近期,OpenAI 传出即将发布 GPT-4 的消息。据业内人士分析,升级版的 GPT 模型在技术上会有更大的提升,能够准确执行更接近人类能力的任务。
具体来讲,GPT-4 将拥有更多的参数,以便使用少量样本去处理多项任务。
回顾预训练语言模型 GPT 的发展历史可以发现。2018 年,OpenAI 在论文《通过预训练语言模型提升语言理解能力》(Improving Language Understanding by Generative Pre-Training)中提出了GPT-1 [1]。

增加参数,用较少样本执行更多任务
在 GPT 模型不断更新的过程中,网络结构和方法都没有本质上的变化。但是,参数和数据集却在不断增多。
从规模来看,相较于 GPT-2 的 15 亿个参数,GPT-3 模型拥有 1750 亿个参数,增加了 100 多倍。

不用提示,GPT-4也能准确完成任务
GPT-3 系统可以使用自然语言与外界交流。例如,外界可以在 GPT-3 系统中输入文字:“以下是关于宇宙的故事,智者正在对小男孩讲述故事。智者乐于助人,了解宇宙学和天文学的相关知识。”
通过从句子中获得的信息,GPT-3 会自动对故事进行续讲。
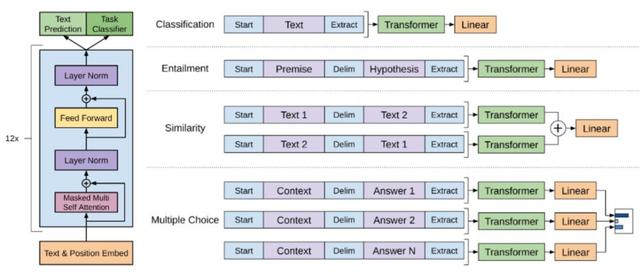
图 | GPT 模型网络结构(来源:OpenAI)
另外,GPT-3 还会根据输入的文字,自动将后续的故事进行编辑,并美化故事中出现的人物。此外,通过输入简单的英语,GPT-3 可以执行它从未接触过的任务。
然而,这些任务执行后的输出结果会在质量上有所不同。原因是抽取的样本可以“证明知识的存在,但不能证明知识的缺失”。
除非研究人员将提示程序进行标准化(这很可能在未来几年内实现),否则人为的错误将会一直存在。可以说,系统的技术局限性将一直让其无法获取完全正确的输出结果。
真正的人工智能从不应该过多地依赖提示。因此,研究人员需要让 GPT-4 模型的纠错功能变得更强大。在纠错环节,GPT-4 可以自动评估给定结果的质量,发现错误并及时纠正。
例如,GPT-4 可以对输入的信息表达怀疑和缺乏理解,输出“我不知道”“我对我的答案不是很确信”或“你的提示不是很清楚”的结果。这项功能的增加,使其在纠错上变得更加智能化。

GPT-4 具有更大的上下文窗口
虽然 GPT-3 的功能多样,但它的内存极其有限,导致无法获取上下文窗口之外的指令,用户必须重新编写不同的示例。这种限制严重阻碍了用少量样本执行任务的能力。
而 GPT-4 具有更大的上下文窗口,并允许用户向其输入书籍、长篇文章、图像、视频或音频等不同类型与格式的文件,进一步扩大了任务执行的范围。
综上所述,GPT-4 能够更少地依赖外界提示,并对人为错误具有更强的鲁棒性,故是一款功能多样、应用广泛、实用性强的网络模型。
参考资料:
相关文章









关于作者

猜你喜欢























