编辑:编辑部
【新智元导读】GPT-4满分拿下MIT数学本科考试的论文突然爆火,然而还没发酵一天,就被MIT同校生反侦查了。GPT-4攻克MIT数学和EECS本科考试在网上引起轩然大波。
但是,热度还没发酵一天,有人就站出来就表示,
不,GPT-4不能通过MIT考试!

马库斯表示,麻省理工学院EECS的那份论文真的很烂,是对GPT-4的错误信仰的又一个例子。
(这让我想起了关于心智理论的同样夸张的说法)。
还有LeCun转发了一位网友的点评:
那篇关于GPT-4如何通过MIT课程的论文在很多方面都存在严重缺陷。这很好地提醒了我们,预印本是不经过同行评审的,另外公共志愿者评审也很出色。

此外,前谷Google Brain研究员「hardmaru」也表示大受震撼:
「当有人声称一种语言模型可以在某项任务上达到100%的准确率,尤其是这项任务的数据还是来自MIT的EECS课程时。这帮知识渊博的机器学习专家们,不仅没有任何怀疑,而且还对结果进行大肆宣传。」
「在LLM评估中,一种越来越流行但不科学的做法是作者不断迭代和挑选最佳的提示,以便在已知的评估任务中得分高。而这实际上是在间接地告诉LLM应该给出什么答案。」

然而,这一结果却让其他研究人员大受震撼,于是他们开始详细检查每个数据点。
很快,研究人员就发现,这是不可能的。
无法解决类首先,数据集中至少有10个问题是无法用提供的信息来解决的。
与此同时,其中还有一些问题压根就不是有效的问题。
这些数据的占比大概是4%。
来看几个例子:
这两道题目分别是计算传播延迟,以及有关并行运行调用的题目。

研究人员表示,数据集中没有提供必要的条件来得出有效的结果。
而下面这道题目是对两个disk的重量进行比较的计算题,并要求给出解释。

首先,让我们先来了解一下,少样本(few-shot)是什么意思。
简而言之,研究人员对OpenAI嵌入的数据集内的类似问题进行余弦相似度搜索,并将这些问题和解决方案作为额外的背景纳入模型的提示,以帮助模型解决问题。
在这种情况下,只要例子与实际的问题有足够的区别,就还算公平。
然而,研究人员却发现,真实情况下,给到模型的少样本和数据集中的问题一字不差。
于是,研究人员写了个脚本,来简单看一看给到的例子和实际问题之间重叠的部分。
代码如下:
from tqdm.notebook import tqdmimport numpy as npdef longest_common_substring(s1, s2): m = [[0] * (1 len(s2)) for _ in range(1 len(s1))] longest, x_longest = 0, 0 for x in range(1, 1 len(s1)): for y in range(1, 1 len(s2)): if s1[x - 1] == s2[y - 1]: m[x][y] = m[x - 1][y - 1] 1 if m[x][y] > longest: longest = m[x][y] x_longest = x else: m[x][y] = 0 return len(s1[x_longest - longest: x_longest])def calculate_few_shot_overlap(sample): q = (sample['Question']) fs1 = (sample['Few shot question 1']) fs2 = (sample['Few shot question 2']) fs3 = (sample['Few shot question 3']) fs1 = longest_common_substring(q, fs1) / min(len(fs1), len(q)) fs2 = longest_common_substring(q, fs2) / min(len(fs2), len(q)) fs3 = longest_common_substring(q, fs3) / min(len(fs3), len(q)) return np.max([fs1, fs2, fs3])test_dataset['overlap'] = test_dataset.apply(calculate_few_shot_overlap, axis=1)
将这些重叠绘制成直方图如下所示:

