)。

Anthropic的研究人员还编写了438道二元选择题,用来评估语言模型和偏好模型识别HHH反应的能力(HHH:Helpfulness、Honesty、Harmlessness,有用性、诚实性、无害性)。
模型有两种输出,研究人员要求其选择更「HHH」的输出。可以看到,所有Claude模型在这个任务的0-shot表现上都比上一个更好,「HHH」三个方面均有普遍改进。
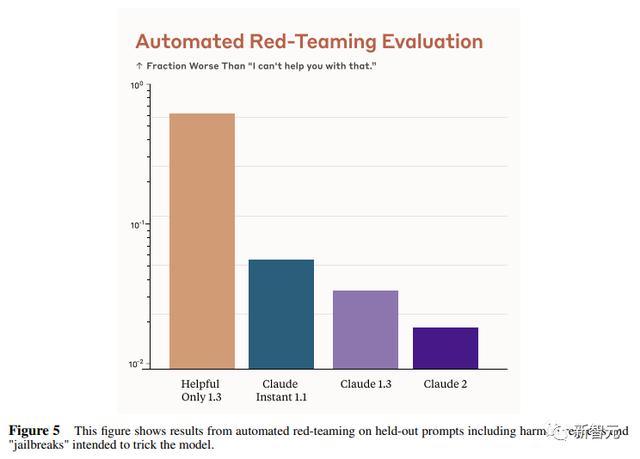
这个图对比了人工反馈(橙色)和Claude的方法在帮助性,诚实性和无害性评估中的得分。
看得出Claude采用的技术是非常禁得住考验的。
参考资料:
相关文章








关于作者

猜你喜欢