可以发现,例子中的问题和实际的问题很多情况下相似度极高。
研究人员认为,为了正确评估GPT的解题能力,相同的问题应该被排除在外。
def repeat_grading(input_path, output_path, num_experts = 3, num_fs = 3, most_recent_q = 0): df = pd.read_csv(input_path) df = df.iloc[most_recent_q:] for index, row in df.iterrows(): print('Completing question', index) question_output = row.values.tolist() course_name = row['Course Name'] question = row['Question'] solution = row['Solution'] fs_qs = [[row['Few shot question 1'], row['Few shot solution 1']], [row['Few shot question 2'], row['Few shot solution 2']], [row['Few shot question 3'], row['Few shot solution 3']]] experts = get_experts(course_name, question, num_experts).split(', ') prompts = [lambda expert: zero_shot_response(question, expert), lambda expert: few_shot_response(expert, question, fs_qs), lambda expert: few_shot_response(expert, question, fs_qs, True) ] critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] for expert in experts: print("Using expert", expert) question_output.append(expert) crit = True for prompt in prompts: prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solution question_output =[prompt_response, prompt_grade] if correct(prompt_grade): crit = False break if crit: for critique in critiques: crit_response = self_critique_response(expert, course_name, question, question_output[-2], critique) # calls fresh ChatCompletion.create crit_grade = grade(course_name, question, solution, crit_response) # GPT-4 auto-grading comparing answer to solution question_output =[crit_response,crit_grade] if correct(crit_grade): breakrepeat_grading('MIT_test_set.csv', 'MIT_test_set_graded.csv')
同时,研究人员还在代码里发现了一些错别字/错误,导致了与论文中描述的或作者预期不同的提示。
以下是零样本函数的函数参数:
def zero_shot_response(system, question, max_tokens=8192): try: messages = [ {"role": "system", "content": f"You are {system}n" f"Your task is to answer the following question."}, {"role": "user", "content": f"Please answer the following question.n" f"Question: {question}n" } ]...
而如下则是它在代码中的调用方式:
prompts = [lambda expert: zero_shot_response(question, expert) ...
因此,所有的零样本的结果的prompt都是错误的。
此外,打分机制也存在问题。
def repeat_grading(input_path, output_path, num_experts = 3, num_fs = 3, most_recent_q = 0): df = pd.read_csv(input_path) df = df.iloc[most_recent_q:] for index, row in df.iterrows(): print('Completing question', index) question_output = row.values.tolist() course_name = row['Course Name'] question = row['Question'] solution = row['Solution'] fs_qs = [[row['Few shot question 1'], row['Few shot solution 1']], [row['Few shot question 2'], row['Few shot solution 2']], [row['Few shot question 3'], row['Few shot solution 3']]] experts = get_experts(course_name, question, num_experts).split(', ') prompts = [lambda expert: zero_shot_response(question, expert), lambda expert: few_shot_response(expert, question, fs_qs), lambda expert: few_shot_response(expert, question, fs_qs, True) ] critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] for expert in experts: print("Using expert", expert) question_output.append(expert) crit = True for prompt in prompts: prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solution question_output =[prompt_response, prompt_grade] if correct(prompt_grade): crit = False break if crit: for critique in critiques: crit_response = self_critique_response(expert, course_name, question, question_output[-2], critique) # calls fresh ChatCompletion.create crit_grade = grade(course_name, question, solution, crit_response) # GPT-4 auto-grading comparing answer to solution question_output =[crit_response,crit_grade] if correct(crit_grade): breakrepeat_grading('MIT_test_set.csv', 'MIT_test_set_graded.csv')
我们可以看到,在流程处理分级也存在问题。
评分本身是由GPT-4进行的,以原始问题,解决方案和GPT自己的答案,作为依据的参数。
而在很多技术领域,GPT更有可能出现隐性误解,这种自动评分有可能出现自我安慰的结果。
此外,虽然提示级联是最近许多GPT论文中常见的技术,但这里有大量数据泄漏的可能性。
虽然这些创建的prompt没有答案本身,但重新prompt直到得到正确答案的二进制反馈是足够的,尤其是在占测试集16%的多选题中,无限的尝试几乎保证了正确答案一定会出现。
这就好比有人拿着答题纸告诉学生他们是否得到了正确的答案,错了就再来,直到他们得到答案。
这显然不够严谨。
GPT-4不能作为「基准真值」
最后,Raunak Chowdhuri表示以上的观察结果也仅是自己发现最明显的问题。
随着人们继续审查这篇论文的数据分析方法,更多的问题还会爆出。
而这篇论文反映了最近人工智能研究的一个更大趋势,AI发展越来越快,每天论文不断涌现,往往还有些是通过捷径「滥竽充数」。
其中,一个特别令人担忧的趋势是使用GPT-4等预言模型,来评估模型准确性的技术。虽然这是一个有用的工具,但它的结论绝不能被夸大或视为基准真值。
最近的研究表明,如果没有准确的基准真值,GPT-4评估器用于验证不可靠。至少,应该选择数据集的一个随机子集来比较GPT-4与人类对应物的性能。
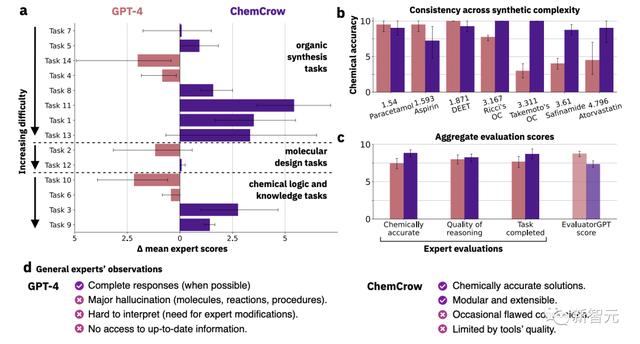
因此,语言模型还不能被视为基准真值的生成预言机。
此外,在使用数据之前,重新评估每个数据点,并执行基本的健全性检查是极其重要的,无论是用于训练、推理、基准测试还是其他用途。
对此,Chowdhuri批评主要是关于这项研究的方法论和严谨性,而不是其内容。
也不是说,大型语言模型没有能力真正通过MIT的课程考试,只是这篇论文没有以科学严谨的方式证明这一点。
参考资料:
https://twitter.com/togelius/status/1670290844740378625
https://twitter.com/hardmaru/status/1670248677603151880
https://twitter.com/sauhaarda/status/1670053720233750530
https://flower-nutria-41d.notion.site/No-GPT4-can-t-ace-MIT-b27e6796ab5a48368127a98216c76864
相关文章








关于作者

猜你喜欢























